1. 슈퍼스토어 마케팅 캠페인 데이터셋
데이터셋은 Superstore 마케팅 캠페인 데이터를 포함하고 있으며, 고객의 인구통계학적 정보(예: 출생 연도, 학력, 결혼 상태, 소득), 가구 구성(어린이와 십대 자녀 수), 구매 기록(와인, 육류, 생선 등 다양한 제품군에 대한 지출), 구매 채널(매장, 웹사이트, 카탈로그), 그리고 고객의 마케팅 캠페인 참여 여부 및 불만 기록 등을 담고 있습니다. 이 데이터는 고객의 행동 패턴과 마케팅 전략의 효과를 분석하는 데 유용합니다
링크 : https://www.kaggle.com/datasets/ahsan81/superstore-marketing-campaign-dataset
Superstore Marketing Campaign Dataset
Sample customer data for analysis of a targeted Membership Offer
www.kaggle.com
2. 데이터셋 컬럼 설명
* ID: 각 고객의 고유 식별 번호입니다. 데이터에서 고객을 구별하기 위한 유일한 값입니다.
* Year_Birth: 고객의 출생 연도입니다. 이 값을 사용해 고객의 나이를 계산할 수 있습니다.
* Complain: 지난 2년간 고객이 불만을 제기한 적이 있는지를 나타냅니다.
* 1: 불만을 제기한 적 있음.
* 0: 불만을 제기한 적 없음.
* Dt_Customer: 고객이 회사와 거래를 시작한 날짜입니다. 고객 충성도 또는 거래 기간 분석에 활용할 수 있습니다.
* Education: 고객의 학력 수준입니다.
* 예: 고졸, 대졸, 대학원 졸업 등.
* Marital: 고객의 결혼 상태를 나타냅니다.
* 예: 독신(Single), 기혼(Married), 이혼(Divorced) 등.
* Kidhome: 고객 가정에 있는 어린 아이(소아)의 수를 나타냅니다. 나이가 어린 자녀의 수를 분석하는 데 유용합니다.
* Teenhome: 고객 가정에 있는 십대 자녀의 수를 나타냅니다. 십대 자녀 수와 구매 행동 간의 관계를 분석할 수 있습니다.
* Income: 고객 가정의 연간 가계 소득입니다. 구매력이나 소비 패턴을 분석하는 중요한 변수입니다.
* MntFishProducts: 지난 2년 동안 생선 제품에 지출한 금액입니다.
* MntMeatProducts: 지난 2년 동안 육류 제품에 지출한 금액입니다.
* MntFruits: 지난 2년 동안 과일 제품에 지출한 금액입니다.
* MntSweetProducts: 지난 2년 동안 디저트(단 제품)에 지출한 금액입니다.
* MntWines: 지난 2년 동안 와인 제품에 지출한 금액입니다.
* MntGoldProds: 지난 2년 동안 금으로 된 제품에 지출한 금액입니다. 고가 상품 소비 경향을 분석할 수 있습니다.
* NumDealsPurchases: 할인을 통해 구매한 횟수입니다. 고객이 가격 할인에 민감한지 알 수 있습니다.
* NumCatalogPurchases: 카탈로그를 이용한 구매 횟수입니다. 우편 주문이나 비대면 구매 경향을 나타냅니다.
* NumStorePurchases: 매장에서 직접 구매한 횟수입니다. 오프라인 구매 성향을 분석하는 데 유용합니다.
* NumWebPurchases: 웹사이트를 통해 구매한 횟수입니다. 온라인 구매 경향을 평가할 수 있습니다.
* NumWebVisitsMonth: 지난달 동안 웹사이트를 방문한 횟수입니다. 고객이 웹사이트에서의 관심도를 측정할 수 있습니다.
* Recency: 고객이 마지막으로 구매한 이후 경과한 일수입니다. 고객 재활성화 또는 충성도 분석에 사용됩니다.
3. 데이터 전처리 및 EDA
예시 1)
import 시켜준다
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
예시 2)
# /content/drive/MyDrive/KDT 시즌 4/10. 데이터분석/Data/superstore_data.csv
mkt_df = pd.read_csv('/content/drive/MyDrive/KDT 시즌 4/10. 데이터분석/Data/superstore_data.csv')
mkt_df--->

예시 3)
# mkt_df.info(): 데이터프레임의 요약 정보를 출력하는 메서드입니다.
# mkt_df는 pandas 데이터프레임으로 가정합니다.
mkt_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2240 entries, 0 to 2239
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 2240 non-null int64
1 Year_Birth 2240 non-null int64
2 Education 2240 non-null object
3 Marital_Status 2240 non-null object
4 Income 2216 non-null float64
5 Kidhome 2240 non-null int64
6 Teenhome 2240 non-null int64
7 Dt_Customer 2240 non-null object
8 Recency 2240 non-null int64
9 MntWines 2240 non-null int64
10 MntFruits 2240 non-null int64
11 MntMeatProducts 2240 non-null int64
12 MntFishProducts 2240 non-null int64
13 MntSweetProducts 2240 non-null int64
14 MntGoldProds 2240 non-null int64
15 NumDealsPurchases 2240 non-null int64
16 NumWebPurchases 2240 non-null int64
17 NumCatalogPurchases 2240 non-null int64
18 NumStorePurchases 2240 non-null int64
19 NumWebVisitsMonth 2240 non-null int64
20 Response 2240 non-null int64
21 Complain 2240 non-null int64
dtypes: float64(1), int64(18), object(3)
memory usage: 385.1+ KB
예시 4)
# mkt_df 데이터프레임에서 'Id'라는 열(Column)을 제거합니다.
# axis=1: 열 방향으로 작업을 수행하겠다는 의미입니다(행 방향은 axis=0).
# inplace=True: 기존 데이터프레임(mkt_df)을 직접 수정하여 열을 제거합니다.
# 결과적으로 'Id' 열은 데이터프레임에서 삭제되며, 새로운 데이터프레임을 생성하지 않습니다.
mkt_df.drop('Id', axis=1, inplace=True)
예시 5)
# mkt_df.describe(): 데이터프레임의 숫자형 열에 대한 요약 통계 정보를 제공합니다.
# 주요 통계 지표:
# 1. count: 각 열에 있는 비결측값(Non-Null 값)의 개수.
# 2. mean: 각 열의 평균 값.
# 3. std: 각 열의 표준편차(Standard Deviation).
# 4. min: 각 열의 최솟값.
# 5. 25%: 각 열의 1사분위수(25번째 백분위 값).
# 6. 50%: 각 열의 중앙값(2사분위수, 50번째 백분위 값).
# 7. 75%: 각 열의 3사분위수(75번째 백분위 값).
# 8. max: 각 열의 최댓값.
mkt_df.describe()---->

예시 6)
# mkt_df.sort_values('Year_Birth'):
# 'Year_Birth' 열을 기준으로 데이터프레임 mkt_df의 행을 정렬합니다.
# 기본적으로 오름차순(ascending=True)으로 정렬됩니다.
# 정렬된 결과는 새로운 데이터프레임으로 반환되며, 원본 데이터프레임 mkt_df는 수정되지 않습니다.
mkt_df.sort_values('Year_Birth')--->

예시 7)
# mkt_df.sort_values('Income', ascending=False):
# 'Income' 열을 기준으로 데이터프레임 mkt_df의 행을 정렬합니다.
# ascending=False: 내림차순으로 정렬합니다(값이 큰 순서대로 정렬).
# 정렬된 결과는 새로운 데이터프레임으로 반환되며, 원본 데이터프레임 mkt_df는 수정되지 않습니다.
mkt_df.sort_values('Income', ascending=False)
예시 8)
# mkt_df = mkt_df[mkt_df['Income'] < 200000]
# 주석 처리된 코드는 'Income' 값이 200,000보다 작은 데이터만 필터링하여 mkt_df에 저장하는 작업입니다.
# 그러나 이 방식은 NaN 값(결측값)도 제거되기 때문에 사용하지 않을 수도 있습니다.
# mkt_df = mkt_df[mkt_df['Income'] != 666666]
# 'Income' 값이 666,666인 데이터를 필터링하여 제거합니다.
# 즉, 'Income' 값이 666,666이 아닌 데이터만 mkt_df에 남게 됩니다.
# 이 방법은 실수로 값을 표현할 필요 없이 특정 값을 정확히 제거하는 데 유용합니다.
# mkt_df.sort_values('Income', ascending=False)
# 'Income' 열을 기준으로 데이터를 내림차순으로 정렬합니다.
# 즉, 높은 수입 값을 가진 행이 위쪽에 오고, 낮은 수입 값이 아래쪽에 위치합니다.
# 정렬된 데이터는 새로운 데이터프레임으로 반환되며, 원본 mkt_df는 변경되지 않습니다.
mkt_df = mkt_df[mkt_df['Income'] != 666666]
mkt_df.sort_values('Income', ascending=False)--->

예시 9)
# mkt_df.isna():
# 데이터프레임 mkt_df의 각 셀에 대해 결측값(NaN)이 있는지 여부를 확인합니다.
# 각 셀에 대해:
# - 값이 결측값(NaN)인 경우: True
# - 값이 결측값이 아닌 경우: False
# 결과는 동일한 크기의 데이터프레임으로 반환됩니다.
# mkt_df.isna().sum():
# 각 열(Column)별로 결측값(True로 표시된 값)의 개수를 합산합니다.
# 즉, 각 열에 존재하는 결측값의 총 개수를 반환합니다.
mkt_df.isna().sum()--->

예시 10)
# mkt_df.isna():
# 데이터프레임 mkt_df의 각 셀에 대해 결측값(NaN)이 있는지 여부를 확인합니다.
# 각 셀에 대해:
# - 값이 결측값(NaN)인 경우: True
# - 값이 결측값이 아닌 경우: False
# 결과는 동일한 크기의 데이터프레임으로 반환됩니다.
# mkt_df.isna().mean():
# 각 열(Column)별로 결측값(True로 표시된 값)의 비율(평균)을 계산합니다.
# - True는 숫자 1로 취급되고, False는 숫자 0으로 취급됩니다.
# - mean()은 각 열에 대해 True의 비율을 계산합니다.
# 결과는 각 열에서 결측값이 차지하는 비율(0.0 ~ 1.0)을 반환합니다.
mkt_df.isna().mean()--->

예시 11)
# mkt_df.dropna():
# 데이터프레임 mkt_df에서 결측값(NaN)이 포함된 행을 제거합니다.
# 기본적으로 결측값이 있는 **모든 행**이 삭제됩니다.
# 결과는 결측값이 제거된 새로운 데이터프레임이 반환됩니다.
# mkt_df = mkt_df.dropna():
# 결측값이 제거된 데이터프레임을 원본 변수 mkt_df에 다시 할당합니다.
# 즉, 결측값(NaN)이 있는 행은 mkt_df에서 완전히 삭제됩니다.
# 주의:
# 이 작업은 결측값이 하나라도 포함된 행 전체를 삭제하므로,
# 중요한 데이터가 함께 삭제될 가능성이 있습니다.
# 데이터가 손실되지 않도록 이 작업 전에 반드시 데이터를 확인해야 합니다.
mkt_df = mkt_df.dropna()
예시 12)
# mkt_df.isna():
# 데이터프레임 mkt_df의 각 셀에 대해 결측값(NaN)이 있는지 확인합니다.
# - 값이 결측값(NaN)인 경우: True
# - 값이 결측값이 아닌 경우: False
# 결과는 동일한 크기의 데이터프레임으로 반환됩니다.
# mkt_df.isna().mean():
# 각 열(Column)별로 결측값(True로 표시된 값)의 비율(평균)을 계산합니다.
# - True는 숫자 1로 간주되고, False는 숫자 0으로 간주됩니다.
# - mean()은 각 열에서 True(결측값)의 평균 값을 계산합니다.
# 결과:
# - 0.0 ~ 1.0 사이의 값으로 반환되며,
# - 특정 열에서 결측값이 전체 값 중 몇 퍼센트인지 나타냅니다.
mkt_df.isna().mean()--->

예시 13)
# mkt_df.info():
# 데이터프레임 mkt_df의 요약 정보를 출력합니다.
# 이 메서드는 데이터프레임의 구조와 데이터 상태를 간단히 파악할 수 있도록 도와줍니다.
# 출력되는 주요 정보:
# 1. 데이터프레임의 행(Row) 개수와 열(Column) 개수.
# 2. 각 열의 이름(Column Name).
# 3. 각 열에 포함된 결측값을 제외한 데이터 개수(Non-Null Count).
# 4. 각 열의 데이터 타입(Dtype): int64, float64, object 등.
# 5. 데이터프레임의 메모리 사용량(Memory Usage).
mkt_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 2215 entries, 0 to 2239
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2215 non-null int64
1 Education 2215 non-null object
2 Marital_Status 2215 non-null object
3 Income 2215 non-null float64
4 Kidhome 2215 non-null int64
5 Teenhome 2215 non-null int64
6 Dt_Customer 2215 non-null object
7 Recency 2215 non-null int64
8 MntWines 2215 non-null int64
9 MntFruits 2215 non-null int64
10 MntMeatProducts 2215 non-null int64
11 MntFishProducts 2215 non-null int64
12 MntSweetProducts 2215 non-null int64
13 MntGoldProds 2215 non-null int64
14 NumDealsPurchases 2215 non-null int64
15 NumWebPurchases 2215 non-null int64
16 NumCatalogPurchases 2215 non-null int64
17 NumStorePurchases 2215 non-null int64
18 NumWebVisitsMonth 2215 non-null int64
19 Response 2215 non-null int64
20 Complain 2215 non-null int64
dtypes: float64(1), int64(17), object(3)
memory usage: 380.7+ KB
예시 14)
# mkt_df['Dt_Customer']:
# 데이터프레임 mkt_df의 'Dt_Customer' 열을 선택합니다.
# 이 열은 고객의 특정 날짜 정보(예: 가입 날짜)가 포함된 문자열 형식일 가능성이 높습니다.
# pd.to_datetime(mkt_df['Dt_Customer']):
# pandas의 to_datetime() 함수를 사용하여 'Dt_Customer' 열의 데이터를 날짜/시간(datetime) 형식으로 변환합니다.
# - 'Dt_Customer' 열에 문자열 형식(예: "2023-01-01") 또는 다른 날짜 형식(예: "01-01-2023")이 포함되어 있다면,
# 이를 pandas에서 처리할 수 있는 datetime 객체로 변환합니다.
# - datetime 형식으로 변환하면 날짜 계산, 비교, 정렬 등의 작업이 더 쉽게 수행됩니다.
# mkt_df['Dt_Customer'] =:
# 변환된 datetime 데이터를 다시 원래 'Dt_Customer' 열에 저장합니다.
# 결과적으로, 'Dt_Customer' 열의 값은 datetime 형식으로 업데이트됩니다.
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'])
--->
<ipython-input-14-51c2edf49ec9>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'])
예시 15)
# mkt_df.info():
# 데이터프레임 mkt_df의 구조와 데이터를 요약하여 출력합니다.
# 이 메서드는 데이터의 크기, 열(Column) 정보, 결측값 개수, 데이터 타입(Dtype) 등을 한눈에 파악할 수 있도록 도와줍니다.
# 출력 정보:
# 1. 데이터프레임의 총 행(Row) 개수와 열(Column) 개수.
# 2. 각 열의 이름(Column Name).
# 3. 각 열의 비결측값(Non-Null 값)의 개수.
# 4. 각 열의 데이터 타입(Dtype): int64, float64, object, datetime 등.
# 5. 데이터프레임이 사용하는 총 메모리 크기(Memory Usage).
mkt_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 2215 entries, 0 to 2239
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2215 non-null int64
1 Education 2215 non-null object
2 Marital_Status 2215 non-null object
3 Income 2215 non-null float64
4 Kidhome 2215 non-null int64
5 Teenhome 2215 non-null int64
6 Dt_Customer 2215 non-null datetime64[ns]
7 Recency 2215 non-null int64
8 MntWines 2215 non-null int64
9 MntFruits 2215 non-null int64
10 MntMeatProducts 2215 non-null int64
11 MntFishProducts 2215 non-null int64
12 MntSweetProducts 2215 non-null int64
13 MntGoldProds 2215 non-null int64
14 NumDealsPurchases 2215 non-null int64
15 NumWebPurchases 2215 non-null int64
16 NumCatalogPurchases 2215 non-null int64
17 NumStorePurchases 2215 non-null int64
18 NumWebVisitsMonth 2215 non-null int64
19 Response 2215 non-null int64
20 Complain 2215 non-null int64
dtypes: datetime64[ns](1), float64(1), int64(17), object(2)
memory usage: 380.7+ KB
예시 16)
# Dt_Customer 기준으로 Dt_Customer의 마지막 가입일과의 차를 구하기
# 단, 월 단위로 계산
# 1. mkt_df['Dt_Customer'].max():
# Dt_Customer 열에서 가장 최근 날짜(최댓값)를 가져옵니다.
# 예: 가장 최근 가입일이 2023-01-01이라면 해당 값을 반환합니다.
# 2. mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month:
# 가장 최근 가입일을 연도와 월로 변환한 뒤, 연도를 월 단위로 변환하여 합산합니다.
# 예: 2023년 1월 → 2023 * 12 + 1 = 24277.
# 3. mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month:
# Dt_Customer 열의 각 행에 대해 연도를 월 단위로 변환하고, 월을 더하여 총 월수를 계산합니다.
# 예: 2022년 12월 → 2022 * 12 + 12 = 24276.
# 4. 최종 계산:
# (가장 최근 가입일의 총 월수) - (각 가입일의 총 월수)
# 두 값의 차이를 구하면, 각 가입일과 가장 최근 가입일 간의 차이를 월 단위로 계산할 수 있습니다.
# 5. 파생 변수 pass_month 생성:
# 계산된 월 차이를 데이터프레임의 새로운 열 'pass_month'에 추가합니다.
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month) - (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month)
# mkt_df.head():
# 데이터프레임의 상위 5개 행을 확인하여, 새로운 열 'pass_month'가 올바르게 추가되었는지 확인합니다.
mkt_df.head()
--->--->

예시 17)
# mkt_df.drop('Dt_Customer', axis=1, inplace=True):
# 데이터프레임 mkt_df에서 'Dt_Customer' 열을 제거합니다.
# 'Dt_Customer': 제거할 열의 이름.
# - 'Dt_Customer' 열은 고객의 가입 날짜를 나타내는 열로, 더 이상 필요 없거나 분석에 사용되지 않는 경우 제거합니다.
# axis=1:
# - 열(Column) 방향으로 작업을 수행하겠다는 의미입니다.
# - 행을 제거하려면 axis=0으로 설정합니다.
# inplace=True:
# - 원본 데이터프레임 mkt_df를 직접 수정합니다.
# - inplace=True를 설정하면 새로운 데이터프레임을 반환하지 않고, 원본 mkt_df가 변경됩니다.
# 결과:
# - 'Dt_Customer' 열이 제거된 데이터프레임이 생성됩니다.
mkt_df.drop('Dt_Customer', axis=1, inplace=True)
예시 18)
mkt_df.head()--->

예시 19)
# 'Total_mnt' 파생 변수 생성:
# 와인, 과일, 육류, 어류, 단맛 제품, 금 제품 구매 금액의 합계를 계산하여 새로운 열 'Total_mnt'에 저장합니다.
# mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']]:
# - 데이터프레임 mkt_df에서 구매 금액과 관련된 6개의 열을 선택합니다.
# 1. 'MntWines': 와인 구매 금액
# 2. 'MntFruits': 과일 구매 금액
# 3. 'MntMeatProducts': 육류 구매 금액
# 4. 'MntFishProducts': 어류 구매 금액
# 5. 'MntSweetProducts': 단맛 제품 구매 금액
# 6. 'MntGoldProds': 금 제품 구매 금액
# .sum(axis=1):
# - 선택한 6개 열의 값을 행(Row) 단위로 합산합니다.
# - axis=1: 행(Row) 방향으로 합계를 계산합니다.
# 예: 각 고객의 총 구매 금액을 계산.
# mkt_df['Total_mnt']:
# - 계산된 합계를 데이터프레임의 새로운 열 'Total_mnt'에 저장합니다.
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts',
'MntFishProducts', 'MntSweetProducts',
'MntGoldProds']].sum(axis=1)
# mkt_df.head():
# 데이터프레임의 상위 5개 행을 출력하여, 새로운 열 'Total_mnt'가 제대로 추가되었는지 확인합니다.
mkt_df.head()
----------------------------------------------------
# 와인 + 과일 + 육류 + 어류 + 단맛 + 금
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts',
'MntFishProducts', 'MntSweetProducts',
'MntGoldProds']].sum(axis=1)
mkt_df.head()
예제 20)
# mkt_df['Children']:
# 데이터프레임 mkt_df에 새로운 열 'Children'을 추가합니다.
# 이 열은 'Kidhome'과 'Teenhome' 열의 합계를 저장합니다.
# 'Children'은 가정 내에 있는 자녀의 총 수를 나타냅니다.
# mkt_df[['Kidhome', 'Teenhome']]:
# - mkt_df 데이터프레임에서 'Kidhome'(어린 자녀 수)와 'Teenhome'(청소년 자녀 수) 열을 선택합니다.
# .sum(axis=1):
# - 선택된 두 열의 값을 행(Row) 단위로 합산합니다.
# - axis=1: 행 단위로 계산한다는 뜻입니다.
# - 결과는 각 행에 대해 'Kidhome'과 'Teenhome' 값의 합이 됩니다.
# 예: 'Kidhome'이 1, 'Teenhome'이 2라면 결과는 1 + 2 = 3입니다.
# 결과:
# - 계산된 합계를 새로운 열 'Children'에 저장합니다.
# - 'Children' 열은 각 가구의 자녀 수(어린 자녀와 청소년 자녀의 합계)를 나타냅니다.
mkt_df['Children'] = mkt_df[['Kidhome', 'Teenhome']].sum(axis=1)
# mkt_df.head():
# 데이터프레임의 상위 5개 행을 출력하여, 새로운 열 'Children'이 제대로 추가되었는지 확인합니다.
mkt_df.head()
mkt_df['Children'] = mkt_df[['Kidhome', 'Teenhome']].sum(axis=1)
mkt_df.head()---->

예제 21)
# mkt_df.drop(['Kidhome', 'Teenhome'], axis=1, inplace=True):
# 데이터프레임 mkt_df에서 'Kidhome' 열과 'Teenhome' 열을 제거합니다.
# ['Kidhome', 'Teenhome']:
# - 제거할 열의 이름을 리스트로 지정합니다.
# - 'Kidhome': 어린 자녀 수를 나타내는 열.
# - 'Teenhome': 청소년 자녀 수를 나타내는 열.
# - 이 두 열은 이미 'Children' 열로 합산된 정보를 포함하고 있기 때문에, 중복 데이터를 제거하려는 의도입니다.
# axis=1:
# - 열(Column) 방향으로 작업을 수행합니다.
# - 즉, 데이터프레임에서 지정된 열을 제거합니다.
# - 행(Row)을 제거하려면 axis=0으로 설정해야 합니다.
# inplace=True:
# - 원본 데이터프레임 mkt_df를 직접 수정합니다.
# - inplace=True를 설정하면 새로운 데이터프레임을 반환하지 않고, 원본 데이터프레임(mkt_df)을 수정합니다.
# 결과:
# - 'Kidhome'과 'Teenhome' 열이 제거된 데이터프레임으로 업데이트됩니다.
mkt_df.drop(['Kidhome', 'Teenhome'], axis=1, inplace=True)
예제 22)
mkt_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 2215 entries, 0 to 2239
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2215 non-null int64
1 Education 2215 non-null object
2 Marital_Status 2215 non-null object
3 Income 2215 non-null float64
4 Recency 2215 non-null int64
5 MntWines 2215 non-null int64
6 MntFruits 2215 non-null int64
7 MntMeatProducts 2215 non-null int64
8 MntFishProducts 2215 non-null int64
9 MntSweetProducts 2215 non-null int64
10 MntGoldProds 2215 non-null int64
11 NumDealsPurchases 2215 non-null int64
12 NumWebPurchases 2215 non-null int64
13 NumCatalogPurchases 2215 non-null int64
14 NumStorePurchases 2215 non-null int64
15 NumWebVisitsMonth 2215 non-null int64
16 Response 2215 non-null int64
17 Complain 2215 non-null int64
18 pass_month 2215 non-null int32
19 Total_mnt 2215 non-null int64
20 Children 2215 non-null int64
dtypes: float64(1), int32(1), int64(17), object(2)
memory usage: 372.1+ KB
예제 23)
# mkt_df['Education']:
# 데이터프레임 mkt_df에서 'Education' 열을 선택합니다.
# 이 열은 고객의 교육 수준을 나타내는 범주형 데이터(Categorical Data)로 구성되어 있을 가능성이 높습니다.
# .value_counts():
# - 선택된 열('Education')에서 각 고유 값이 나타난 빈도(개수)를 계산합니다.
# - 결과는 각 고유 값과 해당 값의 빈도를 나타내는 Series 객체로 반환됩니다.
# - 빈도는 기본적으로 내림차순으로 정렬됩니다(가장 많이 나타난 값이 위에 표시).
# 결과:
# - 'Education' 열에 포함된 각 교육 수준의 고유 값과 빈도수를 보여줍니다.
# - 이를 통해 데이터 분포를 이해하거나, 특정 범주가 얼마나 많은 비중을 차지하는지 확인할 수 있습니다.
mkt_df['Education'].value_counts()--->

예제 24)
# mkt_df['Marital_Status']:
# 데이터프레임 mkt_df에서 'Marital_Status' 열을 선택합니다.
# 이 열은 고객의 결혼 상태(예: 기혼, 미혼 등)를 나타내는 범주형 데이터(Categorical Data)로 구성되어 있을 가능성이 높습니다.
# .value_counts():
# - 선택된 열('Marital_Status')에서 각 고유 값(범주)이 나타난 빈도(개수)를 계산합니다.
# - 결과는 각 고유 값과 해당 값의 빈도를 나타내는 Series 객체로 반환됩니다.
# - 빈도는 기본적으로 내림차순으로 정렬됩니다(가장 많이 나타난 값이 위에 표시).
# 결과:
# - 'Marital_Status' 열에 포함된 각 결혼 상태의 고유 값과 빈도수를 출력합니다.
# - 이를 통해 데이터 분포를 이해하거나, 특정 결혼 상태가 얼마나 많은 비중을 차지하는지 확인할 수 있습니다.
mkt_df['Marital_Status'].value_counts()---->

예제 25)
# mkt_df[~mkt_df['Marital_Status'].isin(['Absurd', 'YOLO'])]:
# - mkt_df 데이터프레임에서 'Marital_Status' 열의 값이 ['Absurd', 'YOLO']에 해당하지 않는 행만 필터링합니다.
# - 'Absurd', 'YOLO': 데이터에서 제거하고자 하는 값(범주)입니다.
# - ~: 논리 부정 연산자로, isin() 함수의 결과를 뒤집어 'Absurd', 'YOLO' 값이 **없는** 행을 선택합니다.
# mkt_df =:
# - 필터링된 데이터프레임을 원본 mkt_df 변수에 다시 저장합니다.
# - 결과적으로, 'Marital_Status' 값이 'Absurd' 또는 'YOLO'인 행은 mkt_df에서 제거됩니다.
# mkt_df['Marital_Status'].value_counts():
# - 'Marital_Status' 열에서 각 결혼 상태의 고유 값과 빈도수를 계산합니다.
# - 데이터에서 'Absurd'와 'YOLO' 범주는 제거되었으므로 출력되지 않습니다.
mkt_df = mkt_df[~mkt_df['Marital_Status'].isin(['Absurd', 'YOLO'])]
mkt_df['Marital_Status'].value_counts()---->

예제 26)
# mkt_df['Marital_Status']:
# 데이터프레임 mkt_df에서 'Marital_Status' 열을 선택합니다.
# 이 열은 고객의 결혼 상태를 나타내는 범주형 데이터입니다.
# .replace({...}):
# - 'Marital_Status' 열의 값 중 특정 값을 다른 값으로 변환합니다.
# - 딕셔너리({}) 형태로 원래 값과 변환할 값을 매핑(mapping)합니다.
# 매핑 규칙:
# - 'Married' → 'Partner': 결혼한 상태를 'Partner'(동반자)로 재분류.
# - 'Together' → 'Partner': 동거하는 상태를 'Partner'(동반자)로 재분류.
# - 'Single' → 'Single': 미혼 상태는 그대로 유지.
# - 'Divorced' → 'Single': 이혼한 상태를 'Single'(독신)로 재분류.
# - 'Widow' → 'Single': 사별한 상태를 'Single'(독신)로 재분류.
# - 'Alone' → 'Single': 혼자 사는 상태를 'Single'(독신)로 재분류.
# 결과:
# - 'Marital_Status' 열의 값이 지정된 매핑 규칙에 따라 변환됩니다.
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({
'Married': 'Partner',
'Together': 'Partner',
'Single': 'Single',
'Divorced': 'Single',
'Widow': 'Single',
'Alone': 'Single'
})
예제 27)
mkt_df['Marital_Status'].value_counts() #위에 적용후 결과를 출력하면 다음과 같습니다.--->

예제 28)
mkt_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 2211 entries, 0 to 2239
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2211 non-null int64
1 Education 2211 non-null object
2 Marital_Status 2211 non-null object
3 Income 2211 non-null float64
4 Recency 2211 non-null int64
5 MntWines 2211 non-null int64
6 MntFruits 2211 non-null int64
7 MntMeatProducts 2211 non-null int64
8 MntFishProducts 2211 non-null int64
9 MntSweetProducts 2211 non-null int64
10 MntGoldProds 2211 non-null int64
11 NumDealsPurchases 2211 non-null int64
12 NumWebPurchases 2211 non-null int64
13 NumCatalogPurchases 2211 non-null int64
14 NumStorePurchases 2211 non-null int64
15 NumWebVisitsMonth 2211 non-null int64
16 Response 2211 non-null int64
17 Complain 2211 non-null int64
18 pass_month 2211 non-null int32
19 Total_mnt 2211 non-null int64
20 Children 2211 non-null int64
dtypes: float64(1), int32(1), int64(17), object(2)
memory usage: 371.4+ KB
예제 29)
# pd.get_dummies(mkt_df, columns=['Education', 'Marital_Status']):
# - 데이터프레임 mkt_df에서 'Education' 열과 'Marital_Status' 열을 원-핫 인코딩(One-Hot Encoding) 방식으로 변환합니다.
# 원-핫 인코딩(One-Hot Encoding):
# - 범주형 데이터(예: 'Education', 'Marital_Status')를 0과 1로 이루어진 이진 벡터로 변환합니다.
# - 각 고유 범주 값에 대해 별도의 열(Column)을 생성하며, 해당 값에 해당하면 1, 그렇지 않으면 0을 할당합니다.
# columns=['Education', 'Marital_Status']:
# - 원-핫 인코딩을 적용할 열의 이름을 지정합니다.
# - 'Education': 학력 정보를 나타내는 열.
# - 'Marital_Status': 결혼 상태 정보를 나타내는 열.
# mkt_df =:
# - 변환된 데이터프레임을 원본 변수 mkt_df에 다시 저장합니다.
# - 결과적으로, 'Education'과 'Marital_Status' 열은 삭제되고, 해당 열의 범주 값을 기반으로 생성된 새로운 열이 추가됩니다.
# mkt_df.head():
# - 변환된 데이터프레임의 상위 5개 행을 출력하여, 원-핫 인코딩 결과를 확인합니다.
mkt_df = pd.get_dummies(mkt_df, columns=['Education', 'Marital_Status'])
mkt_df.head()---->

예제 30)
# from sklearn.preprocessing import StandardScaler:
# - scikit-learn 라이브러리의 preprocessing 모듈에서 StandardScaler 클래스를 가져옵니다.
# - StandardScaler는 데이터를 표준화(standardization)하는 도구입니다.
# - 표준화는 각 특성(feature)의 평균을 0, 표준편차를 1로 변환하여 스케일을 조정하는 작업입니다.
# ss = StandardScaler():
# - StandardScaler 객체를 생성합니다.
# - 생성된 객체(ss)는 이후에 fit()과 transform() 메서드를 사용하여 데이터를 표준화할 수 있습니다.
# - 주요 목적:
# 1. 데이터의 크기를 조정하여 머신러닝 알고리즘에서 효율적인 학습이 가능하도록 합니다.
# 2. 값의 범위가 서로 다른 여러 특성 간의 불균형을 해소합니다.
# 3. 특히 거리 기반 알고리즘(예: KNN, SVM, PCA 등)에서 성능 향상을 기대할 수 있습니다.
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
ss = StandardScaler()
예제 31)
# mkt_df.columns:
# - 데이터프레임 mkt_df의 열(Column) 이름들을 반환합니다.
# - 반환되는 결과는 Index 객체로, 데이터프레임에 포함된 모든 열의 이름을 포함합니다.
# - 각 열의 이름은 데이터프레임의 구조를 이해하거나 특정 열을 선택/분석할 때 사용됩니다.
# 주요 용도:
# 1. 데이터프레임의 열 이름을 확인하여 데이터 구조를 파악.
# 2. 특정 열의 이름을 사용해 열 선택, 수정 또는 제거.
# 3. 열 이름을 리스트로 변환하여 추가 작업 수행.
mkt_df.columns
--->
Index(['Year_Birth', 'Income', 'Recency', 'MntWines', 'MntFruits',
'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
'MntGoldProds', 'NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases', 'NumWebVisitsMonth',
'Response', 'Complain', 'pass_month', 'Total_mnt', 'Children',
'Education_2n Cycle', 'Education_Basic', 'Education_Graduation',
'Education_Master', 'Education_PhD', 'Marital_Status_Partner',
'Marital_Status_Single'],
dtype='object')
예제 32)
# ss.fit_transform(...):
# - 이전에 생성한 StandardScaler 객체(ss)를 사용하여 데이터를 표준화(standardization)합니다.
# - 표준화는 각 특성(feature)의 평균을 0, 표준편차를 1로 변환하여 데이터의 스케일을 조정하는 작업입니다.
# - fit_transform()은 데이터를 학습(fit)하고 변환(transform)하는 작업을 한 번에 수행합니다.
# mkt_df[['Income', 'Recency', ...]]:
# - 데이터프레임 mkt_df에서 표준화를 적용할 열들을 선택합니다.
# - 선택된 열:
# 1. 'Income': 수입.
# 2. 'Recency': 마지막 구매 이후 경과일.
# 3. 'MntWines', 'MntFruits', ...: 각 제품별 구매 금액.
# 4. 'NumDealsPurchases', ...: 구매 채널별 구매 횟수.
# 5. 'Response': 캠페인 응답 여부.
# 6. 'pass_month': 가입 후 경과 월수.
# 7. 'Total_mnt': 총 구매 금액.
# 8. 'Children': 자녀 수.
# fit_transform() 동작:
# 1. fit():
# - 각 열의 평균(mean)과 표준편차(std)를 계산합니다.
# - 계산된 평균과 표준편차는 데이터를 변환하는 데 사용됩니다.
# 2. transform():
# - 계산된 평균과 표준편차를 사용하여 각 열의 값을 표준화합니다.
# - 공식: (값 - 평균) / 표준편차.
# - 결과적으로 모든 열의 값은 평균 0, 표준편차 1로 변환됩니다.
# 반환 값:
# - 표준화된 값들을 담은 NumPy 배열.
# - 배열의 크기는 선택된 열과 동일하며, 스케일이 조정된 데이터를 포함합니다.
ss.fit_transform(mkt_df[['Income', 'Recency', 'MntWines', 'MntFruits',
'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
'MntGoldProds', 'NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases', 'NumWebVisitsMonth',
'Response', 'pass_month', 'Total_mnt', 'Children']])
---->
array([[ 1.52712406, -1.69557929, -0.34413794, ..., -1.45341235,
0.96681935, -1.26534156],
[ 0.23855866, -1.69557929, 0.47055009, ..., -1.45341235,
-0.04967723, -1.26534156],
[ 0.71118126, -1.69557929, -0.50707555, ..., -1.3228886 ,
-0.59026106, 0.06942475],
...,
[-0.26216307, 1.72582483, -0.35598795, ..., 2.07072888,
-0.49408357, 0.06942475],
[ 0.64392915, 1.72582483, -0.11306279, ..., 1.02653889,
1.28685825, -1.26534156],
[ 1.99324439, 1.72582483, -0.40338798, ..., 2.33177638,
0.7810973 , 1.40419106]])
예제 33)
# mkt_df[['Income', 'Recency', 'MntWines', ...]]:
# - 데이터프레임 mkt_df에서 표준화를 적용할 여러 열을 선택합니다.
# - 선택된 열들은 수치형 데이터로 구성되어 있으며, 스케일 조정이 필요합니다.
# - 열 목록:
# 1. 'Income': 수입
# 2. 'Recency': 마지막 구매 이후 경과일
# 3. 'MntWines', 'MntFruits', ...: 각 제품별 구매 금액
# 4. 'NumDealsPurchases', ...: 구매 채널별 구매 횟수
# 5. 'Response': 캠페인 응답 여부
# 6. 'pass_month': 가입 후 경과 월수
# 7. 'Total_mnt': 총 구매 금액
# 8. 'Children': 자녀 수
# ss.fit_transform(...):
# - StandardScaler 객체(ss)를 사용하여 데이터를 표준화합니다.
# - fit_transform()은 데이터를 학습(fit)하여 평균과 표준편차를 계산하고, 이를 사용하여 데이터를 변환(transform)합니다.
# - 공식: (값 - 평균) / 표준편차
# - 결과는 평균이 0, 표준편차가 1인 표준화된 데이터입니다.
# mkt_df[['...']] = ...:
# - 표준화된 데이터를 다시 원본 데이터프레임 mkt_df의 동일한 열에 저장합니다.
# - 기존의 원본 데이터를 표준화된 데이터로 업데이트합니다.
mkt_df[['Income', 'Recency', 'MntWines', 'MntFruits',
'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
'MntGoldProds', 'NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases', 'NumWebVisitsMonth',
'Response', 'pass_month', 'Total_mnt', 'Children']] = ss.fit_transform(mkt_df[['Income', 'Recency', 'MntWines', 'MntFruits',
'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
'MntGoldProds', 'NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases', 'NumWebVisitsMonth',
'Response', 'pass_month', 'Total_mnt', 'Children']])
mkt_df---->

4. 클러스터
* 클러스터(Clusters)는 데이터 분석에서 비슷한 특성을 가진 데이터 포인트들을 그룹화한 결과를 의미합니다.
* 클러스터링은 비지도 학습의 한 형태로, 데이터 내에 숨겨진 패턴이나 구조를 찾는 데 사용됩니다.
* 각 클러스터는 내부적으로는 데이터 포인트들이 매우 유사하지만, 다른 클러스터와는 차별화된 특성을 가지도록 구성됩니다.
* 예를 들어, 고객 데이터를 클러스터링하면 구매 패턴, 소득 수준, 관심사 등에 따라 고객 그룹을 나눌 수 있으며, 이를 통해 타겟 마케팅이나 고객 세그먼테이션과 같은 전략적 의사결정을 내릴 수 있습니다.
* 대표적인 클러스터링 알고리즘으로는 K-평균(K-Means), 계층적 클러스터링, DBSCAN 등이 있습니다.
예시 1)
# from sklearn.datasets import make_blobs:
# - scikit-learn의 datasets 모듈에서 make_blobs 함수를 가져옵니다.
# - make_blobs 함수는 클러스터링(clustering)이나 분류(classification) 알고리즘을 테스트하기 위해
# 가상의 2차원 데이터를 생성하는 데 사용됩니다.
# make_blobs(n_samples=100, centers=3, random_state=2025):
# - 가상의 데이터를 생성하여 변수 X와 y에 저장합니다.
# - 주요 매개변수:
# 1. n_samples=100:
# - 총 100개의 데이터 포인트(샘플)를 생성합니다.
# 2. centers=3:
# - 데이터 포인트를 3개의 클러스터 중심(centers) 주위에 생성합니다.
# - 클러스터는 서로 다른 그룹을 나타냅니다.
# 3. random_state=2025:
# - 난수 생성의 시드(seed)를 설정하여 실행 시 동일한 데이터가 생성되도록 만듭니다.
# - 동일한 코드를 여러 번 실행해도 결과가 일관되게 유지됩니다.
# X:
# - 2차원 배열로, 각 행은 하나의 데이터 포인트(샘플)를 나타냅니다.
# - 각 데이터 포인트는 2개의 특성(feature) 값(예: x축과 y축 좌표)을 가집니다.
# y:
# - 1차원 배열로, 각 데이터 포인트가 속한 클러스터의 레이블(0, 1, 2 등)을 나타냅니다.
# - 각 값은 해당 데이터 포인트가 속한 클러스터를 식별합니다.
# 결과적으로, X는 100개의 2차원 좌표, y는 각 좌표의 클러스터 레이블을 포함합니다.
X, y = make_blobs(n_samples=100, centers=3, random_state=2025)
예시 2)
X # 위 코드 출력 결과
--->
array([[10.08755008, 0.6382729 ],
[-2.84528491, -4.19928722],
[-6.08423803, 7.75892314],
[-6.43263275, 6.56285565],
[-1.95189159, -5.34779925],
[ 7.04310741, -0.27258836],
[-3.18545155, -6.28523417],
[-7.6623194 , 6.89752652],
[-2.0708511 , -2.50176812],
[ 7.45006141, -1.5341477 ],
[ 8.98531829, -1.19709903],
[-6.54168118, 8.03522044],
[-8.3317329 , 6.92895797],
[ 7.09099404, -0.04838319],
[ 8.63422404, -1.81827114],
[-6.89564043, 6.59075961],
[-8.34403241, 7.66827539],
[ 6.39177271, -1.91906413],
[ 7.68737327, -1.52884924],
[-2.92043816, -5.07630038],
[-6.52664944, 7.9620877 ],
[ 8.11264486, -0.91083917],
[-1.95818681, -6.23856568],
[-8.19114307, 6.49778601],
[ 8.01105229, -0.2545059 ],
[-7.20324561, 7.82328962],
[-8.68100584, 6.91076403],
[ 9.58622846, -1.74411022],
[ 7.10826722, -0.15009782],
[-1.18848108, -4.30959714],
[-1.37653917, -4.00568529],
[-7.39997874, 6.36379833],
[-5.70126022, 7.56825104],
[ 7.87588635, -1.68089092],
[ 8.11366874, -0.7574711 ],
[10.12375532, -0.29528407],
[-6.22675495, 7.79415406],
[-1.82969077, -4.1624514 ],
[-8.47243341, 9.30923913],
[-7.60099288, 7.10312907],
[-7.13204337, 5.96771101],
[ 9.2079617 , -1.51643512],
[-7.39096481, 9.90402063],
[-3.22474543, -4.07373642],
[ 7.40120941, -0.54485456],
[-1.30495236, -3.97140323],
[ 9.03150176, 0.93670003],
[ 8.50730067, -3.30030591],
[-2.72067382, -5.60801469],
[-0.66443937, -6.10210158],
[-7.96578724, 8.82635435],
[ 8.1339375 , -0.87478468],
[-1.6577205 , -5.69166206],
[-1.45375198, -6.46852036],
[-2.46520672, -6.67330389],
[-1.47987959, -5.01044275],
[-1.18575592, -5.57802298],
[-6.38809782, 8.93064802],
[-2.55094919, -5.07685951],
[-5.89652864, 7.54966292],
[ 7.35953108, -2.34401953],
[ 8.44617337, -0.01951273],
[ 9.70305929, -0.97067219],
[ 9.55126793, -1.9886259 ],
[-1.41574795, -3.59723382],
[-7.45399466, 7.42882649],
[ 9.74798513, -1.18296162],
[ 9.31590229, -1.94156303],
[-5.38869599, 7.11185 ],
[-6.35317386, 6.75241771],
[-1.53313385, -5.16966792],
[-7.9617372 , 6.49495916],
[-3.84692444, -4.96134363],
[ 6.84326349, 0.50542883],
[-2.19187317, -4.74347013],
[-6.07391519, 8.69337124],
[-7.4719597 , 8.47493427],
[ 7.66677531, -0.83588696],
[-1.75602985, -4.61662256],
[-3.60459834, -4.98323555],
[-0.52557164, -4.96031359],
[-2.03235267, -4.07828509],
[ 9.8989398 , -1.72869507],
[-1.66839511, -5.07970367],
[-3.11713295, -5.82780762],
[ 9.44803575, -1.09097664],
[-7.29094398, 8.53920102],
[-2.15764418, -4.38345202],
[-7.23360386, 6.79081544],
[ 8.84364001, -1.86701986],
[-6.08967178, 7.69536874],
[-8.32952787, 7.60060625],
[-7.36318471, 8.34897159],
[-2.14448577, -3.67704308],
[ 8.53483415, -3.22056682],
[ 7.61681788, -1.46508113],
[-0.39610547, -5.5480157 ],
[-8.72450667, 9.28780655],
[-8.71796501, 8.10032447],
[-1.27883333, -4.3776293 ]])
예시 3)
y #위 코드를 출력한 결과
--->
array([1, 2, 0, 0, 2, 1, 2, 0, 2, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 2, 0, 1,
2, 0, 1, 0, 0, 1, 1, 2, 2, 0, 0, 1, 1, 1, 0, 2, 0, 0, 0, 1, 0, 2,
1, 2, 1, 1, 2, 2, 0, 1, 2, 2, 2, 2, 2, 0, 2, 0, 1, 1, 1, 1, 2, 0,
1, 1, 0, 0, 2, 0, 2, 1, 2, 0, 0, 1, 2, 2, 2, 2, 1, 2, 2, 1, 0, 2,
0, 1, 0, 0, 0, 2, 1, 1, 2, 0, 0, 2])
예제 4)
# X = pd.DataFrame(X):
# - X 데이터를 pandas 데이터프레임으로 변환합니다.
# - make_blobs 함수에서 생성된 X는 기본적으로 NumPy 배열 형식입니다.
# - pandas의 DataFrame으로 변환하면 데이터에 열 이름을 추가하거나, 데이터 조작과 분석 작업을 더 편리하게 수행할 수 있습니다.
# pandas 데이터프레임으로 변환 후:
# - 각 행(Row): 데이터 포인트(샘플)을 나타냅니다.
# - 각 열(Column): 데이터의 특성(feature)을 나타냅니다.
# 예를 들어, make_blobs로 생성된 데이터는 기본적으로 2개의 특성을 가지므로 2개의 열이 생성됩니다.
# X:
# - 변환된 데이터프레임을 출력합니다.
# - X는 pandas 데이터프레임으로, 데이터 포인트와 해당 특성 값을 포함합니다.
X = pd.DataFrame(X)
X---->
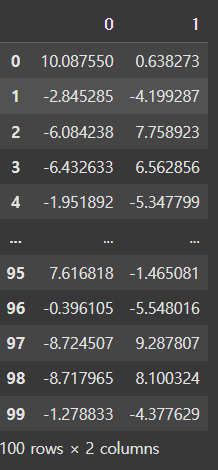
예제 5)
# sns.scatterplot():
# - seaborn 라이브러리에서 제공하는 산점도(scatter plot) 함수입니다.
# - 데이터 포인트를 2차원 공간에 시각화하며, 각 점의 위치는 지정된 x축과 y축 값을 기반으로 합니다.
# - hue 매개변수를 사용하면 데이터 포인트를 그룹(클러스터, 클래스 등)별로 색상을 다르게 표시할 수 있습니다.
# x=X[0], y=X[1]:
# - x축과 y축에 표시할 데이터를 지정합니다.
# - X는 pandas 데이터프레임으로, X[0]은 첫 번째 열(Feature 1), X[1]은 두 번째 열(Feature 2)을 의미합니다.
# 예: x축은 Feature 1, y축은 Feature 2에 해당하는 값.
# hue=y:
# - 데이터 포인트의 색상을 y 값(클러스터 또는 클래스 레이블)을 기준으로 다르게 설정합니다.
# - y는 1차원 배열로, 각 데이터 포인트의 그룹(레이블)을 나타냅니다.
# - 각 그룹은 고유한 색상으로 표시됩니다.
# 결과:
# - x축과 y축에 데이터를 시각화한 산점도가 생성됩니다.
# - 각 데이터 포인트는 hue를 기준으로 그룹에 따라 다른 색상으로 표시됩니다.
sns.scatterplot(x=X[0], y=X[1], hue=y)
--->
<Axes: xlabel='0', ylabel='1'>--->

### K-Means
* K-Means는 가장 널리 사용되는 클러스터링 알고리즘 중 하나로, 데이터를 K개의 클러스터로 나누는 비지도 학습 기법입니다.
* 알고리즘은 먼저 데이터 내에서 K개의 초기 중심점(centroid)을 랜덤하게 선택한 뒤, 각 데이터 포인트를 가장 가까운 중심점에 할당하여 클러스터를 형성합니다.
* 그런 다음, 각 클러스터의 평균값을 계산하여 중심점을 갱신하고, 이 과정을 중심점의 위치가 더 이상 변하지 않을 때까지 반복합니다.
* K-Means는 계산이 간단하고 대규모 데이터셋에서도 빠르게 작동하지만, 클러스터 수(K)를 사전에 정해야 하고, 데이터가 구형으로 분포하지 않거나 잡음(noise)이 많은 경우 성능이 떨어질 수 있습니다.
* 이 알고리즘은 고객 세그먼트화, 이미지 압축, 패턴 인식 등 다양한 분야에서 활용됩니다.
예시 1)
# from sklearn.cluster import KMeans:
# - scikit-learn 라이브러리의 cluster 모듈에서 KMeans 클래스를 가져옵니다.
# - KMeans는 비지도 학습(unsupervised learning)의 클러스터링(clustering) 알고리즘 중 하나로,
# 데이터를 지정된 개수의 클러스터(n_clusters)로 나누는 데 사용됩니다.
# km = KMeans(n_clusters=3):
# - KMeans 클래스의 객체를 생성합니다.
# - 주요 매개변수:
# 1. n_clusters=3:
# - 데이터를 3개의 클러스터로 나눕니다.
# - 클러스터의 개수는 사용자가 지정해야 합니다.
# - 기본적으로 초기 클러스터 중심은 랜덤하게 선택됩니다.
# - 다른 매개변수(예: init, max_iter 등)를 통해 세부 설정 가능.
# km.fit(X):
# - 데이터를 K-Means 모델에 학습시킵니다.
# - X: 입력 데이터로, 각 데이터 포인트의 좌표 또는 특성 값을 포함하는 2차원 배열입니다.
# - fit() 함수는 K-Means 알고리즘을 사용하여 클러스터 중심(centroids)을 학습합니다.
# km.predict(X):
# - 학습된 클러스터 중심을 기반으로, 입력 데이터(X)가 어떤 클러스터에 속하는지 예측합니다.
# - 결과는 각 데이터 포인트의 클러스터 레이블(0, 1, 2 등)로 이루어진 배열로 반환됩니다.
# - pred: 각 데이터 포인트가 속한 클러스터를 나타내는 레이블 배열입니다.
from sklearn.cluster import KMeans
# K-Means 객체 생성 (3개의 클러스터 지정)
km = KMeans(n_clusters=3)
# 데이터를 K-Means 모델에 학습 (클러스터 중심 계산)
km.fit(X)
# 각 데이터 포인트의 클러스터 레이블 예측
pred = km.predict(X)
예시 2)
# sns.scatterplot():
# - seaborn 라이브러리에서 제공하는 산점도(scatter plot) 함수입니다.
# - 데이터 포인트를 2차원 공간에 시각화하며, 각 점의 위치는 지정된 x축과 y축 값에 따라 달라집니다.
# - hue 매개변수를 사용하면 데이터 포인트를 그룹(클러스터, 클래스 등)별로 색상을 다르게 표시할 수 있습니다.
# x=X[0], y=X[1]:
# - x축과 y축에 표시할 데이터를 지정합니다.
# - X는 pandas 데이터프레임으로, X[0]은 첫 번째 열(Feature 1), X[1]은 두 번째 열(Feature 2)을 의미합니다.
# - x축: Feature 1의 값 (X[0])
# - y축: Feature 2의 값 (X[1])
# hue=pred:
# - 데이터 포인트의 색상을 pred 값을 기준으로 다르게 설정합니다.
# - pred는 K-Means 클러스터링 결과로, 각 데이터 포인트가 속한 클러스터 레이블(0, 1, 2 등)을 나타냅니다.
# - 각 클러스터 레이블에 대해 고유한 색상을 적용하여 시각적으로 구분합니다.
# 결과:
# - x축과 y축 값에 따라 각 데이터 포인트가 위치합니다.
# - hue를 사용해 클러스터 레이블(pred 값)에 따라 데이터 포인트의 색상이 다르게 표시됩니다.
sns.scatterplot(x=X[0], y=X[1], hue=pred)
--->
<Axes: xlabel='0', ylabel='1'>--->

예시 3)
# K-Means 클러스터링 모델 생성, 학습, 예측
# km = KMeans(n_clusters=5):
# - K-Means 클러스터링 객체를 생성합니다.
# - 주요 매개변수:
# 1. n_clusters=5:
# - 데이터를 5개의 클러스터로 나누도록 설정합니다.
# 2. 기본값으로 초기 클러스터 중심은 랜덤하게 선택됩니다.
# - n_clusters 값을 사용자가 지정해야 하며, 클러스터 개수는 분석 목적에 따라 달라질 수 있습니다.
# km.fit(X):
# - 데이터를 K-Means 모델에 학습시킵니다.
# - X: 입력 데이터로, 각 행은 데이터 포인트(샘플)를 나타내고, 열은 특성(feature)을 나타냅니다.
# - fit() 함수는 K-Means 알고리즘을 사용하여 다음 작업을 수행합니다:
# 1. 초기 클러스터 중심(centroids)을 선택.
# 2. 각 데이터 포인트와 클러스터 중심 간의 거리를 계산.
# 3. 데이터를 가장 가까운 클러스터 중심에 할당.
# 4. 클러스터 중심을 새로 계산.
# 5. 이 과정을 클러스터 중심이 수렴하거나 최대 반복 횟수에 도달할 때까지 반복.
# pred = km.predict(X):
# - 학습된 K-Means 모델을 사용하여 각 데이터 포인트가 속한 클러스터를 예측합니다.
# - 결과(pred)는 각 데이터 포인트의 클러스터 레이블(0, 1, ..., n_clusters-1)로 이루어진 1차원 배열입니다.
# - 이 레이블은 각 데이터 포인트가 어느 클러스터에 속하는지 나타냅니다.
from sklearn.cluster import KMeans
# K-Means 클러스터링 객체 생성 (5개의 클러스터 지정)
km = KMeans(n_clusters=5)
# 데이터를 K-Means 모델에 학습
km.fit(X)
# 각 데이터 포인트의 클러스터 레이블 예측
pred = km.predict(X)
예시 4)
sns.scatterplot(x=X[0], y=X[1], hue=pred)
--->
<Axes: xlabel='0', ylabel='1'>---->

### inertia_
* inertia_는 K-Means 알고리즘에서 클러스터링의 "품질"을 측정하는 값으로, **군집 내 거리 제곱합(Sum of Squared Errors, SSE)**를 나타냅니다.
* 이는 각 데이터 포인트와 해당 클러스터 중심(centroid) 간의 거리 제곱의 합으로 계산되며, 클러스터가 얼마나 잘 형성되었는지 평가하는 데 사용됩니다.
예시 1)
# km.inertia_:
# - K-Means 알고리즘의 클러스터링 결과를 평가하기 위한 지표로, 클러스터 내 거리의 총합(Inertia)을 나타냅니다.
# - 정의:
# Inertia는 각 클러스터 내 데이터 포인트와 클러스터 중심(centroid) 간 거리의 제곱합입니다.
# - 공식:
# inertia = ΣΣ ||x_i - c_j||²
# - x_i: 클러스터 j에 속하는 데이터 포인트 i.
# - c_j: 클러스터 j의 중심(centroid).
# - ||x_i - c_j||²: 데이터 포인트 i와 중심 c_j 간 유클리드 거리의 제곱.
# 결과:
# - inertia 값이 작을수록 데이터 포인트가 각 클러스터 중심에 더 가깝게 모여 있다는 것을 의미합니다.
# - 이는 클러스터링 품질이 더 좋음을 나타냅니다.
# - 단, inertia는 클러스터 개수(n_clusters)가 증가하면 항상 감소하므로, 최적의 클러스터 개수를 찾기 위해 엘보우 기법(Elbow Method)을 사용합니다.
# km.inertia_는 fit() 실행 후에 계산됩니다.
km.inertia_
--->
130.0803980427866
예시 2)
# inertia_list = []:
# - 클러스터 개수(n_clusters)에 따른 K-Means의 관성(Inertia) 값을 저장할 빈 리스트를 생성합니다.
# - inertia는 각 클러스터 내 데이터 포인트와 클러스터 중심(centroid) 간 거리의 제곱합을 나타내는 값입니다.
# for i in range(2, 11):
# - 클러스터 개수(n_clusters)를 2부터 10까지 변경하면서 반복합니다.
# - i는 현재 반복에서 사용할 클러스터 개수를 나타냅니다.
# km = KMeans(n_clusters=i):
# - 클러스터 개수를 i로 설정하여 K-Means 클러스터링 객체를 생성합니다.
# km.fit(X):
# - 데이터 X에 대해 K-Means 모델을 학습시킵니다.
# - 클러스터 중심을 계산하고 데이터를 각 클러스터에 할당합니다.
# inertia_list.append(km.inertia_):
# - 학습된 K-Means 모델의 관성(Inertia) 값을 리스트 `inertia_list`에 추가합니다.
# - inertia는 클러스터 내 데이터 포인트와 중심 간 거리의 제곱합으로, 클러스터링 품질을 평가하는 지표입니다.
# - 클러스터 개수가 증가할수록 inertia 값은 감소합니다.
# inertia_list:
# - 클러스터 개수에 따른 K-Means의 관성 값을 저장한 리스트입니다.
# - 출력하면 각 클러스터 개수에 대한 inertia 값을 확인할 수 있습니다.
inertia_list = []
for i in range(2, 11): # 클러스터 개수를 2에서 10까지 반복
km = KMeans(n_clusters=i) # 현재 클러스터 개수로 K-Means 객체 생성
km.fit(X) # 데이터를 K-Means 모델에 학습
inertia_list.append(km.inertia_) # 관성 값을 리스트에 추가
inertia_list # 클러스터 개수별 관성 값 출력
=---->
[2202.099288979431,
178.3026813479228,
149.2341882048366,
136.92331707274494,
109.64913453837907,
96.40769208271097,
82.95496013038938,
73.16885722421148,
69.16216581394964]
예제 3)
# sns.lineplot():
# - seaborn 라이브러리에서 제공하는 선 그래프(line plot) 함수입니다.
# - 데이터의 연속적인 변화 추세를 시각화하는 데 사용됩니다.
# x=range(2,11):
# - x축에 표시할 값을 지정합니다.
# - range(2,11)는 2부터 10까지의 정수 리스트를 생성합니다.
# - 이 값은 클러스터 개수(n_clusters)를 나타냅니다.
# y=inertia_list:
# - y축에 표시할 값을 지정합니다.
# - inertia_list는 클러스터 개수에 따른 K-Means의 관성(Inertia) 값을 저장한 리스트입니다.
# - 관성은 클러스터 내 데이터 포인트와 클러스터 중심 간 거리의 제곱합으로, 클러스터링 품질을 평가하는 지표입니다.
# 엘보우 메서드:
# - 클러스터 개수를 결정하는 데 사용하는 방법입니다.
# - inertia 값이 급격히 감소하다가 완만해지는 지점(엘보우)이 최적의 클러스터 개수일 가능성이 높습니다.
sns.lineplot(x=range(2,11), y=inertia_list) # 엘보우 메서드 시각화--->

5. KMeans 적용
예시 1)
inertia_list = []
for i in range(1, 11):
km = KMeans(n_clusters=i, random_state=2025)
km.fit(mkt_df)
inertia_list.append(km.inertia_)
inertia_list
--->
[357451.16553595616,
140084.74020209623,
92233.54121779017,
73244.56722800616,
64717.3393155163,
59170.118323034076,
56227.96042266366,
48272.61122732541,
46261.953243426404,
43394.780297016034]
예시 2)
# 필요한 라이브러리 import
import seaborn as sns # 데이터 시각화를 위한 라이브러리
import matplotlib.pyplot as plt # 그래프 시각화를 위한 라이브러리
from sklearn.cluster import KMeans # KMeans 클러스터링 알고리즘을 사용하기 위한 라이브러리
# 빈 리스트 생성 (KMeans의 inertia 값을 저장할 리스트)
inertia_list = []
# 클러스터 개수를 2부터 10까지 변경하며 KMeans 실행
for i in range(2, 11): # 2부터 10까지 반복
km = KMeans(n_clusters=i, random_state=2025) # i개의 클러스터로 KMeans 객체 생성
km.fit(mkt_df) # 데이터를 KMeans 모델에 학습
inertia_list.append(km.inertia_) # inertia 값을 inertia_list에 추가
# x축은 클러스터 개수 (2부터 10), y축은 inertia 값
sns.lineplot(x=range(2, 11), y=inertia_list) # 클러스터 개수와 inertia 값을 선 그래프로 시각화--->
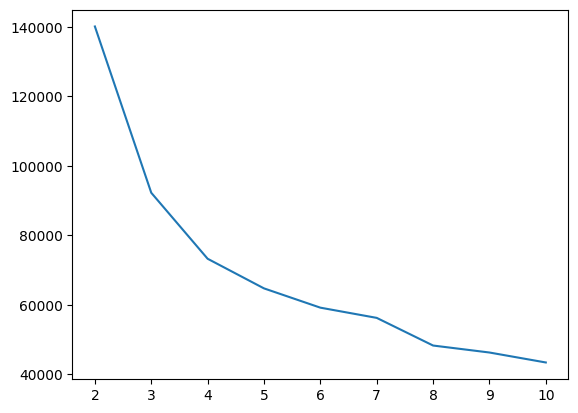
6.실루엣 스코어
* 실루엣 스코어(Silhouette Score)는 클러스터링의 품질을 평가하는 척도 중 하나로, 각 데이터 포인트가 자신의 클러스터 내부에 잘 속해 있는지와 다른 클러스터와 얼마나 구분되는지를 측정합니다.
* 각 데이터 포인트의 실루엣 계수는 -1에서 1 사이의 값을 가지며, 전체 데이터셋에 대해 평균을 내어 실루엣 스코어를 계산합니다.
* a : 데이터 포인트가 같은 클러스터 내 다른 데이터 포인트들과의 평균 거리(클러스터 내부 결합도)
* b : 데이터 포인트가 가장 가까운 다른 클러스터와의 평균 거리(클러스터 간 분리도)
> 실루엣 스코어가 1에 가까울수록 클러스터링이 잘된 것
예제 1)
from sklearn.metrics import silhouette_score # 실루엣 점수 계산을 위한 함수
# 빈 리스트 생성 (실루엣 점수를 저장할 리스트)
score = []
# 클러스터 개수를 2부터 10까지 변경하며 KMeans 실행 및 실루엣 점수 계산
for i in range(2, 11): # 2부터 10까지 반복
km = KMeans(n_clusters=i, random_state=2025) # 현재 클러스터 개수로 KMeans 객체 생성
km.fit(mkt_df) # 데이터를 KMeans 모델에 학습
pred = km.predict(mkt_df) # 각 데이터 포인트의 클러스터 레이블 예측
score.append(silhouette_score(mkt_df, pred)) # 실루엣 점수를 계산하여 리스트에 추가
# 2부터 10까지의 클러스터 개수에 대한 실루엣 점수 출력
score
--->
[0.49485217908426427,
0.39119710028305976,
0.3361117558323644,
0.28660251449820157,
0.23464871491939643,
0.19818122568572438,
0.23053730169070785,
0.19929970022806406,
0.2004835588203285]
예제 2)
sns.lineplot(x=range(2, 11), y=score)---->

예제 3)
# K-Means 클러스터링 모델 생성 및 학습
# km = KMeans(n_clusters=8, random_state=2025):
# - K-Means 클러스터링 객체를 생성합니다.
# - 주요 매개변수:
# 1. n_clusters=8:
# - 클러스터의 개수를 8개로 설정합니다.
# - K-Means 알고리즘은 데이터를 8개의 클러스터로 나누고 중심(centroid)을 계산합니다.
# 2. random_state=2025:
# - 난수 생성 시드를 설정하여 결과 재현성을 보장합니다.
# - 동일한 데이터를 입력했을 때 항상 같은 결과가 나오도록 설정합니다.
# km.fit(mkt_df):
# - 입력 데이터(mkt_df)를 사용하여 K-Means 알고리즘을 실행하고 모델을 학습시킵니다.
# - fit() 함수가 수행하는 작업:
# 1. 초기 클러스터 중심(centroids)을 랜덤하게 설정합니다.
# 2. 각 데이터 포인트와 클러스터 중심 간 거리를 계산합니다.
# 3. 각 데이터 포인트를 가장 가까운 클러스터 중심에 할당합니다.
# 4. 클러스터 중심을 재계산합니다.
# 5. 위 단계를 클러스터 중심이 수렴하거나 최대 반복 횟수에 도달할 때까지 반복합니다.
from sklearn.cluster import KMeans
# K-Means 클러스터링 객체 생성 (클러스터 개수: 8, 재현성을 위한 random_state 설정)
km = KMeans(n_clusters=8, random_state=2025)
# 데이터프레임 mkt_df를 사용하여 모델 학습
km.fit(mkt_df)--->

예제 4)
# pred = km.predict(mkt_df):
# - 학습된 K-Means 모델을 사용하여 각 데이터 포인트가 속한 클러스터를 예측합니다.
# - mkt_df: 입력 데이터로, 각 행은 데이터 포인트(샘플)를 나타냅니다.
# - km.predict():
# 1. 각 데이터 포인트와 학습된 클러스터 중심(centroids) 간 거리를 계산합니다.
# 2. 가장 가까운 클러스터 중심에 해당하는 레이블(0, 1, ..., n_clusters-1)을 반환합니다.
# - 결과(pred): 각 데이터 포인트가 속한 클러스터 레이블로 이루어진 1차원 배열.
# pred:
# - 각 데이터 포인트의 클러스터 레이블을 포함하는 NumPy 배열.
# - 예를 들어, pred = [0, 1, 2, 0, 1]이라면, 첫 번째 데이터 포인트는 클러스터 0에 속하고,
# 두 번째 데이터 포인트는 클러스터 1에 속함을 나타냅니다.
pred = km.predict(mkt_df) # 데이터프레임 mkt_df에 대해 클러스터 레이블 예측
pred # 각 데이터 포인트의 클러스터 레이블 출력
예제 5)
# mkt_df['label'] = pred:
# - 예측된 클러스터 레이블(pred)을 데이터프레임 mkt_df에 새로운 열 'label'로 추가합니다.
# - pred는 각 데이터 포인트가 속한 클러스터 레이블(0, 1, ..., n_clusters-1)을 나타내는 배열입니다.
# - 'label' 열:
# - 각 데이터 포인트의 클러스터 레이블을 저장하여 데이터프레임과 클러스터링 결과를 통합합니다.
# mkt_df:
# - 'label' 열이 추가된 데이터프레임을 출력합니다.
# - 기존의 데이터와 함께 각 데이터 포인트가 속한 클러스터를 나타내는 레이블 정보가 포함됩니다.
mkt_df['label'] = pred # 예측된 클러스터 레이블을 데이터프레임 mkt_df에 추가
mkt_df # 'label' 열이 추가된 데이터프레임 출력--->

예제 6)
# mkt_df['label']:
# - 데이터프레임 mkt_df에서 'label' 열을 선택합니다.
# - 'label' 열은 각 데이터 포인트가 속한 클러스터의 레이블(0, 1, ..., n_clusters-1)을 저장합니다.
# .value_counts():
# - 'label' 열에서 각 클러스터 레이블(0, 1, ..., n_clusters-1)이 나타나는 빈도(개수)를 계산합니다.
# - 결과는 각 클러스터 레이블과 해당 클러스터에 속한 데이터 포인트의 개수를 나타내는 Series 객체로 반환됩니다.
# - 기본적으로 빈도가 많은 순서대로 정렬됩니다.
# 결과:
# - 각 클러스터에 속한 데이터 포인트의 개수를 확인할 수 있습니다.
# - 이를 통해 클러스터 크기의 불균형 여부를 파악할 수 있습니다.
mkt_df['label'].value_counts()--->

'LLM(Large Language Model)의 기초 > 데이터 분석' 카테고리의 다른 글
| 17. 손글씨 데이터셋 (0) | 2025.01.10 |
|---|---|
| 15. 호텔 예약 수요 데이터셋 (4) | 2025.01.09 |
| 14. 파이토치로 구현한 논리 회귀 (2) | 2025.01.08 |
| 13. 서울 자전거 공유 수요 예측 데이터셋 (0) | 2025.01.08 |
| 12. 주택 임대료 예측 데이터셋 (0) | 2025.01.07 |