2024. 12. 18. 23:16ㆍLLM(Large Language Model)의 기초
1. 캐글
* 캐글(Kaggle)은 데이터 과학자와 머신러닝 엔지니어들이 학습, 협업, 경쟁할 수 있는 온라인 플랫폼입니다.
* 구글에 소속된 이 플랫폼은 다양한 데이터셋과 머신러닝 문제를 제공하며, 사용자들이 자신의 모델을 개발하고 성능을 경쟁적으로 평가받을 수 있는 경진대회도 열립니다.
* 초보자는 데이터를 다루는 실습을 하고, 경험 많은 전문가들은 포트폴리오를 확장하거나 상금을 받을 기회를 얻을 수 있습니다.
* 또한, 커뮤니티 포럼과 튜토리얼, 노트북 공유를 통해 지식을 공유하고 학습할 수 있는 환경을 제공합니다.
* 캐글은 데이터 분석과 머신러닝을 배우고 실제 문제에 적용해 보고 싶은 사람들에게 유용한 플랫폼입니다.
>
공식 사이트 : https://www.kaggle.com/
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
예시 1)
캐글에 있는 데이터를 다운로드 받아온 파일을 구글 드라이브에 붙혀주고 돌려준다.
import pandas as pd
retail = pd.read_csv('/content/drive/MyDrive/KDT 시즌 4/10. 데이터분석/Data/online_retail_II.csv')
retail-->

예시 2)
retail.info() # 데이터프레임의 구조, 각 열의 데이터 타입, 결측치 여부, 메모리 사용량 등을 확인할 때 유용
-->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1067371 entries, 0 to 1067370
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Invoice 1067371 non-null object
1 StockCode 1067371 non-null object
2 Description 1062989 non-null object
3 Quantity 1067371 non-null int64
4 InvoiceDate 1067371 non-null object
5 Price 1067371 non-null float64
6 Customer ID 824364 non-null float64
7 Country 1067371 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 65.1+ MB
예시 3)
'''
InvoiceNo: 주문 번호
StockCode: 상품 코드
Description: 상품 설명
Quantity: 주문 수량
InvoiceDate: 주문 날짜
Price: 상품 가격
Customer ID: 고객 아이디
Country: 고객 거주지역(국가)
'''
retail.columns
-->
Index(['Invoice', 'StockCode', 'Description', 'Quantity', 'InvoiceDate',
'Price', 'Customer ID', 'Country'],
dtype='object')
예시 4)
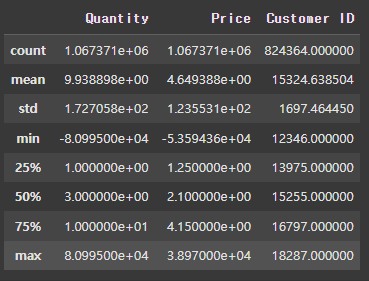
retail.describe() # 수치형 열에 대해 기본 통계 요약을 제공-->
예시 5)
len(retail) # 행 개수를 빠르게 확인할 수 있는 유용한 함수
-->
1067371
예시 6)
# 각 컬럼당 null이 몇 개 있는지 확인
retail.isnull().sum()-->

예시 7)
# 각 컬럼당 null이 얼마나 있는지 비율 확인
# 불리언 값에서 True는 1, False는 0으로 간주되어 평균을 계산
retail.isnull().mean()-->

예시 8)
# 비회원/탈퇴/휴면회원 제거
#'Customer ID'가 없는 비회원, 탈퇴 회원, 휴면 회원의 데이터를 제거.
# 'Customer ID'가 결측치가 아닌 행만 남은 데이터프레임
retail = retail[pd.notnull(retail['Customer ID'])]
retail-->

예시 9)
# 구입 수량이 0 이하인 데이터를 확인
retail[retail['Quantity'] <= 0]-->

예시 10)
# 구입 수량이 1개 이상인 데이터만 저장
retail = retail[retail['Quantity'] >= 1]
len(retail)
-->
805620
예시 11)
# 구입 가격이 0이하인 데이터를 확인
retail[retail['Price'] <= 0]-->

예시 12)
# 구입 가격이 0보다 큰 데이터만 저장
retail = retail[retail['Price'] > 0]
len(retail)
-->
805549
예시 13)
# 고객의 총 지출비용(CheckoutPrice) 파생변수 만들기
# 총 지출비용(CheckoutPrice) = 가격(UnitPrice) * 수량(Quantity)
# A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead 경고가 발생할 수 있음
# 전체 행(:)에 대해 'CheckoutPrice' 열에 값을 할당한다는 의미
# 각 행의 단가와 수량을 곱하여 총 지출 비용을 계산
retail.loc[:, 'CheckoutPrice'] = retail['Price'] * retail['Quantity']
retail-->

예시 14)
retail.info()
-->
<class 'pandas.core.frame.DataFrame'>
Index: 805549 entries, 0 to 1067370
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Invoice 805549 non-null object
1 StockCode 805549 non-null object
2 Description 805549 non-null object
3 Quantity 805549 non-null int64
4 InvoiceDate 805549 non-null object
5 Price 805549 non-null float64
6 Customer ID 805549 non-null float64
7 Country 805549 non-null object
8 CheckoutPrice 805549 non-null float64
dtypes: float64(3), int64(1), object(5)
memory usage: 61.5+ MB
예시 15)
# 날짜 문자열을 datetime 형식으로 변환
# 데이터프레임의 데이터 타입과 요약 정보를 확인
retail['InvoiceDate'] = pd.to_datetime(retail['InvoiceDate'])
retail.info()
-->
<class 'pandas.core.frame.DataFrame'>
Index: 805549 entries, 0 to 1067370
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Invoice 805549 non-null object
1 StockCode 805549 non-null object
2 Description 805549 non-null object
3 Quantity 805549 non-null int64
4 InvoiceDate 805549 non-null datetime64[ns]
5 Price 805549 non-null float64
6 Customer ID 805549 non-null float64
7 Country 805549 non-null object
8 CheckoutPrice 805549 non-null float64
dtypes: datetime64[ns](1), float64(3), int64(1), object(4)
memory usage: 61.5+ MB
예제 16)
# 전체 매출
total_revenue = retail['CheckoutPrice'].sum()
total_revenue
-->
17743429.178000003
예제 17)
# 각 나라별 구매 횟수
pd.options.display.max_rows = 50
retail['Country'].value_counts()
# retail.groupby('country')['Quantity'].count()-->

예제 18)
# 국가별 매출
# groupby('Country')는 'Country' 열을 기준으로 데이터를 그룹화
# ['CheckoutPrice'].sum()은 각 그룹에 대해 'CheckoutPrice' 열의 값을 합산
# sort_values()는 매출 합계를 기준으로 오름차순으로 정렬
rev_by_countries = retail.groupby('Country')['CheckoutPrice'].sum().sort_values()
rev_by_countries-->

예제 19)
import matplotlib.pyplot as plt
# matplotlib 객체 생성
#fig: 전체 그래프가 그려질 Figure 객체 (도화지 역할).
#ax: 실제 그래프가 그려질 Axes 객체 (그래프의 영역).
# 그래프를 그릴 축(ax)과 그림(fig)을 생성
fig, ax = plt.subplots(figsize=(20, 10)) # 너비 20인치, 높이 10인치로 그래프 크기를 지정
# 막대 그래프 그리기
ax.bar(rev_by_countries.index, rev_by_countries.values) #국가 이름을 X축, 매출을 Y축으로 막대 그래프
# 라벨 설정
ax.set_xlabel('Country', fontsize=12) # X축 라벨 설정
ax.set_ylabel('Revenue', fontsize=12) # y축 라벨 설정
ax.set_title('Revenue By Country', fontsize=15) # 그래프 제목 설정
# x축 눈금 라벨 회전
ax.set_xticks(range(len(rev_by_countries.index))) # X축 눈금의 위치를 설정
ax.set_xticklabels(rev_by_countries.index, rotation=45) # X축 눈금에 국가 이름을 할당하고, 45도 회전
# 그래프 출력
# 그래프와 텍스트가 잘리지 않고 보기 좋게 배치되도록 자동으로 여백을 조정하는 유용한 함수
plt.tight_layout() # 그래프와 텍스트가 겹치지 않도록 여백을 자동으로 조정
plt.show()-->

예제 20)
rev_by_countries / total_revenue # 각 국가의 매출을 전체 매출로 나눈 값으로, 각 국가의 매출 비율을 계산-->

예제 21)
# 월별 매출 구하기
# retail 데이터프레임의 'InvoiceDate' 열을 선택후 날짜 데이터를 내림차순으로 정렬
retail['InvoiceDate'].sort_values(ascending=False)-->

예제 22)
# 날짜에서 연도와 월을 추출하여 'YYYYMM' 형태의 문자열로 변환
# 월이 한 자리 숫자일 경우, 앞에 0을 붙여 두 자리로 만들어줌
def extract_month(date):
month = str(date.month) # 날짜에서 월(month)을 문자열로 변환하여 저장
if date.month < 10: # 월이 10보다 작으면 (예: 1월, 2월 등) 앞에 '0'을 붙여 두 자리 숫자로 만듦
month = '0' + month
return str(date.year) + month # 연도(year)와 월(month)을 합쳐 'YYYYMM' 형식으로 반환-->

예제 23)
# 'InvoiceDate' 열을 인덱스로 설정하고, extract_month 함수를 사용해 월별로 그룹화한 뒤 'CheckoutPrice'의 합계를 구함
rev_by_month = retail.set_index('InvoiceDate').groupby(extract_month)['CheckoutPrice'].sum()
rev_by_month-->

예제 24)
import matplotlib.pyplot as plt
# 막대 그래프를 그리는 함수 정의
def plot_bar(df, xlabel, ylabel, title, figsize=(20, 10), fontsize=12, titlesize=15, rotation=45):
fig, ax = plt.subplots(figsize=figsize) # 그래프를 그릴 Figure와 Axes 객체 생성, figsize로 그래프 크기 설정
ax.bar(df.index, df.values) # 막대 그래프 그리기 (df의 인덱스를 X축, df의 값을 Y축으로 사용)
ax.set_xlabel(xlabel, fontsize=fontsize) # X축 라벨 설정
ax.set_ylabel(ylabel, fontsize=fontsize) # Y축 라벨 설정
ax.set_title(title, fontsize=titlesize) # 그래프 제목 설정
ax.set_xticks(range(len(df.index))) # X축 눈금의 위치를 설정 (df의 인덱스 개수에 맞게)
ax.set_xticklabels(df.index, rotation=rotation, fontsize=fontsize) # X축 눈금 라벨을 설정하고, 라벨을 rotation 각도로 회전
plt.tight_layout() # 그래프와 텍스트가 겹치지 않도록 여백 자동 조정
plt.show()
plot_bar(rev_by_month, 'Month', 'Revenue', 'Revenue By Month')-->

예제 25)
# 요일별 매출 구하기
def extract_dow(date): # datetime 형식의 날짜
return date.dayofweek # 속성은 날짜의 요일을 숫자(정수)로 반환 예)0:월요일
# 'InvoiceDate'를 인덱스로 설정하고, 요일(dayofweek)을 기준으로 그룹화한 후 'CheckoutPrice' 합계를 계산
rev_by_dow = retail.set_index('InvoiceDate').groupby(lambda date: date.dayofweek)['CheckoutPrice'].sum()
rev_by_dow-->

예시 26)
import numpy as np
DAY_OF_WEEK = np.array(['Mon', 'Tue', 'Wed', 'Thur', 'Fri', 'Sat', 'Sun']) # 요일 이름을 담은 NumPy 배열 생성
rev_by_dow.index = DAY_OF_WEEK[rev_by_dow.index] # 'rev_by_dow'의 인덱스를 숫자에서 요일 이름으로 변경
rev_by_dow.index
plot_bar(rev_by_dow, 'DOW', 'Revenue', 'Revenue By DOW') # 막대 그래프를 그리는 함수 'plot_bar'를 사용해 요일별 매출 시각화-->

예시 27)
#시간대별 매출 구하기
rev_by_hour = retail.set_index('InvoiceDate').groupby(lambda date: date.hour)['CheckoutPrice'].sum()
rev_by_hour-->

예시 28)
plot_bar(rev_by_hour, 'Hour', 'Revenue', 'Revenu By Hour') #보류-->

'LLM(Large Language Model)의 기초' 카테고리의 다른 글
| 5. 상권_데이터셋 (6) | 2024.12.19 |
|---|---|
| Matplotlib (4) | 2024.12.19 |
| 판다스(Pandas) 2 (4) | 2024.12.18 |
| 1. 판다스(Pandas) (2) | 2024.12.17 |
| 9. 넘파이(Numpy) (0) | 2024.12.16 |