2025. 1. 24. 08:35ㆍ자연어 처리/자연어 처리
1. IMDB Dataset
* IMDB Dataset of 50K Movie Reviews는 영화 리뷰 50,000개로 구성된 대규모 텍스트 데이터셋으로, 리뷰의 감정(긍정적 또는 부정적)이 라벨링되어 있어 감정 분석(Sentiment Analysis) 연구 및 모델 학습에 자주 사용됩니다. * 이 데이터셋은 25,000개의 학습 데이터와 25,000개의 테스트 데이터로 균등하게 나뉘어 있으며, 각 리뷰는 영어로 작성되어 있습니다.
* 리뷰는 텍스트 길이가 다양하며, 자연어 처리(NLP) 알고리즘의 성능 평가 및 감정 분석 기술 향상을 위한 표준 데이터셋으로 널리 활용됩니다.
* 링크 주소 : https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
IMDB Dataset of 50K Movie Reviews
Large Movie Review Dataset
www.kaggle.com
예시 1)
import pandas as pd # pandas: 데이터 분석 및 처리 라이브러리 (DataFrame 구조 제공)
import numpy as np # numpy: 수치 연산 및 배열 계산 라이브러리
import matplotlib.pyplot as plt # matplotlib.pyplot: 데이터 시각화 라이브러리
import nltk # nltk: 자연어 처리(NLP)를 위한 라이브러리
import torch # torch: 딥러닝을 위한 PyTorch 프레임워크
import urllib.request # urllib.request: URL에서 데이터를 다운로드하기 위한 모듈
from tqdm import tqdm # tqdm: 반복 작업의 진행 상황(progress bar)을 표시
from collections import Counter # Counter: 데이터의 항목 빈도수를 계산하는 클래스
from nltk.tokenize import word_tokenize # nltk의 단어 토큰화 함수
from sklearn.model_selection import train_test_split # Scikit-learn의 데이터셋 분할 함수
nltk.download('punkt') # NLTK에서 'punkt' 데이터 다운로드
nltk.download('punkt_tab') # 'punkt_tab'은 punkt 데이터의 내부 구성요소를 포함
예시 2)
# 위의 링크의 csv 파일을 첨부해서 로그로 확인
# /content/drive/MyDrive/KDT 시즌 4/12. 자연어 처리/data/IMDB Dataset.csv
df = pd.read_csv('/content/drive/MyDrive/KDT 시즌 4/12. 자연어 처리/data/IMDB Dataset.csv')
df--->

예시 3)
# df.info()는 데이터프레임의 전반적인 정보를 요약하여 보여줍니다.
df.info()
--->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 review 50000 non-null object
1 sentiment 50000 non-null object
dtypes: object(2)
memory usage: 781.4+ KB
예시 4)
print('결측값 여부: ', df.isnull().values.any())
# 이 코드는 데이터프레임(df)에 결측값이 있는지 여부를 확인하고 True 또는 False로 반환합니다.
--->
결측값 여부: False
# 상세 설명:
# 1. df.isnull(): 데이터프레임의 각 요소가 결측값(NaN)인지 여부를 확인하여 Boolean 값(True/False)으로 구성된 동일 크기의 데이터프레임을 반환합니다.
# - True: 해당 위치에 결측값(NaN)이 존재함.
# - False: 해당 위치에 결측값이 없음.
#
# 2. .values: 데이터프레임의 데이터를 넘파이 배열(Numpy Array)로 변환합니다.
# - 판다스 데이터프레임을 넘파이 배열처럼 사용할 수 있습니다.
#
# 3. .any(): 배열 안에 하나라도 True가 있는지 확인합니다.
# - True: 결측값(NaN)이 최소 하나라도 존재함.
# - False: 결측값(NaN)이 전혀 없음.
예시 5)
# 상세 설명:
# 1. df['sentiment']: 데이터프레임에서 'sentiment'라는 열(Column)을 선택합니다.
# - 이 열에는 감정 분석 결과(예: 'positive', 'negative', 'neutral') 또는 범주형 데이터가 포함되어 있을 수 있습니다.
#
# 2. .value_counts(): 해당 열의 고유값과 각 값의 빈도를 계산하여 반환합니다.
# - 기본적으로 결과는 내림차순으로 정렬됩니다(빈도가 높은 값이 위에 표시).
# 이 코드는 데이터프레임(df)의 'sentiment' 열에 있는 각 고유값의 개수를 세고, 내림차순으로 반환합니다.
df['sentiment'].value_counts()
-->
sentiment count
positive 25000
negative 25000
예시 6)
# 1. df.groupby('sentiment'): 'sentiment' 열의 고유값별로 데이터를 그룹화합니다.
# - 예: 'positive', 'negative', 'neutral'로 데이터를 묶음.
# 2. .size(): 각 그룹의 모든 요소 개수를 셉니다.
# - 결측값(NaN)도 포함하여 계산합니다.
# 3. .reset_index(name='count'):
# - 그룹화 결과를 데이터프레임 형식으로 변환합니다.
# - 새로운 열 이름으로 'count'를 지정합니다.
# size(): 결측값을 포함하여 그룹 내 모든 요소의 개수를 셉니다.
# count(): 결측값을 제외하고 그룹 내 요소의 개수를 셉니다.
print(df.groupby('sentiment').size().reset_index(name='count'))
--->
sentiment count
0 negative 25000
1 positive 25000
예시 7)
# positive 1 , negative 0 으로 변경
df['sentiment'] = df['sentiment'].replace(['positive', 'negative'], [1, 0])
df.head()
-->
review sentiment
0 One of the other reviewers has mentioned that ... 1
1 A wonderful little production. <br /><br />The... 1
2 I thought this was a wonderful way to spend ti... 1
3 Basically there's a family where a little boy ... 0
4 Petter Mattei's "Love in the Time of Money" is... 1
예시 8)
x_data = df['review'] # x_data는 'review' 열로 정의
y_data = df['sentiment'] # y_data는 'sentiment' 열로 정의
# 데이터의 크기를 출력
print('영화 리뷰의 개수: {}'.format(len(x_data))) # x_data(영화 리뷰)의 개수를 출력
print('레이블의 개수: {}'.format(len(y_data))) # y_data(레이블)의 개수를 출력 / 각 리뷰에 대한 감정(label)
-->
영화 리뷰의 개수: 50000
레이블의 개수: 50000
예시 9)
# 데이터를 분할할 때 타겟 데이터(y_data)의 클래스 비율을 유지
# positive와 negative가 각각 50%라면, 학습 데이터와 테스트 데이터에서도 이 비율이 유지됨
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.5, random_state=2025, stratify=y_data)
--->
--------학습 데이터의 비율-----------
긍정 리뷰 = 50.0%
부정 리뷰 = 50.0%
--------테스트 데이터의 비율-----------
긍정 리뷰 = 50.0%
부정 리뷰 = 50.0%
예시 10)
x_train[30286] # x_train의 30286의 글
-->
this has by far been one of the most beautiful portraits of a person that I've ever seen on screen. Andy Goldsworthy is a kind of man that is upon extinction. he views the earth and nature with such admiration and respect that it's primitive in a good sense. his purity, honesty and kindness breathes clearly as you watch him work in such simplistic yet full of life momentary pieces of art. I was amazed how patiently he created his pieces and how patiently he accepted their end. sometimes prematurely, but his Scottish sense of humor covers his disappointments brilliantly. the film is shoot elegantly and contains the same flow that Goldsworthy's art has. it combines nature and art in a minimal way as it is in itself. Fred Frith's score is organic enough that it blends everything together without interfering with it naturalistic sound. this is overall a great piece of work in every aspect. it has no boundaries as far as age goes.
예시 11)
# - word_tokenize를 사용하려면 NLTK 라이브러리가 설치되어 있어야 함
# 문자열을 단어 단위로 나누어 토큰화한다
from nltk.tokenize import word_tokenize # nltk의 word_tokenize 함수 사용
sample = word_tokenize(x_train[0]) # x_train의 첫 번째 리뷰를 단어 단위로 나누어 리스트 형태로 반환
print(sample)
--->
['One', 'of', 'the', 'other', 'reviewers', 'has', 'mentioned', 'that', 'after', 'watching', 'just', '1', 'Oz', 'episode', 'you', "'ll", 'be', 'hooked', '.', 'They', 'are', 'right', ',', 'as', 'this', 'is', 'exactly', 'what', 'happened', 'with', 'me.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'The', 'first', 'thing', 'that', 'struck', 'me', 'about', 'Oz', 'was', 'its', 'brutality', 'and', 'unflinching', 'scenes', 'of', 'violence', ',', 'which', 'set', 'in', 'right', 'from', 'the', 'word', 'GO', '.', 'Trust', 'me', ',', 'this', 'is', 'not', 'a', 'show', 'for', 'the', 'faint', 'hearted', 'or', 'timid', '.', 'This', 'show', 'pulls', 'no', 'punches', 'with', 'regards', 'to', 'drugs', ',', 'sex', 'or', 'violence', '.', 'Its', 'is', 'hardcore', ',', 'in', 'the', 'classic', 'use', 'of', 'the', 'word.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'It', 'is', 'called', 'OZ', 'as', 'that', 'is', 'the', 'nickname', 'given', 'to', 'the', 'Oswald', 'Maximum', 'Security', 'State', 'Penitentary', '.', 'It', 'focuses', 'mainly', 'on', 'Emerald', 'City', ',', 'an', 'experimental', 'section', 'of', 'the', 'prison', 'where', 'all', 'the', 'cells', 'have', 'glass', 'fronts', 'and', 'face', 'inwards', ',', 'so', 'privacy', 'is', 'not', 'high', 'on', 'the', 'agenda', '.', 'Em', 'City', 'is', 'home', 'to', 'many', '..', 'Aryans', ',', 'Muslims', ',', 'gangstas', ',', 'Latinos', ',', 'Christians', ',', 'Italians', ',', 'Irish', 'and', 'more', '....', 'so', 'scuffles', ',', 'death', 'stares', ',', 'dodgy', 'dealings', 'and', 'shady', 'agreements', 'are', 'never', 'far', 'away.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'I', 'would', 'say', 'the', 'main', 'appeal', 'of', 'the', 'show', 'is', 'due', 'to', 'the', 'fact', 'that', 'it', 'goes', 'where', 'other', 'shows', 'would', "n't", 'dare', '.', 'Forget', 'pretty', 'pictures', 'painted', 'for', 'mainstream', 'audiences', ',', 'forget', 'charm', ',', 'forget', 'romance', '...', 'OZ', 'does', "n't", 'mess', 'around', '.', 'The', 'first', 'episode', 'I', 'ever', 'saw', 'struck', 'me', 'as', 'so', 'nasty', 'it', 'was', 'surreal', ',', 'I', 'could', "n't", 'say', 'I', 'was', 'ready', 'for', 'it', ',', 'but', 'as', 'I', 'watched', 'more', ',', 'I', 'developed', 'a', 'taste', 'for', 'Oz', ',', 'and', 'got', 'accustomed', 'to', 'the', 'high', 'levels', 'of', 'graphic', 'violence', '.', 'Not', 'just', 'violence', ',', 'but', 'injustice', '(', 'crooked', 'guards', 'who', "'ll", 'be', 'sold', 'out', 'for', 'a', 'nickel', ',', 'inmates', 'who', "'ll", 'kill', 'on', 'order', 'and', 'get', 'away', 'with', 'it', ',', 'well', 'mannered', ',', 'middle', 'class', 'inmates', 'being', 'turned', 'into', 'prison', 'bitches', 'due', 'to', 'their', 'lack', 'of', 'street', 'skills', 'or', 'prison', 'experience', ')', 'Watching', 'Oz', ',', 'you', 'may', 'become', 'comfortable', 'with', 'what', 'is', 'uncomfortable', 'viewing', '....', 'thats', 'if', 'you', 'can', 'get', 'in', 'touch', 'with', 'your', 'darker', 'side', '.']
예시 12)
# 토큰화된 단어 리스트를 모두 소문자로 변환(정규화)
lower_sample = [word.lower() for word in sample] # 리스트 내 모든 단어를 소문자로 변환
print(lower_sample)
--->
['one', 'of', 'the', 'other', 'reviewers', 'has', 'mentioned', 'that', 'after', 'watching', 'just', '1', 'oz', 'episode', 'you', "'ll", 'be', 'hooked', '.', 'they', 'are', 'right', ',', 'as', 'this', 'is', 'exactly', 'what', 'happened', 'with', 'me.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'the', 'first', 'thing', 'that', 'struck', 'me', 'about', 'oz', 'was', 'its', 'brutality', 'and', 'unflinching', 'scenes', 'of', 'violence', ',', 'which', 'set', 'in', 'right', 'from', 'the', 'word', 'go', '.', 'trust', 'me', ',', 'this', 'is', 'not', 'a', 'show', 'for', 'the', 'faint', 'hearted', 'or', 'timid', '.', 'this', 'show', 'pulls', 'no', 'punches', 'with', 'regards', 'to', 'drugs', ',', 'sex', 'or', 'violence', '.', 'its', 'is', 'hardcore', ',', 'in', 'the', 'classic', 'use', 'of', 'the', 'word.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'it', 'is', 'called', 'oz', 'as', 'that', 'is', 'the', 'nickname', 'given', 'to', 'the', 'oswald', 'maximum', 'security', 'state', 'penitentary', '.', 'it', 'focuses', 'mainly', 'on', 'emerald', 'city', ',', 'an', 'experimental', 'section', 'of', 'the', 'prison', 'where', 'all', 'the', 'cells', 'have', 'glass', 'fronts', 'and', 'face', 'inwards', ',', 'so', 'privacy', 'is', 'not', 'high', 'on', 'the', 'agenda', '.', 'em', 'city', 'is', 'home', 'to', 'many', '..', 'aryans', ',', 'muslims', ',', 'gangstas', ',', 'latinos', ',', 'christians', ',', 'italians', ',', 'irish', 'and', 'more', '....', 'so', 'scuffles', ',', 'death', 'stares', ',', 'dodgy', 'dealings', 'and', 'shady', 'agreements', 'are', 'never', 'far', 'away.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'i', 'would', 'say', 'the', 'main', 'appeal', 'of', 'the', 'show', 'is', 'due', 'to', 'the', 'fact', 'that', 'it', 'goes', 'where', 'other', 'shows', 'would', "n't", 'dare', '.', 'forget', 'pretty', 'pictures', 'painted', 'for', 'mainstream', 'audiences', ',', 'forget', 'charm', ',', 'forget', 'romance', '...', 'oz', 'does', "n't", 'mess', 'around', '.', 'the', 'first', 'episode', 'i', 'ever', 'saw', 'struck', 'me', 'as', 'so', 'nasty', 'it', 'was', 'surreal', ',', 'i', 'could', "n't", 'say', 'i', 'was', 'ready', 'for', 'it', ',', 'but', 'as', 'i', 'watched', 'more', ',', 'i', 'developed', 'a', 'taste', 'for', 'oz', ',', 'and', 'got', 'accustomed', 'to', 'the', 'high', 'levels', 'of', 'graphic', 'violence', '.', 'not', 'just', 'violence', ',', 'but', 'injustice', '(', 'crooked', 'guards', 'who', "'ll", 'be', 'sold', 'out', 'for', 'a', 'nickel', ',', 'inmates', 'who', "'ll", 'kill', 'on', 'order', 'and', 'get', 'away', 'with', 'it', ',', 'well', 'mannered', ',', 'middle', 'class', 'inmates', 'being', 'turned', 'into', 'prison', 'bitches', 'due', 'to', 'their', 'lack', 'of', 'street', 'skills', 'or', 'prison', 'experience', ')', 'watching', 'oz', ',', 'you', 'may', 'become', 'comfortable', 'with', 'what', 'is', 'uncomfortable', 'viewing', '....', 'thats', 'if', 'you', 'can', 'get', 'in', 'touch', 'with', 'your', 'darker', 'side', '.']
예시 13)
def tokenize(sentences):
tokenized_sentences = [] # 결과를 저장할 리스트
for sent in tqdm(sentences): # tqdm을 사용해 진행 상태를 시각적으로 표시
tokenized_sent = word_tokenize(sent) # 각 문장을 단어 단위로 토큰화
tokenized_sent = [word.lower() for word in tokenized_sent] # 소문자로 변환
tokenized_sentences.append(tokenized_sent) # 변환된 문장을 결과 리스트에 추가
return tokenized_sentences # 토큰화된 문장 리스트 반환
예시 14)
# 학습 데이터와 테스트 데이터를 토큰화하여 소문자로 변환
tokenized_x_train = tokenize(x_train) # 25000개의 학습 데이터(x_train)를 토큰화 및 소문자로 변환
tokenized_x_test = tokenize(x_test) # 25000개의 테스트 데이터(x_test)를 토큰화 및 소문자로 변환
--->
100%|██████████| 25000/25000 [01:09<00:00, 361.21it/s]
100%|██████████| 25000/25000 [01:02<00:00, 399.25it/s]
예시 15)
# 상위 샘플 2개 출력
for sent in tokenized_x_train[:2]:
print(sent)
-->
['this', 'has', 'by', 'far', 'been', 'one', 'of', 'the', 'most', 'beautiful', 'portraits', 'of', 'a', 'person', 'that', 'i', "'ve", 'ever', 'seen', 'on', 'screen', '.', 'andy', 'goldsworthy', 'is', 'a', 'kind', 'of', 'man', 'that', 'is', 'upon', 'extinction', '.', 'he', 'views', 'the', 'earth', 'and', 'nature', 'with', 'such', 'admiration', 'and', 'respect', 'that', 'it', "'s", 'primitive', 'in', 'a', 'good', 'sense', '.', 'his', 'purity', ',', 'honesty', 'and', 'kindness', 'breathes', 'clearly', 'as', 'you', 'watch', 'him', 'work', 'in', 'such', 'simplistic', 'yet', 'full', 'of', 'life', 'momentary', 'pieces', 'of', 'art', '.', 'i', 'was', 'amazed', 'how', 'patiently', 'he', 'created', 'his', 'pieces', 'and', 'how', 'patiently', 'he', 'accepted', 'their', 'end', '.', 'sometimes', 'prematurely', ',', 'but', 'his', 'scottish', 'sense', 'of', 'humor', 'covers', 'his', 'disappointments', 'brilliantly', '.', 'the', 'film', 'is', 'shoot', 'elegantly', 'and', 'contains', 'the', 'same', 'flow', 'that', 'goldsworthy', "'s", 'art', 'has', '.', 'it', 'combines', 'nature', 'and', 'art', 'in', 'a', 'minimal', 'way', 'as', 'it', 'is', 'in', 'itself', '.', 'fred', 'frith', "'s", 'score', 'is', 'organic', 'enough', 'that', 'it', 'blends', 'everything', 'together', 'without', 'interfering', 'with', 'it', 'naturalistic', 'sound', '.', 'this', 'is', 'overall', 'a', 'great', 'piece', 'of', 'work', 'in', 'every', 'aspect', '.', 'it', 'has', 'no', 'boundaries', 'as', 'far', 'as', 'age', 'goes', '.']
['when', 'the', 'film', 'started', 'i', 'got', 'the', 'feeling', 'this', 'was', 'going', 'to', 'be', 'something', 'special', '.', 'the', 'acting', 'and', 'camera', 'work', 'were', 'undoubtedly', 'good', '.', 'i', 'also', 'liked', 'the', 'characters', 'and', 'could', 'have', 'grown', 'to', 'empathise', 'with', 'them', '.', 'the', 'film', 'had', 'a', 'good', 'atmosphere', 'and', 'there', 'was', 'a', 'hint', 'of', 'fantasy.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'however', ',', 'as', 'the', 'film', 'went', 'on', ',', 'the', 'plot', 'never', 'appeared', 'to', 'takeoff', 'and', 'just', 'rolled', 'on', 'scene', 'by', 'scene', '.', 'i', 'was', 'unable', 'to', 'understand', 'the', 'connection', 'between', 'the', 'stories', '.', 'all', 'i', 'could', 'see', 'was', 'the', 'characters', 'occasionally', 'bumping', 'into', 'each', 'other', 'and', 'references', 'to', 'ships', 'in', 'bottles', '.', 'without', 'that', 'connection', ',', 'i', 'was', 'just', 'left', 'with', 'a', 'few', 'unremarkable', 'short', 'stories.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'am', 'surprised', 'it', 'did', 'so', 'well', 'at', 'cannes']
예시 16)
from collections import Counter
# 학습 데이터의 모든 단어를 저장할 리스트
word_list = []
# 토큰화된 학습 데이터에서 단어를 추출하여 word_list에 추가
for sent in tokenized_x_train:
for word in sent:
word_list.append(word)
# 단어의 빈도수를 계산
word_counts = Counter(word_list)
# 총 고유 단어 수를 출력
print('총 단어수 :', len(word_counts)) # 동일한 단어는 한 번만 카운트됩니다.
--->
총 단어수 : 113389
# 3. `len(word_counts)`:
# - 고유 단어의 총 개수를 계산합니다.
# - 동일한 단어는 한 번만 카운트됩니다.
Counter
* Counter는 Python의 표준 라이브러리인 collections 모듈에서 제공되는 클래스입니다. 리스트, 튜플, 문자열 등 이터러블(iterable) 객체에서 요소의 개수를 쉽게 셀 수 있도록 도와줍니다.
* 각 요소를 키(key)로, 요소의 개수를 값(value)으로 저장합니다.
* 데이터를 순회하면서 요소의 개수를 자동으로 집계합니다.
예시 1)
word_counts #각 단어당 갯수 출력
-->
#일부 출력
'batch': 15,
'french': 795,
'fries': 7,
'amazing': 1271,
'considering': 524,
'features': 665,
'extensive': 50,
'copped': 6,
'three': 2202,
'easier': 127,
'much.': 86,
'outline': 50,
'fascinated': 80,
'staged': 111,
예시 2)
word_counts['succession'] # succession의 단어 수 출력
-->
35
예제 3)
print('학습 데이터에서의 단어 the의 등장 횟수 :', word_counts['the'])
print('학습 데이터에서의 단어 love의 등장 횟수 :', word_counts['love'])
-->
학습 데이터에서의 단어 the의 등장 횟수 : 331319
학습 데이터에서의 단어 love의 등장 횟수 : 6280
2. Vocabulary
* vocabulary(단어 사전)는 모델이 처리할 수 있도록 사전에 정의된 단어들의 집합을 말합니다.
* 데이터셋에 등장하는 모든 단어들 중에서 고유한 단어들을 추출하여 구성되며, 각 단어는 고유한 인덱스나 벡터로 매핑됩니다.
* 일반적으로 빈도가 낮은 단어는 제외하고, 등장 빈도 순으로 정렬된 후 크기를 제한해 효율적으로 관리합니다.
* 예를 들어, 텍스트 데이터를 숫자화하거나 임베딩(embedding)을 생성할 때 vocabulary는 단어와 모델 간의 다리 역할을 합니다.
* 또한, vocabulary에는 특수 토큰(<PAD>, <UNK> 등)이 포함되어 데이터 정규화나 미지의 단어 처리를 지원합니다.
###임베딩
* 임베딩(Embedding)은 자연어 처리(NLP)에서 단어를 고정된 크기의 실수 벡터로 표현하는 방법입니다.
* 단어의 의미를 수치적으로 표현하며, 유사한 맥락에서 사용되는 단어들은 벡터 공간에서 가까운 위치에 놓이도록 학습됩니다.
* 임베딩은 단어의 고차원 희소 표현(예: 원-핫 벡터)을 저차원 조밀 표현으로 변환하여 데이터의 크기를 줄이고, 의미적 관계를 학습할 수 있는 특징을 제공합니다.
* 일반적으로 Word2Vec, GloVe, FastText 같은 사전 훈련된 임베딩이나 딥러닝 모델의 학습 과정에서 임베딩 레이어를 통해 생성됩니다.
* 임베딩은 텍스트 데이터를 수치 데이터로 변환하여 머신러닝과 딥러닝 모델에서 처리할 수 있게 하는 핵심 기술입니다.
예시 1)
# word_counts의 단어를 빈도수를 기준으로 내림차순으로 정렬
# word_counts.get : 각 단어의 빈도수를 가져오는 함수.
# reverse=True : 내림차순 정렬.
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
# 상위 10개 단어 출력
print('등장 빈도수 상위 10개 단어')
print(vocab[:10])
--->
등장 빈도수 상위 10개 단어
['the', ',', '.', 'and', 'a', 'of', 'to', 'is', '/', '>']
예시 2)
# 임계값(threshold) 설정
threshold = 3
# 전체 단어의 개수
total_cnt = len(word_counts) # word_counts에 저장된 고유 단어의 개수
# 희귀 단어(빈도수가 threshold 이하인 단어)의 개수와 빈도를 계산하기 위한 변수
rare_cnt = 0 # 희귀 단어의 개수
total_freq = 0 # 전체 단어 빈도의 합
rare_freq = 0 # 희귀 단어 빈도의 합
예시 3)
# 단어 집합 내 각 단어에 대해 계산
for key, value in word_counts.items():
total_freq = total_freq + value # 전체 단어 빈도 누적
if(value < threshold): # 임계값보다 작은 빈도인 경우
rare_cnt = rare_cnt + 1 # 희귀 단어 개수 증가
rare_freq = rare_freq + value # 희귀 단어 빈도 누적
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
#--->
# 단어 집합(vocabulary)의 크기 : 113389
# 등장 빈도가 2번 이하인 희귀 단어의 수: 70305
# 단어 집합에서 희귀 단어의 비율: 62.00336893349443
# 전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.2017385466831847
> 데이터에 등장하는 단어를 필터링하여 단어 집합의 크기를 줄이기
* 현재 데이터에서 등장 빈도가 threshold 값인 3회 미만(2회 이하)인 단어들은 단어 집합에서 60% 이상을 차지합니다.
* 하지만, 실제로 훈련 데이터에서 등장 빈도로 차지하는 비중은 상대적으로 매우 적은 수치인 1.19%밖에 되지 않습니다.
* 등장 빈도가 2회 이하인 단어들은 자연어 처리에서 중요하지 않을 것으로 예상됩니다.
* 따라서 이 단어들은 정수 인코딩 과정에서 배제합니다.
예시 4)
# 희귀 단어를 제외한 단어 집합의 크기 계산
# total_cnt는 전체 단어 집합의 크기(고유 단어의 개수)
# rare_cnt는 등장 빈도가 threshold 이하인 희귀 단어의 개수
vocab_size = total_cnt - rare_cnt
vocab_size
-->
43084
예시 5)
# 희귀 단어를 제외한 단어 집합(vocab)을 제한
vocab = vocab[:vocab_size] # vocab 리스트를 vocab_size 크기만큼 슬라이싱
# 단어 집합의 크기를 출력
print('단어 집합의 크기 : ', len(vocab))
--->
단어 집합의 크기 : 43084
예시 6)
# <PAD> 는 문장의 길이를 맞추기 위해 사용
# <UNK>는 사전에 없는 단어를 처리하기 위해 사용
# 단어를 정수 인덱스로 매핑할 딕셔너리 초기화
word_to_index = {}
# 특수 토큰 추가
word_to_index['<PAD>'] = 0 # 패딩 토큰(Padding)용
word_to_index['<UNK>'] = 1 # 알 수 없는 단어(Unknown Word)용

예시 7)
# 단어를 정수 인덱스로 매핑
for i, word in enumerate(vocab, start=2): # 인덱스는 2부터 시작
word_to_index[word] = i
print("word_to_index:", word_to_index) # 결과 출력
##또는
for index, word in enumerate(vocab):
word_to_index[word] = index + 2
print(word_to_index)
--->
#일부 출력
{'<PAD>': 0, '<UNK>': 1, 'the': 2, ',': 3, '.': 4, 'and': 5, 'a': 6, 'of': 7, 'to': 8, 'is': 9, '/': 10, '>': 11, '<': 12, 'br':
예시 8)
vocab_size = len(word_to_index)
print('패딩 토큰과 UNK 토큰을 고려한 단어 집합의 크기: ' , vocab_size)
--->
패딩 토큰과 UNK 토큰을 고려한 단어 집합의 크기: 43086
예제 9)
vocab_size = len(word_to_index)
print('패딩 토큰과 UNK 토큰을 고려한 단어 집합의 크기 :', vocab_size)
print('단어 <PAD>와 맵핑되는 정수 :', word_to_index['<PAD>'])
print('단어 <UNK>와 맵핑되는 정수 :', word_to_index['<UNK>'])
print('단어 the와 맵핑되는 정수 :', word_to_index['the'])
-->
패딩 토큰과 UNK 토큰을 고려한 단어 집합의 크기 : 43086
단어 <PAD>와 맵핑되는 정수 : 0
단어 <UNK>와 맵핑되는 정수 : 1
단어 the와 맵핑되는 정수 : 2
예제 10)
# 토큰화된 텍스트 데이터를 단어 인덱스로 변환하여 숫자 시퀀스로 만드는 작업
# 모델에 학습할 수 있는 형식으로 데이터를 변환
def texts_to_sequences(tokenized_X_data, word_to_index):
encoded_X_data = [] # 변환된 정수 인덱스 시퀀스를 저장할 리스트
for sent in tokenized_X_data: # 각 문장에 대해 반복
index_sequences = [] # 문장을 정수 인덱스 리스트로 변환
for word in sent:
try:
index_sequences.append(word_to_index[word]) # 단어를 정수 인덱스로 변환
except KeyError:
index_sequences.append(word_to_index['<UNK>']) # 단어가 없으면 '<UNK>' 인덱스 사용
encoded_X_data.append(index_sequences) # 변환된 문장을 추가
return encoded_X_data
예제 11)
print(tokenized_x_train[0]) # 첫 번째 문장의 토큰 리스트를 출력
print(tokenized_x_train[1]) # 두 번째 문장의 토큰 리스트를 출력
print(len(tokenized_x_train[0])) # 첫 번째 문장이 몇 개의 토큰으로 이루어져 있는지 확인
print(len(tokenized_x_train[1])) # 두 번째 문장이 몇 개의 토큰으로 이루어져 있는지 확인
--->
['this', 'has', 'by', 'far', 'been', 'one', 'of', 'the', 'most', 'beautiful', 'portraits', 'of', 'a', 'person', 'that', 'i', "'ve", 'ever', 'seen', 'on', 'screen', '.', 'andy', 'goldsworthy', 'is', 'a', 'kind', 'of', 'man', 'that', 'is', 'upon', 'extinction', '.', 'he', 'views', 'the', 'earth', 'and', 'nature', 'with', 'such', 'admiration', 'and', 'respect', 'that', 'it', "'s", 'primitive', 'in', 'a', 'good', 'sense', '.', 'his', 'purity', ',', 'honesty', 'and', 'kindness', 'breathes', 'clearly', 'as', 'you', 'watch', 'him', 'work', 'in', 'such', 'simplistic', 'yet', 'full', 'of', 'life', 'momentary', 'pieces', 'of', 'art', '.', 'i', 'was', 'amazed', 'how', 'patiently', 'he', 'created', 'his', 'pieces', 'and', 'how', 'patiently', 'he', 'accepted', 'their', 'end', '.', 'sometimes', 'prematurely', ',', 'but', 'his', 'scottish', 'sense', 'of', 'humor', 'covers', 'his', 'disappointments', 'brilliantly', '.', 'the', 'film', 'is', 'shoot', 'elegantly', 'and', 'contains', 'the', 'same', 'flow', 'that', 'goldsworthy', "'s", 'art', 'has', '.', 'it', 'combines', 'nature', 'and', 'art', 'in', 'a', 'minimal', 'way', 'as', 'it', 'is', 'in', 'itself', '.', 'fred', 'frith', "'s", 'score', 'is', 'organic', 'enough', 'that', 'it', 'blends', 'everything', 'together', 'without', 'interfering', 'with', 'it', 'naturalistic', 'sound', '.', 'this', 'is', 'overall', 'a', 'great', 'piece', 'of', 'work', 'in', 'every', 'aspect', '.', 'it', 'has', 'no', 'boundaries', 'as', 'far', 'as', 'age', 'goes', '.']
['when', 'the', 'film', 'started', 'i', 'got', 'the', 'feeling', 'this', 'was', 'going', 'to', 'be', 'something', 'special', '.', 'the', 'acting', 'and', 'camera', 'work', 'were', 'undoubtedly', 'good', '.', 'i', 'also', 'liked', 'the', 'characters', 'and', 'could', 'have', 'grown', 'to', 'empathise', 'with', 'them', '.', 'the', 'film', 'had', 'a', 'good', 'atmosphere', 'and', 'there', 'was', 'a', 'hint', 'of', 'fantasy.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'however', ',', 'as', 'the', 'film', 'went', 'on', ',', 'the', 'plot', 'never', 'appeared', 'to', 'takeoff', 'and', 'just', 'rolled', 'on', 'scene', 'by', 'scene', '.', 'i', 'was', 'unable', 'to', 'understand', 'the', 'connection', 'between', 'the', 'stories', '.', 'all', 'i', 'could', 'see', 'was', 'the', 'characters', 'occasionally', 'bumping', 'into', 'each', 'other', 'and', 'references', 'to', 'ships', 'in', 'bottles', '.', 'without', 'that', 'connection', ',', 'i', 'was', 'just', 'left', 'with', 'a', 'few', 'unremarkable', 'short', 'stories.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'am', 'surprised', 'it', 'did', 'so', 'well', 'at', 'cannes']
182
142
예제 12)
# encoded_x_train은 tokenized_x_train의 토큰 리스트를 숫자 시퀀스로 변환한 결과를 담음
encoded_x_train = texts_to_sequences(tokenized_x_train, word_to_index)
# encoded_x_test는 tokenized_x_test의 토큰 리스트를 숫자 시퀀스로 변환한 결과를 담음
encoded_x_test = texts_to_sequences(tokenized_x_test, word_to_index)
print(encoded_x_train[0]) # 첫 번째 문장의 각 단어를 숫자로 변환한 리스트 출력
--->
[17, 57, 45, 240, 95, 40, 7, 2, 106, 321, 11890, 7, 6, 417, 18, 16, 158, 140, 129, 30, 300, 4, 2070, 8982, 9, 6, 252, 7, 142, 18, 9, 687, 17765, 4, 37, 2739, 2, 740, 5, 925, 22, 159, 7223, 5, 1118, 18, 14, 19, 5972, 15, 6, 63, 296, 4, 36, 11281, 3, 3725, 5, 8374, 18712, 713, 21, 29, 121, 108, 181, 15, 159, 4260, 257, 385, 7, 139, 16959, 1320, 7, 551, 4, 16, 20, 2626, 105, 18713, 37, 1041, 36, 1320, 5, 105, 18713, 37, 2687, 78, 150, 4, 520, 17766, 3, 25, 36, 5095, 296, 7, 481, 3878, 36, 9715, 2030, 4, 2, 26, 9, 1256, 17767, 5, 1323, 2, 182, 2726, 18, 8982, 19, 551, 57, 4, 14, 5906, 925, 5, 551, 15, 6, 3404, 114, 21, 14, 9, 15, 414, 4, 2250, 36112, 19, 574, 9, 8673, 213, 18, 14, 9341, 279, 309, 218, 20874, 22, 14, 13987, 458, 4, 17, 9, 452, 6, 104, 428, 7, 181, 15, 186, 1344, 4, 14, 57, 72, 8070, 21, 240, 21, 636, 278, 4]
예제 13)
print(len(encoded_x_train[0])) # 첫 번째 문장의 토큰(숫자) 개수 출력
print(len(encoded_x_train[1])) # 두 번째 문장의 토큰(숫자) 개수 출력
--->
182
142
예제 14)
# 상위 샘플 2개 출력
for sent in encoded_x_train[:2]:
print(sent)
-->
[17, 57, 45, 240, 95, 40, 7, 2, 106, 321, 11890, 7, 6, 417, 18, 16, 158, 140, 129, 30, 300, 4, 2070, 8982, 9, 6, 252, 7, 142, 18, 9, 687, 17765, 4, 37, 2739, 2, 740, 5, 925, 22, 159, 7223, 5, 1118, 18, 14, 19, 5972, 15, 6, 63, 296, 4, 36, 11281, 3, 3725, 5, 8374, 18712, 713, 21, 29, 121, 108, 181, 15, 159, 4260, 257, 385, 7, 139, 16959, 1320, 7, 551, 4, 16, 20, 2626, 105, 18713, 37, 1041, 36, 1320, 5, 105, 18713, 37, 2687, 78, 150, 4, 520, 17766, 3, 25, 36, 5095, 296, 7, 481, 3878, 36, 9715, 2030, 4, 2, 26, 9, 1256, 17767, 5, 1323, 2, 182, 2726, 18, 8982, 19, 551, 57, 4, 14, 5906, 925, 5, 551, 15, 6, 3404, 114, 21, 14, 9, 15, 414, 4, 2250, 36112, 19, 574, 9, 8673, 213, 18, 14, 9341, 279, 309, 218, 20874, 22, 14, 13987, 458, 4, 17, 9, 452, 6, 104, 428, 7, 181, 15, 186, 1344, 4, 14, 57, 72, 8070, 21, 240, 21, 636, 278, 4]
[64, 2, 26, 639, 16, 197, 2, 554, 17, 20, 179, 8, 39, 157, 326, 4, 2, 131, 5, 388, 181, 82, 4407, 63, 4, 16, 97, 440, 2, 120, 5, 94, 38, 2359, 8, 15617, 22, 113, 4, 2, 26, 79, 6, 63, 836, 5, 51, 20, 6, 2898, 7, 17768, 12, 13, 10, 11, 12, 13, 10, 11, 205, 3, 21, 2, 26, 418, 30, 3, 2, 137, 132, 1459, 8, 28377, 5, 53, 5096, 30, 146, 45, 146, 4, 16, 20, 1987, 8, 400, 2, 1816, 214, 2, 563, 4, 43, 16, 94, 80, 20, 2, 120, 1823, 11282, 101, 263, 102, 5, 1774, 8, 5277, 15, 11283, 4, 218, 18, 1816, 3, 16, 20, 53, 324, 22, 6, 187, 9716, 353, 13493, 12, 13, 10, 11, 12, 13, 10, 11, 249, 743, 14, 84, 49, 92, 42, 6541]
예제 15)
# index_to_word 초기화
index_to_word = {}
for key, value in word_to_index.items():
# index_to_word 딕셔너리에 정수를 키로, 단어를 값으로 저장
index_to_word[value] = key
print(word_to_index) # 각 단어와 해당 단어에 매핑된 고유한 정수 출력
print(index_to_word) # 각 정수와 해당 정수에 매핑된 단어 출력
--->
#부분 출력
{'<PAD>': 0, '<UNK>': 1, 'the': 2, ',': 3, '.': 4, 'and': 5, 'a': 6, 'of': 7, 'to': 8, 'is': 9, '/': 10,
{0: '<PAD>', 1: '<UNK>', 2: 'the', 3: ',', 4: '.', 5: 'and', 6: 'a', 7: 'of', 8: 'to', 9: 'is', 10: '/',
예시 16)
decoded_sample = [index_to_word[word] for word in encoded_x_train[0]]
print('기존의 첫번째 샘플 :', tokenized_x_train[0]) # 원래 단어 리스트 출력
print('복원된 첫번째 샘플 :', decoded_sample) # 숫자 시퀀스를 다시 단어로 변환한 결과
--->
기존의 첫번째 샘플 : ['the', 'creepy', 'demons', '``', 'the', 'gentlemen', "''", 'capture', 'the', 'voice', 'of', 'the', 'population', 'of', 'sunnydale', ',', 'to', 'steal', 'human', 'hearts', 'without', 'scream', '.', 'giles', 'find', 'that', 'in', 'accordance', 'with', 'a', 'legend', ',', 'if', 'a', 'lady', 'screams', ',', 'the', 'creatures', 'will', 'be', 'destroyed', ',', 'but', 'buffy', 'and', 'her', 'friends', ',', 'including', 'riley', ',', 'have', 'to', 'fight', 'the', 'monsters', 'speechless.', '<', 'br', '/', '>', '<', 'br', '/', '>', "''", 'hush', "''", 'is', 'certainly', 'the', 'best', 'episode', 'of', 'the', 'fourth', 'season', 'of', 'buffy', 'up', 'to', 'this', 'moment', '.', 'having', 'lots', 'of', 'humor', 'and', 'funny', 'situations', ',', 'i', 'liked', 'a', 'lot', '.', 'spike', 'is', 'hilarious', ',', 'the', 'romance', 'between', 'xander', 'and', 'anya', 'is', 'cool', ',', 'but', 'i', 'loved', 'the', '``', 'intense', "''", 'dialog', 'between', 'buffy', 'and', 'riley', 'in', 'end', '.', 'the', 'gothic', 'scenario', 'of', 'the', 'final', 'battle', 'against', '``', 'the', 'gentlemen', "''", 'recalls', 'the', 'environment', 'of', '``', 'dark', 'city', "''", '.', 'my', 'vote', 'is', 'ten.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'title', '(', 'brazil', ')', ':', '``', 'silêncio', "''", '(', '``', 'silence', "''", ')']
복원된 첫번째 샘플 : ['the', 'creepy', 'demons', '``', 'the', 'gentlemen', "''", 'capture', 'the', 'voice', 'of', 'the', 'population', 'of', '<UNK>', ',', 'to', 'steal', 'human', 'hearts', 'without', 'scream', '.', 'giles', 'find', 'that', 'in', 'accordance', 'with', 'a', 'legend', ',', 'if', 'a', 'lady', 'screams', ',', 'the', 'creatures', 'will', 'be', 'destroyed', ',', 'but', 'buffy', 'and', 'her', 'friends', ',', 'including', 'riley', ',', 'have', 'to', 'fight', 'the', 'monsters', 'speechless.', '<', 'br', '/', '>', '<', 'br', '/', '>', "''", 'hush', "''", 'is', 'certainly', 'the', 'best', 'episode', 'of', 'the', 'fourth', 'season', 'of', 'buffy', 'up', 'to', 'this', 'moment', '.', 'having', 'lots', 'of', 'humor', 'and', 'funny', 'situations', ',', 'i', 'liked', 'a', 'lot', '.', 'spike', 'is', 'hilarious', ',', 'the', 'romance', 'between', 'xander', 'and', 'anya', 'is', 'cool', ',', 'but', 'i', 'loved', 'the', '``', 'intense', "''", 'dialog', 'between', 'buffy', 'and', 'riley', 'in', 'end', '.', 'the', 'gothic', 'scenario', 'of', 'the', 'final', 'battle', 'against', '``', 'the', 'gentlemen', "''", 'recalls', 'the', 'environment', 'of', '``', 'dark', 'city', "''", '.', 'my', 'vote', 'is', 'ten.', '<', 'br', '/', '>', '<', 'br', '/', '>', 'title', '(', 'brazil', ')', ':', '``', '<UNK>', "''", '(', '``', 'silence', "''", ')']
##OOV 문제
* OOV(Out-Of-Vocabulary)는 단어 집합(vocabulary)에 포함되지 않은 단어를 의미합니다. * 모델이 학습 중에 보지 못한 단어가 테스트 데이터 또는 실사용 환경에서 나타날 때 발생하며, 이는 학습된 모델이 해당 단어를 처리하지 못하는 문제를 초래합니다.
* OOV 문제를 해결하기 위해 일반적으로 <UNK>(Unknown) 토큰을 사용하여 이러한 단어를 대체하거나, 사전에 포함될 단어의 수를 늘리거나 서브워드(subword) 기반 기법(예: BPE, WordPiece)을 사용하여 단어를 더 작은 단위로 분할해 처리합니다.
* OOV 처리는 모델의 성능과 일반화 능력에 중요한 영향을 미칩니다.
예시 1)
# 각 리뷰의 길이(len(review))를 계산하고, 그 중 최댓값을 계산
print('리뷰의 최대 길이 :', max(len(review) for review in encoded_x_train))
# 리뷰의 길이(len(review))를 모두 더한 후, 리뷰 개수(len(encoded_x_train))로 나누어 평균 계산
print('리뷰의 평균 길이 :', sum(map(len, encoded_x_train)) / len(encoded_x_train))
예시 2)
# 각 리뷰(review)의 길이(len(review))를 리스트로 만듬
review_lengths = [len(review) for review in encoded_x_train]
# 히스토그램의 구간을 50개로 나누어 분포를 히스토그램으로 시각화
plt.hist(review_lengths, bins=50)
# x축 라벨: 샘플 길이
plt.xlabel('length of samples')
# y축 라벨: 해당 길이를 가진 리뷰의 개수
plt.ylabel('number of samples')
# 그래프 출력
plt.show()--->
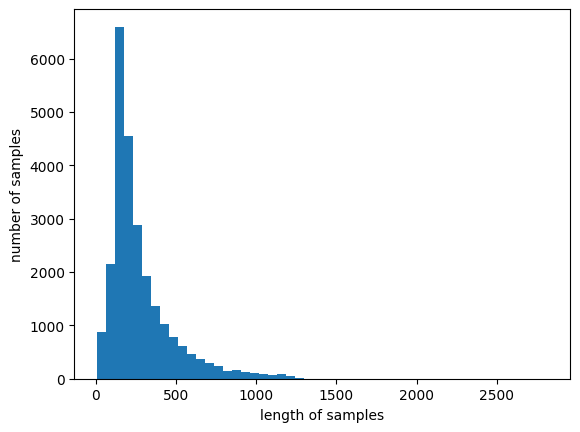
예시 3)
def below_threshold_len(max_len, nested_list):
# 길이가 max_len 이하인 샘플의 개수를 저장할 변수 초기화
count = 0
# 리뷰 리스트(nested_list)를 순회하면서 각 문장(sentence)의 길이를 확인
for sentence in nested_list:
if len(sentence) <= max_len: # 만약 문장의 길이가 max_len 이하라면
count = count + 1 # 조건을 만족하는 샘플의 개수를 증가
# 조건을 만족하는 샘플의 비율을 계산하여 출력
# 전체 샘플 중 max_len 이하인 샘플의 비율을 계산
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s' %
(max_len, (count / len(nested_list)) * 100))
예시 4)
below_threshold_len(500, encoded_x_train)
-->
전체 샘플 중 길이가 500 이하인 샘플의 비율: 87.836
4. 패딩
* 패딩(Padding)은 모델에 입력되는 데이터의 길이를 일정하게 맞추기 위해 추가하는 작업입니다.
* 텍스트 데이터는 문장마다 단어 수가 다를 수 있지만, 딥러닝 모델은 고정된 크기의 입력만 처리할 수 있기 때문에, 짧은 문장에 특수 토큰 <PAD>를 추가하여 길이를 맞춥니다.
* 패딩은 주로 문장의 뒤쪽이나 앞쪽에 0으로 채우는 방식으로 이루어지며, 이는 학습에 영향을 주지 않도록 설계됩니다.
* 패딩을 통해 배치 처리가 가능해지고, 모델의 학습 및 추론 효율성이 높아집니다.
* 일반적으로 패딩은 max_len이라는 최대 길이를 기준으로 수행되며, 너무 긴 문장은 잘라내기도 합니다.
예시 1)
# 문장 리스트를 고정된 길이로 패딩하여 모델 입력에 적합한 형태로 변환하는 작업
# 문장 길이를 맞추어 일관된 데이터 형식을 제공
def pad_sequences(sentences, max_len):
features = np.zeros((len(sentences), max_len), dtype=int)
for index, sentence in enumerate(sentences):
if len(sentence) != 0:
features[index, :len(sentence)] = np.array(sentence)[:max_len]
return features
예시 2)
np.zeros((3,3), dtype=int)
-->
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
예시 3)
padded_X_train = pad_sequences(encoded_X_train, max_len=max_len)
padded_X_test = pad_sequences(encoded_X_test, max_len=max_len)
print('훈련 데이터의 크기 :', padded_X_train.shape)
print('테스트 데이터의 크기 :', padded_X_test.shape)
예시 4)
# padded_X_train의 첫 5개 샘플(데이터)만 출력
# 문장의 길이가 다르므로, 길이를 맞추기 위해 0을 채우는 패딩기법
padded_X_train[:5]
-->
array([[ 17, 57, 45, ..., 0, 0, 0],
[ 64, 2, 26, ..., 0, 0, 0],
[ 2, 946, 2771, ..., 0, 0, 0],
[ 2, 26, 1960, ..., 0, 0, 0],
[ 159, 6, 11550, ..., 0, 0, 0]])
예시 5)
# 각 샘플(리스트)의 길이(패딩 포함) 를 반환
# padded_X_train의 첫 번째 샘플(문장 또는 데이터 한 개) 을 가져오는 코드
len(padded_X_train[0])
-->
600
예시 6)
# 훈련 데이터(padded_X_train)에서 첫 번째 샘플(문장, 시퀀스)을 가져오는 코드
# 문장이 숫자 시퀀스로 변환된 형태를 확인
# 패딩된 부분(앞쪽의 0)을 포함하여 출력
print(padded_X_train[0])
--->
[ 17 57 45 240 95 40 7 2 106 321 11890 7
6 417 18 16 158 140 129 30 300 4 2070 8982
9 6 252 7 142 18 9 687 17765 4 37 2739
2 740 5 925 22 159 7223 5 1118 18 14 19
5972 15 6 63 296 4 36 11281 3 3725 5 8374
18712 713 21 29 121 108 181 15 159 4260 257 385
7 139 16959 1320 7 551 4 16 20 2626 105 18713
37 1041 36 1320 5 105 18713 37 2687 78 150 4
520 17766 3 25 36 5095 296 7 481 3878 36 9715
2030 4 2 26 9 1256 17767 5 1323 2 182 2726
18 8982 19 551 57 4 14 5906 925 5 551 15
6 3404 114 21 14 9 15 414 4 2250 36112 19
574 9 8673 213 18 14 9341 279 309 218 20874 22
14 13987 458 4 17 9 452 6 104 428 7 181
15 186 1344 4 14 57 72 8070 21 240 21 636
278 4 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0]