2025. 1. 10. 17:31ㆍLLM(Large Language Model)의 기초/데이터 분석
참고 사이트
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html
load_digits
Gallery examples: Release Highlights for scikit-learn 1.3 Recognizing hand-written digits A demo of K-Means clustering on the handwritten digits data Feature agglomeration Various Agglomerative Clu...
scikit-learn.org
예시 1)
# PyTorch 관련 라이브러리 및 시각화 도구, 데이터셋 로드 라이브러리 임포트
import torch # PyTorch 라이브러리 (텐서 연산 및 딥러닝 모델 구축)
import torch.nn as nn # PyTorch의 신경망 모듈
import torch.optim as optim # PyTorch의 최적화 알고리즘 모듈
import matplotlib.pyplot as plt # 데이터 시각화를 위한 라이브러리
from sklearn.datasets import load_digits # 손글씨 숫자 데이터셋 로드를 위한 모듈
from sklearn.model_selection import train_test_split # 데이터셋 분할 함수
# 손글씨 숫자 데이터셋 로드
digits = load_digits() # sklearn의 load_digits 함수로 데이터셋 로드
# 데이터와 레이블(타겟) 분리
X_data = digits['data'] # 입력 데이터 (8x8 픽셀로 이루어진 손글씨 숫자 이미지, 펼쳐진 형태)
y_data = digits['target'] # 타겟 데이터 (0~9까지의 숫자 레이블)
# 데이터와 레이블의 형태 출력
print(X_data.shape) # 입력 데이터의 형태 출력 (샘플 수, 특성 수)
print(y_data.shape) # 타겟 데이터의 형태 출력 (샘플 수)
--->
(1797, 64) # X_data
(1797,) # y_data
예시 2)
y_data
--->
array([0, 1, 2, ..., 8, 9, 8])
예시 3)
# 손글씨 숫자 데이터를 시각화하기 위한 그래프 설정
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14, 8))
# - plt.subplots(): 그래프 여러 개를 한 화면에 그릴 수 있는 서브플롯 생성 함수.
# - nrows=2, ncols=5: 2행 5열의 서브플롯 배열 생성.
# - 총 10개의 서브플롯이 생성됩니다.
# - figsize=(14, 8): 전체 플롯의 크기를 설정 (단위: 인치).
# 서브플롯에 데이터와 레이블 표시
for i, ax in enumerate(axes.flatten()):
# - enumerate(axes.flatten()): 서브플롯을 1차원 리스트로 평탄화하고, 인덱스(i)와 서브플롯(ax)을 함께 가져옵니다.
# - i: 현재 서브플롯의 인덱스 (0부터 시작).
# - ax: 현재 서브플롯 객체.
ax.imshow(X_data[i].reshape(8, 8), cmap='gray')
# - ax.imshow(): 현재 서브플롯(ax)에 이미지를 표시.
# - X_data[i]: i번째 손글씨 숫자 데이터.
# - .reshape(8, 8): 데이터를 8x8 형태로 변환 (원래 픽셀 이미지 형태).
# - cmap='gray': 이미지를 흑백(그레이스케일)으로 표시.
ax.set_title(y_data[i])
# - ax.set_title(): 현재 서브플롯의 제목(타이틀) 설정.
# - y_data[i]: i번째 데이터의 숫자 레이블을 제목으로 표시.
ax.axis('off')
# - ax.axis('off'): 현재 서브플롯의 x축, y축 눈금과 축선을 제거하여 이미지만 표시.
예시 4)
# 입력 데이터와 타겟 데이터를 PyTorch 텐서로 변환
# X_data = torch.FloatTensor(X_data):
# - X_data를 PyTorch의 FloatTensor로 변환합니다.
# - FloatTensor: 32비트 부동소수점(float32)을 사용하는 텐서 타입입니다.
# - 손글씨 이미지 데이터(X_data)는 64개의 특성(픽셀 값)으로 이루어진 수치 데이터이므로 FloatTensor로 변환하여 모델 학습에 사용합니다.
# y_data = torch.LongTensor(y_data):
# - y_data를 PyTorch의 LongTensor로 변환합니다.
# - LongTensor: 64비트 정수(long)를 사용하는 텐서 타입입니다.
# - 타겟 데이터(y_data)는 정수형(0~9)의 숫자 레이블로 구성되어 있으므로 LongTensor로 변환합니다.
# - PyTorch의 분류 모델에서 레이블 데이터는 정수형(LongTensor)으로 변환되어야 합니다.
# 데이터 형태 출력
print(X_data.shape) # X_data 텐서의 형태 출력 (샘플 수, 특성 수)
print(y_data.shape) # y_data 텐서의 형태 출력 (샘플 수)
--->
torch.Size([1797, 64]) #X_data
torch.Size([1797]) #y_data
예제 5)
# 데이터를 학습 세트와 테스트 세트로 분할
# train_test_split():
# - scikit-learn의 데이터 분할 함수로, 데이터를 학습 세트와 테스트 세트로 나눕니다.
# - 입력 데이터(X_data)와 타겟 데이터(y_data)를 지정된 비율로 나누어 반환합니다.
# 매개변수:
# - X_data: 입력 데이터 (특성 데이터, 손글씨 숫자 이미지).
# - y_data: 타겟 데이터 (레이블, 숫자 0~9).
# - test_size=0.3:
# - 전체 데이터 중 30%를 테스트 세트로 사용.
# - 나머지 70%는 학습 세트로 사용.
# - random_state=2025:
# - 난수 생성 시드를 설정하여 결과 재현성을 보장.
# - 동일한 데이터를 입력했을 때 항상 같은 학습/테스트 세트로 나뉘도록 설정.
# 반환 값:
# - X_train: 학습 세트의 입력 데이터.
# - X_test: 테스트 세트의 입력 데이터.
# - y_train: 학습 세트의 타겟 데이터.
# - y_test: 테스트 세트의 타겟 데이터.
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.3, random_state=2025)
예제 6)
# 학습 세트와 테스트 세트의 데이터 크기를 출력하여 확인
# X_train.shape:
# - 학습 세트의 입력 데이터(X_train)의 형태를 반환합니다.
# - X_train은 학습에 사용되는 입력 데이터로, 각 샘플은 64개의 특성(픽셀 값)으로 구성되어 있습니다.
# - 결과는 텐서의 크기(샘플 수, 특성 수)를 나타냅니다.
# y_train.shape:
# - 학습 세트의 타겟 데이터(y_train)의 형태를 반환합니다.
# - y_train은 학습에 사용되는 타겟 데이터로, 각 샘플에 대해 정수형 숫자 레이블(0~9)을 나타냅니다.
# - 결과는 텐서의 크기(샘플 수)를 나타냅니다.
# y_train.shape:
# - 위와 동일하게 학습 세트의 타겟 데이터(y_train)의 형태를 반환합니다.
# y_test.shape:
# - 테스트 세트의 타겟 데이터(y_test)의 형태를 반환합니다.
# - y_test는 모델 평가에 사용되는 테스트 세트 타겟 데이터입니다.
# - 결과는 텐서의 크기(샘플 수)를 나타냅니다.
X_train.shape, y_train.shape # 학습 세트 입력 데이터와 타겟 데이터의 크기 확인
y_train.shape, y_test.shape # 학습 세트와 테스트 세트 타겟 데이터의 크기 확인
--->
(torch.Size([1257, 64]), torch.Size([1257])) # X_train.shape, y_train.shape
(torch.Size([1257]), torch.Size([540])) # y_train.shape, y_test.shape
2. 데이터 로더
* 데이터로더(DataLoader)는 딥러닝 프레임워크(예: PyTorch)에서 데이터를 효과적으로 관리하고 모델에 공급하기 위해 사용되는 도구입니다.
* 데이터셋에서 배치(batch) 단위로 데이터를 로드하고, 학습 중에 필요한 데이터 샘플링, 셔플링, 병렬 처리 등을 간편하게 수행할 수 있습니다.
* 데이터로더는 데이터셋 객체(Dataset)과 함께 작동하며, 데이터셋의 개별 항목에 접근하는 방식을 정의하는 Dataset 클래스와 달리, 데이터를 미니배치로 묶어서 반복(iteration) 가능한 형태로 제공합니다.
예시 1)
from torch.utils.data import DataLoader # PyTorch의 데이터 로딩 유틸리티
# DataLoader 객체 생성
loader = DataLoader(
dataset=list(zip(X_train, y_train)), # 학습 데이터를 데이터셋으로 사용
batch_size=64, # 배치 크기: 한 번에 처리할 데이터 샘플 수
shuffle=True, # 에포크마다 데이터를 무작위로 섞음
drop_last=False # 마지막 배치를 버리지 않음 (배치 크기가 작아도 유지)
)
예시 2)
# DataLoader에서 한 배치의 데이터 가져오기
imgs, labels = next(iter(loader))
# - `iter(loader)`: DataLoader 객체에서 반복자를 생성합니다.
# - `next()`: 반복자에서 다음 배치를 가져옵니다.
# - `imgs`: 현재 배치의 입력 데이터 (손글씨 이미지).
# - `labels`: 현재 배치의 타겟 데이터 (숫자 레이블).
# 8x8 서브플롯 생성
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
# - plt.subplots(): 여러 개의 서브플롯 생성.
# - nrows=8, ncols=8: 8행 8열의 서브플롯 배열 생성.
# - figsize=(14, 14): 전체 플롯 크기를 설정 (단위: 인치).
# - 결과적으로 64개의 서브플롯이 생성됩니다.
# 배치에서 이미지를 시각화
for ax, img, label in zip(axes.flatten(), imgs, labels):
# - axes.flatten(): 2차원 서브플롯 배열을 1차원 리스트로 평탄화.
# - zip(axes.flatten(), imgs, labels): 서브플롯(ax), 이미지(img), 레이블(label)을 순서대로 묶어 반복.
ax.imshow(img.reshape((8, 8)), cmap='gray')
# - ax.imshow(): 현재 서브플롯(ax)에 이미지를 표시.
# - img.reshape((8, 8)): 1차원 형태의 이미지를 8x8 형태로 변환.
# - cmap='gray': 이미지를 흑백(그레이스케일)으로 표시.
ax.set_title(str(label))
# - ax.set_title(): 현재 서브플롯의 제목(타이틀) 설정.
# - str(label): 타겟 레이블(숫자)을 문자열로 변환하여 제목으로 표시.
ax.axis('off')
# - ax.axis('off'): 현재 서브플롯의 x축, y축 눈금과 축선을 제거하여 이미지만 표시.--->

axes.flatten()
* axes.flatten()은 다차원 배열 형태로 구성된 Matplotlib의 서브플롯 배열을 1차원 배열로 변환하는 메서드입니다.
* Matplotlib에서 다수의 서브플롯을 생성할 때, plt.subplots()는 2차원 배열 형태로 서브플롯 객체를 반환합니다.
* 이 배열은 각 서브플롯을 접근하기 위해 행과 열의 인덱스를 사용해야 하지만, flatten() 메서드를 사용하면 이 배열을 1차원으로 펼쳐서 각 서브플롯을 단일 인덱스로 순회할 수 있게 됩니다.
예시 1)
# PyTorch의 신경망 모델 생성
model = nn.Sequential(
nn.Linear(64, 10) # 입력 노드 64개, 출력 노드 10개를 갖는 선형 계층 (Fully Connected Layer)
)
# - nn.Sequential():
# - PyTorch에서 제공하는 클래스.
# - 계층(layers)을 순차적으로 쌓아 신경망 모델을 생성합니다.
# - 간단한 네트워크를 구성할 때 유용합니다.
# - nn.Linear(64, 10):
# - 선형 계층(Fully Connected Layer)을 정의합니다.
# - 입력 특징(input features): 64개.
# - 손글씨 데이터셋의 각 이미지가 8x8 픽셀로 구성되어 펼쳐진 형태 (64차원).
# - 출력 특징(output features): 10개.
# - 손글씨 숫자(0~9)를 분류하기 위해 10개의 출력 노드 생성.
# - 선형 변환 공식:
# y = xWᵀ + b
# - W: 학습할 가중치(weight).
# - b: 학습할 편향(bias).
# - x: 입력 데이터.
# 결과:
# - 모델은 64개의 입력 노드와 10개의 출력 노드를 갖는 단일 계층으로 구성된 신경망입니다.
예시 2)
# Adam 최적화 알고리즘 설정
optimizer = optim.Adam(model.parameters(), lr=0.01)
# - optim.Adam():
# - PyTorch에서 제공하는 Adam 최적화 알고리즘.
# - Stochastic Gradient Descent(SGD) 방식의 확장된 알고리즘으로, 학습 속도가 빠르고 성능이 우수함.
# - Adaptive Moment Estimation(적응적 모멘트 추정)을 사용하여 학습률을 자동으로 조정.
# 매개변수:
# - model.parameters():
# - 신경망 모델 `model`의 학습 가능한 매개변수(가중치 및 편향)를 가져옵니다.
# - 이 매개변수들은 Adam 최적화 알고리즘에 의해 업데이트됩니다.
# - lr=0.01:
# - 학습률(learning rate)로, 매개변수를 업데이트할 때 사용되는 스텝 크기를 의미합니다.
# - 값이 너무 크면 최적점 근처에서 발산할 수 있고, 너무 작으면 수렴 속도가 느려질 수 있습니다.
# 결과:
# - `optimizer`는 Adam 알고리즘으로 학습률 0.01을 사용하여 모델의 매개변수를 업데이트하는 최적화 객체입니다.
예시 3)
# 학습 파라미터 설정
epochs = 50 # 총 학습 반복 횟수 설정
# 에포크 루프: 전체 데이터를 학습 반복 횟수만큼 학습
for epoch in range(epochs + 1): # epochs + 1: 0부터 시작하여 지정한 에포크 수까지 학습
sum_losses = 0 # 현재 에포크의 총 손실값 초기화
sum_accs = 0 # 현재 에포크의 총 정확도 초기화
# 배치 루프: DataLoader에서 배치 단위로 데이터를 가져와 학습
for x_batch, y_batch in loader:
y_pred = model(x_batch) # 모델에 입력 데이터를 전달하여 예측값 계산
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
# - nn.CrossEntropyLoss():
# - 다중 클래스 분류 문제에서 사용하는 손실 함수.
# - 소프트맥스와 교차 엔트로피 손실을 결합하여 예측값과 실제값의 차이를 계산.
optimizer.zero_grad() # 옵티마이저의 그래디언트를 초기화
loss.backward() # 역전파를 통해 그래디언트 계산
optimizer.step() # 옵티마이저를 통해 모델의 매개변수 업데이트
sum_losses = sum_losses + loss # 현재 배치 손실값을 총 손실값에 누적
y_prob = nn.Softmax(1)(y_pred) # 예측값에 소프트맥스 적용하여 클래스 확률 계산
y_pred_index = torch.argmax(y_prob, axis=1)
# - torch.argmax():
# - 예측 확률 중 가장 높은 클래스의 인덱스 반환.
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
# - 정확도 계산:
# - (정답 레이블과 예측 레이블이 일치한 개수) / (배치 크기) * 100
sum_accs = sum_accs + acc # 현재 배치 정확도를 총 정확도에 누적
avg_loss = sum_losses / len(loader) # 현재 에포크의 평균 손실값 계산
avg_acc = sum_accs / len(loader) # 현재 에포크의 평균 정확도 계산
# 현재 에포크의 손실값 및 정확도 출력
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
# - f-string을 사용하여 현재 에포크 번호, 손실값, 정확도 출력.
---->
Epoch 0/50 Loss: 1.923836 Accuracy: 56.90%
Epoch 1/50 Loss: 0.281983 Accuracy: 90.41%
Epoch 2/50 Loss: 0.152630 Accuracy: 95.55%
Epoch 3/50 Loss: 0.133091 Accuracy: 96.13%
Epoch 4/50 Loss: 0.105941 Accuracy: 96.99%
Epoch 5/50 Loss: 0.084001 Accuracy: 98.00%
Epoch 6/50 Loss: 0.074303 Accuracy: 98.52%
Epoch 7/50 Loss: 0.073686 Accuracy: 97.85%
Epoch 8/50 Loss: 0.069643 Accuracy: 98.05%
Epoch 9/50 Loss: 0.058623 Accuracy: 98.32%
Epoch 10/50 Loss: 0.051944 Accuracy: 99.22%
Epoch 11/50 Loss: 0.045732 Accuracy: 99.22%
Epoch 12/50 Loss: 0.042547 Accuracy: 99.30%
Epoch 13/50 Loss: 0.037440 Accuracy: 99.38%
Epoch 14/50 Loss: 0.037123 Accuracy: 99.45%
Epoch 15/50 Loss: 0.033907 Accuracy: 99.69%
Epoch 16/50 Loss: 0.032428 Accuracy: 99.30%
Epoch 17/50 Loss: 0.031844 Accuracy: 99.45%
Epoch 18/50 Loss: 0.032324 Accuracy: 99.41%
Epoch 19/50 Loss: 0.030089 Accuracy: 99.53%
Epoch 20/50 Loss: 0.026704 Accuracy: 99.69%
Epoch 21/50 Loss: 0.021115 Accuracy: 99.84%
Epoch 22/50 Loss: 0.024513 Accuracy: 99.64%
Epoch 23/50 Loss: 0.025320 Accuracy: 99.61%
Epoch 24/50 Loss: 0.023450 Accuracy: 99.53%
Epoch 25/50 Loss: 0.022169 Accuracy: 99.69%
Epoch 26/50 Loss: 0.021205 Accuracy: 99.64%
Epoch 27/50 Loss: 0.019304 Accuracy: 99.69%
Epoch 28/50 Loss: 0.017562 Accuracy: 99.80%
Epoch 29/50 Loss: 0.016471 Accuracy: 99.69%
Epoch 30/50 Loss: 0.015724 Accuracy: 99.77%
Epoch 31/50 Loss: 0.015748 Accuracy: 99.77%
Epoch 32/50 Loss: 0.015667 Accuracy: 99.92%
Epoch 33/50 Loss: 0.017071 Accuracy: 99.77%
Epoch 34/50 Loss: 0.012460 Accuracy: 100.00%
Epoch 35/50 Loss: 0.013310 Accuracy: 99.92%
Epoch 36/50 Loss: 0.012838 Accuracy: 99.77%
Epoch 37/50 Loss: 0.014883 Accuracy: 99.84%
Epoch 38/50 Loss: 0.017948 Accuracy: 99.61%
Epoch 39/50 Loss: 0.011514 Accuracy: 99.92%
Epoch 40/50 Loss: 0.013424 Accuracy: 99.92%
Epoch 41/50 Loss: 0.015664 Accuracy: 99.80%
Epoch 42/50 Loss: 0.012760 Accuracy: 99.84%
Epoch 43/50 Loss: 0.009632 Accuracy: 99.92%
Epoch 44/50 Loss: 0.008404 Accuracy: 100.00%
Epoch 45/50 Loss: 0.009289 Accuracy: 99.92%
Epoch 46/50 Loss: 0.011098 Accuracy: 99.84%
Epoch 47/50 Loss: 0.009076 Accuracy: 99.92%
Epoch 48/50 Loss: 0.012573 Accuracy: 99.84%
Epoch 49/50 Loss: 0.015936 Accuracy: 99.69%
Epoch 50/50 Loss: 0.013620 Accuracy: 99.84%
예시 4)
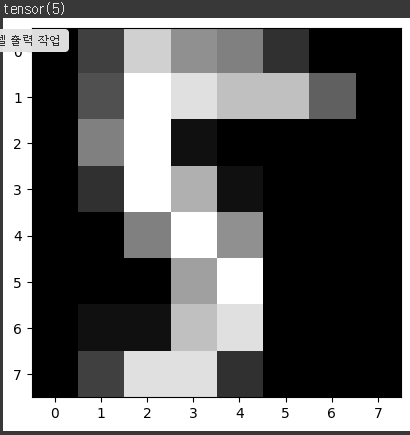
# 테스트 데이터의 10번째 샘플 이미지를 시각화하고 해당 타겟 레이블 출력
plt.imshow(X_test[10].reshape((8, 8)), cmap='gray')
# - plt.imshow():
# - 이미지를 시각화하기 위한 matplotlib 함수.
# - X_test[10]:
# - 테스트 데이터에서 10번째 샘플의 입력 데이터.
# - .reshape((8, 8)):
# - 테스트 데이터는 1차원(64차원) 형태로 되어 있으므로 8x8 형태의 2차원 이미지로 변환.
# - cmap='gray':
# - 이미지를 흑백(그레이스케일)으로 표시.
print(y_test[10])
# - y_test[10]:
# - 테스트 데이터의 10번째 샘플에 대한 실제 타겟 레이블(숫자 0~9)을 출력.---->
예시 5)
# 테스트 데이터의 예측값 계산
y_pred = model(X_test)
# - model(X_test):
# - 학습된 모델에 테스트 데이터 X_test를 입력하여 예측값을 계산.
# - X_test: 테스트 데이터의 입력(특성)으로, 크기는 `(테스트 샘플 수, 64)`입니다.
# - y_pred: 모델이 예측한 각 샘플의 출력값(로짓)으로, 크기는 `(테스트 샘플 수, 10)`입니다.
# - 10개의 출력값은 각 숫자(0~9)에 대한 "확신도"를 나타내는 값입니다.
# - 아직 소프트맥스(Softmax)를 적용하지 않았으므로 확률로 해석되지 않습니다.
y_pred[10]
# - y_pred[10]:
# - 테스트 데이터의 10번째 샘플에 대한 모델의 예측값(로짓)을 출력합니다.
# - 출력 크기: `(10,)`.
# - 10개의 숫자(0~9) 각각에 대해 모델이 예측한 로짓 값(확신도)을 나타냅니다.
# - 예: `y_pred[10]`의 값이 `[2.3, 1.1, -0.5, 4.8, ...]`이라면,
# - 숫자 `3`(인덱스 3)과 관련된 로짓 값 `4.8`이 가장 크므로 모델은 `3`으로 예측.
--->
tensor([ -4.4669, -10.2166, -5.4808, -1.4613, -5.2322, 12.2385, -8.6079,
1.6917, 2.3353, -8.2548], grad_fn=<SelectBackward0>)
예시 6)
# 모델 출력값에 소프트맥스 함수 적용 및 확률 계산
y_prob = nn.Softmax(1)(y_pred)
# - nn.Softmax(dim=1):
# - PyTorch의 소프트맥스 함수.
# - 입력값(y_pred)에 소프트맥스를 적용하여 클래스별 확률을 계산.
# - dim=1:
# - 출력값(y_pred)의 두 번째 차원(클래스 차원)에서 소프트맥스를 계산.
# - 소프트맥스 공식:
# P(y_i) = exp(y_i) / Σ(exp(y_j))
# - exp(y_i): i번째 클래스의 지수 연산 결과.
# - Σ(exp(y_j)): 모든 클래스의 지수 연산 결과의 합.
# - y_prob:
# - 모델이 예측한 각 클래스의 확률.
# - 크기: `(테스트 샘플 수, 10)` (샘플 수 x 클래스 수).
# - 각 행의 합은 1 (모든 클래스 확률의 합은 항상 1).
y_prob[10]
# - y_prob[10]:
# - 테스트 데이터의 10번째 샘플에 대해 소프트맥스를 적용한 클래스별 확률.
# - 크기: `(10,)`.
# - 각 요소는 해당 클래스에 대한 확률을 나타냅니다.
--->
tensor([5.5579e-08, 1.7696e-10, 2.0165e-08, 1.1226e-06, 2.5857e-08, 9.9992e-01,
8.8407e-10, 2.6276e-05, 5.0011e-05, 1.2586e-09],
grad_fn=<SelectBackward0>)
예시 7)
# 10번째 테스트 샘플의 클래스별 확률 출력
for i in range(10): # 0부터 9까지 반복 (클래스 번호)
print(f'숫자 {i}일 확률: {y_prob[10][i]:.2f}')
# - f-string:
# - 문자열 포매팅을 사용하여 클래스 번호(i)와 해당 확률(y_prob[10][i])을 출력.
# - y_prob[10]:
# - 10번째 테스트 샘플의 클래스별 확률.
# - y_prob[10][i]:
# - 10번째 샘플이 클래스 i에 속할 확률.
# - :.2f:
# - 확률을 소수점 둘째 자리까지 포매팅.
--->
숫자 0일 확률: 0.00
숫자 1일 확률: 0.00
숫자 2일 확률: 0.00
숫자 3일 확률: 0.00
숫자 4일 확률: 0.00
숫자 5일 확률: 1.00
숫자 6일 확률: 0.00
숫자 7일 확률: 0.00
숫자 8일 확률: 0.00
숫자 9일 확률: 0.00
예시 8)
# 모델의 테스트 데이터 예측값 계산 및 정확도 측정
y_pred_index = torch.argmax(y_prob, axis=1)
# - torch.argmax(y_prob, axis=1):
# - 소프트맥스를 통해 계산된 클래스 확률(y_prob)에서 가장 높은 확률을 가진 클래스의 인덱스를 반환.
# - axis=1: 각 샘플(행)에서 확률이 가장 높은 클래스의 인덱스를 계산.
# - y_pred_index: 테스트 데이터의 각 샘플에 대해 모델이 예측한 클래스 번호.
accuracy = (y_test == y_pred_index).float().sum() / len(y_test) * 100
# - (y_test == y_pred_index):
# - 테스트 데이터의 실제 레이블(y_test)과 모델이 예측한 레이블(y_pred_index)을 비교.
# - 각 샘플에 대해 예측이 맞으면 `True`, 틀리면 `False`.
# - .float():
# - `True`와 `False`를 각각 1.0과 0.0으로 변환.
# - .sum():
# - 예측이 맞은 샘플의 개수를 계산.
# - len(y_test):
# - 테스트 데이터의 전체 샘플 수를 반환.
# - 정확도 계산:
# - (정확히 예측한 샘플 수 / 전체 샘플 수) * 100
# - 정확도를 백분율로 표현.
print(f'테스트 정확도는 {accuracy: .2f}% 입니다.')
# - f-string:
# - 계산된 정확도를 소수점 둘째 자리까지 포매팅하여 출력.
# - {accuracy: .2f}: 정확도를 소수점 둘째 자리까지 포매팅.
--->
테스트 정확도는 95.56% 입니다.
3. 데이터 증강
* 데이터 증강(Data Augmentation)은 학습 데이터를 인위적으로 변환하여 데이터셋의 다양성을 높이고 모델의 일반화 성능을 향상시키는 기법입니다.
* 회전, 크기 조정, 반전, 블러링, 밝기 조정 등 다양한 변환을 적용하여 원본 데이터로부터 새로운 데이터를 생성합니다.
* 이를 통해 데이터 부족 문제를 완화하고 모델이 특정 패턴에 과적합되지 않도록 도와줍니다.
* 특히, 이미지나 음성 데이터와 같이 특징이 직관적인 데이터에서 효과적으로 활용되며, 증강된 데이터는 모델이 예측 대상의 다양한 변형에 대해 강하게 학습할 수 있도록 돕습니다.
예제 1)
# 필요한 PyTorch 모듈 임포트
from torchvision import transforms # 데이터 전처리 및 변환(transform)을 위한 라이브러리
from torch.utils.data import TensorDataset # 텐서 데이터를 위한 Dataset 클래스
from torch.utils.data import Dataset # PyTorch의 데이터셋 클래스 기반 구현
# 학습 데이터와 테스트 데이터를 분리
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.3, random_state=2025)
# - train_test_split():
# - 데이터를 학습 데이터와 테스트 데이터로 나눕니다.
# - 매개변수:
# - X_data: 입력 데이터(손글씨 이미지 데이터).
# - y_data: 타겟 데이터(숫자 레이블).
# - test_size=0.3:
# - 전체 데이터 중 30%를 테스트 데이터로, 나머지 70%를 학습 데이터로 사용.
# - random_state=2025:
# - 난수 생성 시드를 설정하여 데이터를 나누는 방식을 고정.
# - 동일한 입력 데이터로 항상 같은 결과를 얻을 수 있습니다.
# - 반환 값:
# - X_train: 학습 데이터의 입력(70%).
# - X_test: 테스트 데이터의 입력(30%).
# - y_train: 학습 데이터의 타겟 레이블.
# - y_test: 테스트 데이터의 타겟 레이블.
# 데이터 형태 출력
print(X_train.shape, X_test.shape)
# - 학습 데이터와 테스트 데이터의 입력 크기를 출력.
# - 결과는 각각 (샘플 수, 특성 수) 형태로 나타남.
print(y_train.shape, y_test.shape)
# - 학습 데이터와 테스트 데이터의 타겟 레이블 크기를 출력.
# - 결과는 각각 (샘플 수,) 형태로 나타남.
--->
torch.Size([1257, 64]) torch.Size([540, 64])
torch.Size([1257]) torch.Size([540])
예제 2)
# TensorDataset 생성
train_dataset = TensorDataset(X_train, y_train)
# - TensorDataset:
# - 입력 데이터(X_train)와 타겟 데이터(y_train)를 묶어서 하나의 데이터셋 객체로 생성.
# - 각 샘플은 (입력 데이터, 타겟 레이블)로 구성됨.
# - 학습 데이터를 PyTorch의 DataLoader와 함께 사용하기 위한 준비.
test_dataset = TensorDataset(X_test, y_test)
# - 테스트 데이터(X_test)와 타겟 데이터(y_test)를 묶어서 하나의 데이터셋 객체로 생성.
# - 테스트 데이터셋은 학습된 모델의 성능 평가에 사용.
# 데이터 변환(transform) 정의
transform = transforms.Compose([
transforms.RandomRotation(10), # 이미지를 -10도에서 10도 사이로 무작위 회전
transforms.RandomAffine(0, shear=5, scale=(0.9, 1.1)),
# - RandomAffine:
# - 이미지에 무작위 변환 적용.
# - shear=5: 이미지를 기울이는 변환을 -5도에서 5도 사이로 적용.
# - scale=(0.9, 1.1): 이미지 크기를 0.9배에서 1.1배 사이로 무작위로 변경.
])
### transforms.Compose
여러 데이터 변환(transform) 작업을 순차적으로 적용할 수 있도록 해줍니다.
이미지 데이터 전처리와 증강 과정에서 자주 사용되며, 각 변환을 하나의 리스트로 묶어 실행합니다.
1. transforms.RandomRotation(10)
* 기능: 이미지를 -10도에서 +10도 사이로 무작위 회전시킵니다.
10은 회전 범위를 나타냅니다.
각 호출 시, -10도 ~ +10도 범위에서 무작위로 각도를 선택하여 이미지를 회전합니다.
2. transforms.RandomAffine(0, shear=5, scale=(0.9, 1.1))
* 기능: 이미지를 비틀기(shear), 크기 조정(scale) 등의 변환을 수행합니다.
* 0: 회전(각도) 변환을 수행하지 않음을 의미합니다.
* shear=5: 이미지를 최대 5도만큼 비스듬하게 비틀기(shear) 변환을 수행합니다.
* 예: 정사각형이 평행사변형처럼 기울어질 수 있습니다.
* scale=(0.9, 1.1):
* 이미지를 0.9배(축소)에서 1.1배(확대) 범위 내에서 무작위 크기 조정을 수행합니다.
* 각 호출 시, 무작위로 크기가 변경됩니다.
예시 1)
# AugmentedDataset 클래스 정의
# - PyTorch의 Dataset 클래스를 상속받아 데이터셋에 변환(transform)을 적용하는 커스텀 데이터셋을 구현.
class AugmentedDataset(Dataset): # Dataset 클래스 상속
def __init__(self, dataset, transform):
# 초기화 메서드
# - dataset: 원본 데이터셋 (TensorDataset 등).
# - transform: 적용할 변환(transform).
self.dataset = dataset # 원본 데이터셋 저장
self.transform = transform # 변환(transform) 저장
def __len__(self):
# 데이터셋의 길이를 반환
return len(self.dataset)
def __getitem__(self, idx):
# 인덱스를 사용해 데이터셋에서 샘플을 가져오고 변환을 적용
x, y = self.dataset[idx] # 원본 데이터셋에서 입력(x)과 타겟(y)을 가져옴
x = x.view(8, 8).unsqueeze(0)
# - x.view(8, 8): 입력 데이터 x를 (8, 8) 크기의 2D 텐서로 변환.
# - unsqueeze(0): 채널 차원 추가하여 (8, 8) -> (1, 8, 8).
# - PyTorch 변환(transform)은 입력 데이터에 채널 차원(C, H, W)을 기대.
x = self.transform(x)
# - 변환(transform)을 입력 데이터 x에 적용.
# - 예: RandomRotation, RandomAffine 등의 변환.
return x.flatten(), y
# - x.flatten(): 변환 후 데이터를 다시 1D 벡터(64차원)로 변환.
# - y: 변환과 관계없이 타겟 레이블은 그대로 반환.
예시 2)
# AugmentedDataset 객체 생성 (학습 데이터에 데이터 증강 적용)
augmented_train_dataset = AugmentedDataset(train_dataset, transform)
# - AugmentedDataset:
# - 학습 데이터셋(train_dataset)에 정의된 변환(transform)을 적용하여 데이터 증강 수행.
# - 데이터 증강은 학습 데이터에서만 사용되며, 테스트 데이터에는 적용하지 않음.
# DataLoader 생성
train_loader = DataLoader(augmented_train_dataset, batch_size=64, shuffle=True)
# - 학습 데이터의 DataLoader 생성.
# - augmented_train_dataset: 데이터 증강이 적용된 학습 데이터셋.
# - batch_size=64: 한 번에 64개의 샘플을 배치로 로드.
# - shuffle=True: 데이터셋을 무작위로 섞어서 로드.
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# - 테스트 데이터의 DataLoader 생성.
# - test_dataset: 데이터 증강이 적용되지 않은 원본 테스트 데이터셋.
# - batch_size=64: 한 번에 64개의 샘플을 배치로 로드.
# - shuffle=False: 데이터 순서를 유지하며 로드.
# 학습 데이터의 첫 번째 배치 가져오기
imgs, labels = next(iter(train_loader))
# - iter(train_loader): train_loader에서 반복자를 생성.
# - next(): 반복자에서 첫 번째 배치를 가져옴.
# - imgs: 첫 번째 배치의 입력 데이터 (이미지).
# - labels: 첫 번째 배치의 타겟 데이터 (레이블).
# 이미지와 레이블을 시각화하기 위한 서브플롯 생성
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
# - plt.subplots():
# - 8행 8열의 서브플롯 배열 생성.
# - figsize=(14, 14): 전체 플롯 크기를 설정 (단위: 인치).
# 배치에서 가져온 이미지와 레이블을 시각화
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape((8, 8)), cmap='gray')
# - img.reshape((8, 8)): 입력 데이터 img를 8x8 형태로 변환.
# - cmap='gray': 이미지를 흑백(그레이스케일)으로 표시.
ax.set_title(str(label))
# - set_title(): 현재 서브플롯의 제목(레이블) 설정.
ax.axis('off')
# - axis('off'): 축 눈금과 축선을 제거하여 이미지만 표시.---->

예시 3)
# DataLoader에서 한 배치를 가져와 입력 데이터와 레이블의 크기를 출력
for images, labels in loader:
# - DataLoader(loader)에서 배치 단위로 데이터를 가져오는 반복문.
# - images: 한 배치의 입력 데이터.
# - labels: 한 배치의 타겟 데이터(레이블).
print(f'Image batch shape: {images.shape}')
# - images.shape:
# - 입력 데이터(images)의 크기 출력.
# - 결과는 `(배치 크기, 특성 수)` 형태로 표시.
# - 예: `(64, 64)`는 배치 크기가 64이고, 각 데이터 포인트는 64차원(1D 벡터)임을 의미.
print(f'Label batch shape: {labels.shape}')
# - labels.shape:
# - 타겟 데이터(labels)의 크기 출력.
# - 결과는 `(배치 크기,)` 형태로 표시.
# - 예: `(64,)`는 배치 크기가 64이고, 각 레이블은 하나의 값으로 표현됨.
break # 첫 번째 배치만 확인 후 반복 종료
예시 4)
# 모델 정의
model = nn.Sequential(
nn.Linear(64, 10) # 입력 64차원, 출력 10차원 (0~9 숫자 분류)
)
# - nn.Linear(64, 10): 선형 계층(fully connected layer)로, 입력 데이터를 64차원에서 10차원으로 변환.
# - nn.Sequential: 계층을 순차적으로 쌓아 신경망 모델을 정의.
# Adam 옵티마이저 정의
optimizer = optim.Adam(model.parameters(), lr=0.01)
# - model.parameters(): 모델의 학습 가능한 매개변수를 가져옴.
# - lr=0.01: 학습률(learning rate)로 매개변수 업데이트 크기를 설정.
# - optim.Adam: 학습률을 자동으로 조정하는 Adam 최적화 알고리즘 사용.
# 학습 반복 횟수(에포크) 설정
epochs = 50
# 학습 루프
for epoch in range(epochs + 1): # 0부터 epochs까지 학습 반복
sum_losses = 0 # 현재 에포크의 총 손실값 초기화
sum_accs = 0 # 현재 에포크의 총 정확도 초기화
# 배치 단위 학습
for x_batch, y_batch in loader: # DataLoader에서 배치 단위로 데이터 가져오기
y_pred = model(x_batch) # 모델에 입력 데이터를 전달하여 예측값 계산
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
# - nn.CrossEntropyLoss():
# - 소프트맥스와 교차 엔트로피 손실을 결합하여 다중 클래스 분류 문제에서 사용하는 손실 함수.
# - 예측값과 실제값 간의 차이를 계산.
optimizer.zero_grad() # 이전 그래디언트 초기화
loss.backward() # 손실값을 기반으로 그래디언트 계산(역전파)
optimizer.step() # 계산된 그래디언트를 사용하여 매개변수 업데이트
sum_losses = sum_losses + loss # 현재 배치의 손실값을 총 손실값에 누적
y_prob = nn.Softmax(1)(y_pred) # 예측값에 소프트맥스 적용하여 클래스 확률 계산
y_pred_index = torch.argmax(y_prob, axis=1) # 가장 높은 확률을 가진 클래스 인덱스 계산
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
# - 정확도 계산:
# - (정답 레이블과 예측 레이블이 일치한 개수) / (배치 크기) * 100
sum_accs = sum_accs + acc # 현재 배치의 정확도를 총 정확도에 누적
if epoch % 10 == 0: # 10 에포크마다 결과 출력
avg_loss = sum_losses / len(loader) # 평균 손실값 계산
avg_acc = sum_accs / len(loader) # 평균 정확도 계산
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
# - 에포크 번호, 평균 손실값, 평균 정확도를 출력
--->
Epoch 0/50 Loss: 2.067507 Accuracy: 54.90%
Epoch 10/50 Loss: 0.054456 Accuracy: 98.59%
Epoch 20/50 Loss: 0.026466 Accuracy: 99.69%
Epoch 30/50 Loss: 0.015163 Accuracy: 99.80%
Epoch 40/50 Loss: 0.010221 Accuracy: 100.00%
Epoch 50/50 Loss: 0.012127 Accuracy: 99.84%
예시 5)
# 테스트 데이터의 11번째 샘플을 시각화하고 해당 타겟 레이블 출력
plt.imshow(X_test[11].reshape((8, 8)), cmap='gray')
# - plt.imshow():
# - 이미지를 시각화하기 위한 matplotlib 함수.
# - X_test[11]:
# - 테스트 데이터에서 11번째 샘플의 입력 데이터.
# - 테스트 데이터는 1차원(64차원) 형태로 저장되어 있음.
# - .reshape((8, 8)):
# - 1차원 데이터를 8x8 크기의 2D 텐서(이미지 형태)로 변환.
# - cmap='gray':
# - 이미지를 흑백(그레이스케일)으로 표시.
print(y_test[11])
# - y_test[11]:
# - 테스트 데이터의 11번째 샘플에 대한 실제 타겟 레이블(숫자 0~9)을 출력.
--->
tensor(7)--->

예시 6)
# 테스트 데이터에 대한 모델의 예측값 계산
y_pred = model(X_test)
# - model(X_test):
# - 학습된 모델에 테스트 데이터 X_test를 입력하여 예측값 계산.
# - X_test: 테스트 데이터의 입력 (크기: [샘플 수, 64]).
# - y_pred: 모델이 예측한 각 샘플의 출력값(로짓)으로, 크기 [샘플 수, 10].
# - 각 행은 10개의 값으로, 각 클래스(숫자 0~9)에 대한 모델의 "확신도"를 나타냄.
# - 로짓(logit)은 소프트맥스를 적용하기 전의 값으로, 확률이 아님.
y_pred[11]
# - y_pred[11]:
# - 테스트 데이터에서 11번째 샘플에 대한 모델의 예측값(로짓) 출력.
# - 크기: [10] (숫자 0~9에 대한 예측값).
# - 예: [2.3, 1.1, -0.5, 4.8, ...]이라면:
# - 숫자 `3`(인덱스 3)과 관련된 값 `4.8`이 가장 크므로, 모델은 `3`을 예측.
--->
tensor([-11.7670, -7.4305, 0.5514, 3.6504, -3.0022, -3.4467, -16.6290,
16.6521, -7.6715, -0.0978], grad_fn=<SelectBackward0>)
예시 7)
# 테스트 데이터에 대한 모델 예측값을 소프트맥스 함수로 확률로 변환
y_prob = nn.Softmax(1)(y_pred)
# - nn.Softmax(dim=1):
# - PyTorch의 소프트맥스 함수.
# - 입력값(y_pred)에 소프트맥스를 적용하여 클래스별 확률을 계산.
# - dim=1:
# - 각 샘플(행)에서 클래스별 확률을 계산.
# - 소프트맥스 공식:
# P(y_i) = exp(y_i) / Σ(exp(y_j))
# - exp(y_i): i번째 클래스의 지수 연산 결과.
# - Σ(exp(y_j)): 모든 클래스의 지수 연산 결과의 합.
# - y_prob:
# - 모델이 예측한 각 클래스의 확률.
# - 크기: `(테스트 샘플 수, 10)` (샘플 수 x 클래스 수).
# - 각 행의 합은 1 (모든 클래스 확률의 합은 항상 1).
y_prob[11]
# - y_prob[11]:
# - 테스트 데이터의 11번째 샘플에 대해 소프트맥스를 적용한 클래스별 확률.
# - 크기: `(10,)`.
# - 각 요소는 해당 클래스에 대한 확률을 나타냅니다.
--->
tensor([4.5471e-13, 3.4758e-11, 1.0175e-07, 2.2565e-06, 2.9123e-09, 1.8673e-09,
3.5170e-15, 1.0000e+00, 2.7315e-11, 5.3164e-08],
grad_fn=<SelectBackward0>)
예시 8)
# 테스트 데이터의 11번째 샘플에 대한 클래스별 확률을 출력
for i in range(10): # 0부터 9까지 반복 (클래스 번호)
print(f'숫자 {i}일 확률 : {y_prob[11][i]:.2f}')
# - f-string:
# - 문자열 포매팅을 사용하여 클래스 번호(i)와 해당 클래스 확률(y_prob[11][i])을 출력.
# - y_prob[11][i]:
# - 테스트 데이터의 11번째 샘플이 클래스 i에 속할 확률.
# - :.2f:
# - 확률 값을 소수점 둘째 자리까지 포매팅.
---->
숫자 0일 확률 : 0.00
숫자 1일 확률 : 0.00
숫자 2일 확률 : 0.00
숫자 3일 확률 : 0.00
숫자 4일 확률 : 0.00
숫자 5일 확률 : 0.00
숫자 6일 확률 : 0.00
숫자 7일 확률 : 1.00
숫자 8일 확률 : 0.00
숫자 9일 확률 : 0.00'LLM(Large Language Model)의 기초 > 데이터 분석' 카테고리의 다른 글
| 16. 슈퍼스토어 마케팅 캠페인 데이터셋 (2) | 2025.01.10 |
|---|---|
| 15. 호텔 예약 수요 데이터셋 (2) | 2025.01.09 |
| 14. 파이토치로 구현한 논리 회귀 (2) | 2025.01.08 |
| 13. 서울 자전거 공유 수요 예측 데이터셋 (0) | 2025.01.08 |
| 12. 주택 임대료 예측 데이터셋 (0) | 2025.01.07 |