2025. 1. 7. 17:21ㆍLLM(Large Language Model)의 기초/데이터 분석
1. 주택 임대료 예측 데이터셋
* House Rent Prediction Dataset은 주택 임대료를 예측하기 위한 목적으로 사용되는 데이터셋입니다.
* 이 데이터셋은 주로 머신러닝 및 데이터 분석 프로젝트에서 사용되며, 주택의 다양한 특성과 위치 정보를 기반으로 임대료를 예측하는 모델을 학습하는 데 활용됩니다.
들어가서 데이터 다운받아 압축을 푼후 구글 드라이브에 넣습니다.
링크 주소 : https://www.kaggle.com/datasets/iamsouravbanerjee/house-rent-prediction-dataset/data?select=House_Rent_Dataset.csv
House Rent Prediction Dataset
Renting Insights: House Rent Prediction Dataset with 4700+ Listings
www.kaggle.com
2. 데이터셋 컬럼
* BHK: 주택에 포함된 침실, 거실, 주방의 총 개수를 의미합니다.
* Rent: 주택(아파트/플랫)의 월 임대료를 나타냅니다.
* Size: 주택(아파트/플랫)의 면적을 평방피트(Square Feet)로 나타냅니다.
* Floor: 주택이 위치한 층수와 건물의 총 층수를 나타냅니다. (예: 2층 중 1층, 5층 중 3층 등)
* Area Type: 주택의 면적이 어떤 방식으로 계산되었는지를 나타냅니다. (예: 전체 면적, 실사용 면적, 건축 면적 등)
* Area Locality: 주택(아파트/플랫)이 위치한 구체적인 지역이나 동네 정보를 나타냅니다.
* City: 주택(아파트/플랫)이 위치한 도시를 나타냅니다.
* Furnishing Status: 주택이 가구가 완비되었는지(Furnished), 부분적으로 갖추어졌는지(Semi-Furnished), 아니면 비어 있는지(Unfurnished)를 나타냅니다.
* Tenant Preferred: 집주인 또는 중개인이 선호하는 임차인 유형을 나타냅니다. (예: 가족, 싱글, 직장인 등)
* Bathroom: 주택에 있는 욕실의 개수를 나타냅니다.
* Point of Contact: 주택(아파트/플랫)에 대한 추가 정보를 얻기 위해 연락해야 할 담당자나 중개인의 정보를 나타냅니다.
3. 데이터셋 전처리
import numpy as np
import pandas as pd
import seaborn as sns
rent_df = pd.read_csv('/본인의 드라이브 경로/House_Rent_Dataset.csv')
rent_df-->

예시 1)
# rent_df는 Pandas 데이터프레임이며, rent_df.info()는 데이터프레임의 구조적 정보를 출력하는 메서드이다.
# info() 메서드는 다음과 같은 정보를 제공한다:
# 1. 데이터프레임의 총 행(row) 수와 열(column) 수.
# 2. 각 열의 이름(Column Name).
# 3. 각 열의 데이터 타입(Data Type) (e.g., int64, float64, object 등).
# 4. 각 열의 결측치가 아닌 값의 개수(Non-Null Count).
# 5. 데이터프레임이 사용하는 메모리 크기(Memory Usage).
rent_df.info()
-->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4746 entries, 0 to 4745
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Posted On 4746 non-null object
1 BHK 4746 non-null int64
2 Rent 4746 non-null int64
3 Size 4746 non-null int64
4 Floor 4746 non-null object
5 Area Type 4746 non-null object
6 Area Locality 4746 non-null object
7 City 4746 non-null object
8 Furnishing Status 4746 non-null object
9 Tenant Preferred 4746 non-null object
10 Bathroom 4746 non-null int64
11 Point of Contact 4746 non-null object
dtypes: int64(4), object(8)
memory usage: 445.1+ KB
# 각 요소의 의미:
# - <class 'pandas.core.frame.DataFrame'>: rent_df가 Pandas 데이터프레임 객체임을 나타냄.
# - RangeIndex: 행 인덱스 범위를 나타냄 (e.g., 0부터 999까지).
# - Data columns: 데이터프레임의 총 열(column) 개수.
# - Non-Null Count: 각 열에서 Null 값이 아닌 데이터의 개수.
# - Dtype: 각 열의 데이터 타입 (e.g., int64: 정수, float64: 부동소수점 숫자, object: 문자열 등).
# - memory usage: 데이터프레임이 사용하는 메모리의 양.
예시 2)
# rent_df.describe()는 Pandas 데이터프레임에서 수치형 열에 대한 통계 요약 정보를 계산하고 반환한다.
# 기본적으로 describe() 메서드는 데이터프레임의 모든 수치형 열(int 또는 float)에서 다음 통계값을 제공한다:
#
# 1. **count**: 각 열에서 결측치가 아닌 값의 개수.
# 2. **mean**: 각 열의 평균값.
# 3. **std**: 각 열의 표준편차(standard deviation), 데이터가 평균에서 얼마나 퍼져 있는지 측정.
# 4. **min**: 각 열의 최소값.
# 5. **25%**: 각 열의 1사분위값(Q1), 하위 25%에 해당하는 값.
# 6. **50%**: 각 열의 중앙값(중간값, Q2 또는 2사분위값).
# 7. **75%**: 각 열의 3사분위값(Q3), 하위 75%에 해당하는 값.
# 8. **max**: 각 열의 최대값.
#
# rent_df.describe()를 호출하면 이러한 통계 정보를 반환한다.
# 수치형 데이터의 분포와 전반적인 특성을 빠르게 이해하는 데 유용하다.
rent_df.describe()
#
# 각 통계값의 의미:
# - **count**: 해당 열에서 결측치가 아닌 값의 개수. 예를 들어, Bathrooms는 990개의 값이 있다.
# - **mean**: 평균값. 예를 들어, Rent Price의 평균은 1200.5.
# - **std**: 표준편차. 데이터의 퍼짐 정도. Rent Price의 표준편차는 약 300.7.
# - **min**: 열의 최소값. Rent Price의 최소값은 700.
# - **25%, 50%, 75%**: 사분위수(Q1, 중앙값(Q2), Q3). 데이터 분포를 나타낸다.
# - **max**: 열의 최대값. Rent Price의 최대값은 2000.-->

예시 3)
3.500000e+06
-->
3500000.0
예시 4)
#백분위로 떨어지게 만들수 있다
round(rent_df.describe(), 2)
-->-->

예시 5)
# rent_df['BHK']는 Pandas 데이터프레임(rent_df)에서 'BHK'라는 열(column)을 선택하는 코드이다.
# 이 코드는 다음과 같은 상황에서 사용할 수 있다:
# - rent_df에 'BHK'라는 열이 존재할 때, 해당 열의 모든 데이터를 반환한다.
# - 반환된 값은 Pandas Series 객체이며, 인덱스와 값으로 구성된다.
# 'BHK' 열의 값이 무엇을 나타내는지는 데이터프레임의 맥락에 따라 다르지만,
# 일반적으로 부동산 데이터에서 'BHK'는 방(Bedroom), 홀(Hall), 부엌(Kitchen)의 개수를 나타낸다.
# 예: 2 BHK는 침실 2개, 거실 1개, 주방 1개가 있는 집을 의미.
# 이 코드를 실행하면 rent_df 데이터프레임에서 'BHK' 열의 데이터를 반환한다.
rent_df['BHK']
-->-->

예시 6)
sns.displot(rent_df['BHK'])-->

예시 7)
sns.displot(rent_df['Rent'])-->

예시 8)
# rent_df['Rent']는 Pandas 데이터프레임(rent_df)에서 'Rent'라는 열을 선택하는 코드이다.
# 이 열은 일반적으로 집세(월세)를 나타내며, 데이터를 Pandas Series 객체로 반환한다.
# sort_values() 메서드는 선택된 'Rent' 열의 값을 오름차순으로 정렬한다.
# - 기본적으로 작은 값에서 큰 값 순으로 정렬된다.
# - 반환된 값은 정렬된 Pandas Series 객체이다.
# - 원본 데이터프레임(rent_df)은 변경되지 않는다.
# rent_df['Rent'].sort_values()의 동작:
# - 'Rent' 열의 모든 값이 작은 값부터 큰 값으로 정렬된 새로운 Series를 반환.
# - 정렬 후에도 원래의 행 인덱스는 유지된다.
# 참고:
# - 값이 내림차순으로 정렬되기를 원할 경우, sort_values(ascending=False)를 사용.
# - 정렬된 값을 새로운 데이터프레임으로 저장하려면 reset_index(drop=True)를 추가할 수도 있음.
rent_df['Rent'].sort_values()-->

예시 9)
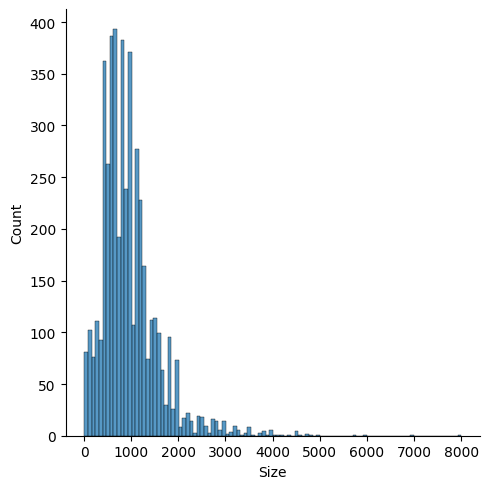
# sns.displot()는 Seaborn 라이브러리를 사용하여 데이터의 분포를 시각화하는 히스토그램과 커널 밀도 추정(KDE) 그래프를 그리는 함수이다.
# 여기서는 rent_df 데이터프레임의 'Size' 열의 분포를 시각화하려고 한다.
# rent_df['Size']:
# - 'Size' 열은 일반적으로 부동산 데이터에서 집의 크기(예: 평방미터 또는 평방피트)를 나타낸다.
# - 데이터는 숫자형 값으로 구성되어 있어, 히스토그램으로 시각화할 수 있다.
# sns.displot(rent_df['Size'])의 동작:
# - 'Size' 열의 데이터 값을 가져와 히스토그램으로 그린다.
# - 히스토그램은 데이터의 값을 여러 구간(bin)으로 나누어 각 구간에 해당하는 데이터 개수를 나타낸다.
# - 기본적으로 KDE(Kernel Density Estimation) 곡선도 함께 그려진다.
sns.displot(rent_df['Size'])
# 그래프의 의미:
# - x축: 'Size' 열의 값(집의 크기).
# - y축: 해당 크기 범위(bin)에 포함된 데이터의 개수(빈도).
# - 히스토그램: 각 bin의 높이가 데이터의 빈도를 나타냄.
# - KDE 곡선: 데이터의 분포를 부드러운 곡선으로 나타낸 밀도 추정.
# 참고:
# - KDE 곡선을 끄고 싶다면, kde=False를 추가: sns.displot(rent_df['Size'], kde=False)
# - bin 개수를 조정하고 싶다면, bins=옵션을 사용: sns.displot(rent_df['Size'], bins=20)-->
> Boxplot
Boxplot은 데이터의 중앙값, 사분위수, 이상치 등을 시각적으로 표현하는 통계 그래프입니다. 주로 데이터 분포와 이상치를 빠르게 파악하기 위해 사용됩니다.
1. 중앙값 (Median, Q2): 데이터를 크기 순으로 정렬했을 때 중간에 위치한 값
2. Q1 (제1사분위수, 25%): 하위 25%에 해당하는 값
3. Q3 (제3사분위수, 75%): 상위 25%에 해당하는 값
4. IQR (Interquartile Range, 사분위 범위): Q3 - Q1, IQR은 데이터의 중간 50% 범위를 의미합니다.
5. Minimum: Q1 − 1.5 × IQR 이하에 속하지 않는 가장 작은 값
6. Maximum: Q3 + 1.5 × IQR 이하에 속하지 않는 가장 큰 값
7. 이상치: 일반적인 데이터 분포를 벗어난 값(Lower Bound=Q1−1.5×IQR, Upper Bound=Q3+1.5×IQR)
>IQR 기준으로 이상치를 정의하기 때문에 모든 상황에 완벽하지 않을 수 있습니다
예시 1)
sns.boxplot(rent_df['Rent'])-->

예시 2)
sns.boxplot(rent_df['Size'])-->

예시 3)
sns.boxplot(rent_df['BHK'])-->

예시 4)
# rent_df.isna()는 데이터프레임 rent_df에서 각 값이 결측치(NA 또는 NaN)인지 확인한다.
# - 결과는 같은 크기의 데이터프레임이며, 값이 결측치일 경우 True, 아니면 False로 표시된다.
# .sum()은 True 값을 1로 간주하고, 각 열에 대해 True 값의 개수를 계산한다.
# - 즉, 각 열에서 결측치(NA 또는 NaN)의 개수를 반환한다.
# rent_df.isna().sum()의 동작:
# - rent_df에서 각 열에 포함된 결측치 개수를 계산하여 반환.
# - 반환값은 Pandas Series 객체이며, 각 열 이름과 해당 열의 결측치 개수가 포함된다.
# 이 결과를 사용하면 데이터 정리 과정에서 결측치를 처리하기 위한 계획을 세울 수 있다.
# 예: 결측치를 대체(imputation)하거나 삭제(drop)하는 작업.
rent_df.isna().sum()
-->-->

예시 5)
# rent_df.isna()는 데이터프레임 rent_df에서 각 값이 결측치(NA 또는 NaN)인지 확인한다.
# - 결과는 동일한 크기의 데이터프레임으로, 값이 결측치일 경우 True, 그렇지 않을 경우 False로 표시된다.
# .mean()은 각 열에 대해 True 값을 평균값으로 계산한다.
# - True는 1로, False는 0으로 간주되므로, 결측치의 비율(전체 값 중 결측치가 차지하는 비율)을 반환한다.
# rent_df.isna().mean()의 동작:
# - rent_df에서 각 열의 결측치 비율을 계산하여 반환.
# - 반환값은 Pandas Series 객체로, 각 열 이름과 결측치 비율(0~1 사이의 값)이 포함된다.
# 이 결과를 사용하여 데이터 정리 과정에서 결측치의 심각도를 파악할 수 있다.
# 예:
# - 결측치 비율이 높은 열은 삭제하거나 대체(imputation) 작업이 필요할 수 있음.
# - 결측치 비율이 0이면 해당 열에 결측치가 없음을 의미.
rent_df.isna().mean()
-->-->

예시 6)
# rent_df.info()는 데이터프레임 rent_df의 구조적 정보를 요약해서 출력한다.
# 이 메서드는 데이터프레임의 전체적인 구조와 각 열의 데이터 타입, 결측치 여부, 메모리 사용량 등을 빠르게 확인할 수 있다.
rent_df.info()
-->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4746 entries, 0 to 4745
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Posted On 4746 non-null object
1 BHK 4746 non-null int64
2 Rent 4746 non-null int64
3 Size 4746 non-null int64
4 Floor 4746 non-null object
5 Area Type 4746 non-null object
6 Area Locality 4746 non-null object
7 City 4746 non-null object
8 Furnishing Status 4746 non-null object
9 Tenant Preferred 4746 non-null object
10 Bathroom 4746 non-null int64
11 Point of Contact 4746 non-null object
dtypes: int64(4), object(8)
memory usage: 445.1+ KB
예시 7)
# rent_df['Area Type']는 데이터프레임 rent_df에서 'Area Type' 열을 선택한다.
# 이 열은 일반적으로 지역 유형(예: 건물 유형, 도시 구역 등)을 나타낼 것으로 예상된다.
# Pandas의 .unique() 메서드는 선택된 열에서 고유한 값들을 배열 형태로 반환한다.
# rent_df['Area Type'].unique()의 동작:
# - 'Area Type' 열에서 중복을 제거한 고유한 값들을 추출.
# - 반환된 값은 NumPy 배열 형태로, 열에 존재하는 모든 고유한 지역 유형이 포함된다.
rent_df['Area Type'].unique()
-->
array(['Super Area', 'Carpet Area', 'Built Area'], dtype=object)
예시 8)
# rent_df['Area Type']는 데이터프레임 rent_df에서 'Area Type' 열을 선택한다.
# 이 열은 지역 유형과 관련된 값을 포함할 것으로 예상된다.
# .nunique() 메서드는 선택된 열에서 고유한 값(unique value)의 개수를 계산하고 반환한다.
# rent_df['Area Type'].nunique()의 동작:
# - 'Area Type' 열에서 중복을 제거한 고유한 값들의 개수를 계산.
# - 반환 값은 정수(int)이며, 열에 존재하는 고유한 값의 총 개수를 나타낸다.
rent_df['Area Type'].nunique()
-->
3
예시 9)
# 여러 열에 대해 고유값의 개수를 확인하기 위해 반복문을 사용한다.
# 열 이름이 포함된 리스트를 정의하고, 각 열에서 고유값의 개수를 계산하여 출력한다.
# 반복문에서 사용되는 리스트:
# ['Floor', 'Area Type', 'Area Locality', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']
# - 이 리스트는 rent_df 데이터프레임에서 확인할 열 이름들로 구성되어 있다.
# 반복문 설명:
# - for i in [list]: 리스트에 포함된 각 열 이름을 변수 i에 할당하며 반복.
# - rent_df[i].nunique(): 데이터프레임 rent_df에서 i에 해당하는 열의 고유값 개수를 계산.
# - print(i, rent_df[i].nunique()): 열 이름(i)과 고유값 개수를 함께 출력.
# 출력된 값의 의미:
# - 각 행은 열 이름(i)과 해당 열의 고유값 개수를 보여준다.
# - 예를 들어, 'Floor' 열에는 43개의 고유값이 있고, 'Area Type' 열에는 3개의 고유값이 존재한다는 의미.
# 사용 목적:
# - 데이터 탐색: 각 열의 고유값 개수를 확인하여 데이터의 다양성과 특성을 파악.
# - 데이터 처리: 고유값의 개수가 많거나 적은 열을 기준으로 전처리 전략을 수립.
# 예: 고유값이 많은 'Area Locality'는 군집화 또는 축약 처리가 필요할 수 있다.
for i in ['Floor', 'Area Type', 'Area Locality', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']:
print(i, rent_df[i].nunique())
-->
Floor 480
Area Type 3
Area Locality 2235
City 6
Furnishing Status 3
Tenant Preferred 3
Point of Contact 3
예시 10)
# rent_df.drop()은 데이터프레임에서 특정 열 또는 행을 삭제하는 메서드이다.
# 여기서는 열을 삭제하려고 한다.
# 매개변수 설명:
# - ['Floor', 'Area Locality', 'Posted On']: 삭제할 열(column)의 이름을 리스트로 제공.
# - axis=1: 열을 기준으로 삭제하도록 지정. (axis=0이면 행을 삭제)
# - inplace=True: 원본 데이터프레임(rent_df)을 직접 수정.
# (inplace=False가 기본값이며, False일 경우 수정된 데이터프레임을 반환하고 원본은 유지됨)
# 사용 목적:
# - 'Floor', 'Area Locality', 'Posted On' 열이 분석이나 모델링에 필요하지 않다고 판단되어 제거.
# - 데이터프레임의 크기를 줄이거나, 관련 없는 데이터를 제거하여 전처리를 단순화.
# 참고:
# - inplace=True를 사용하지 않고, inplace=False로 설정하면
# rent_df = rent_df.drop(['Floor', 'Area Locality', 'Posted On'], axis=1)
# 형태로 반환된 수정된 데이터프레임을 새 변수나 원본에 저장해야 함.
# - 데이터프레임 rent_df에서 'Floor', 'Area Locality', 'Posted On' 열이 삭제된다.
rent_df.drop(['Floor', 'Area Locality', 'Posted On'], axis=1, inplace=True)
예시 11)
# pd.get_dummies()는 범주형 데이터를 원-핫 인코딩(one-hot encoding) 방식으로 변환하는 함수이다.
# 원-핫 인코딩은 각 범주형 값을 0과 1로 이루어진 이진 벡터로 변환한다.
# 예를 들어, 'City' 열에 'New York', 'Los Angeles', 'Chicago'가 있다면, 이 열은 다음처럼 변환된다:
# - 'City_New York', 'City_Los Angeles', 'City_Chicago'라는 새로운 열로 확장된다.
# - 데이터의 각 행은 해당 열에 1 또는 0을 표시한다.
# 매개변수 설명:
# - rent_df: 원본 데이터프레임.
# - columns=['Area Type', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']:
# 변환할 범주형 열(column)의 이름 리스트. 이 열들이 원-핫 인코딩으로 변환된다.
rent_df = pd.get_dummies(
rent_df,
columns=['Area Type', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']
)
# 동작:
# - 지정된 열(['Area Type', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact'])을 원-핫 인코딩으로 변환.
# - 기존 열은 삭제되고, 각 범주형 값에 대해 새로운 열이 생성된다.
# - 결과적으로 rent_df는 확장된 형태의 데이터프레임으로 업데이트된다.
# 각 요소의 의미:
# - 'Area Type_Built-up Area', 'Area Type_Carpet Area': 원-핫 인코딩으로 생성된 열.
# 특정 행이 'Built-up Area'에 해당하면 해당 열의 값은 1, 그렇지 않으면 0.
# - 'City_New York', 'City_Los Angeles': 'City' 열에서 각 도시를 나타내는 원-핫 인코딩 열.
# - 나머지 열들도 같은 방식으로 변환.
# 사용 목적:
# - 머신러닝 모델은 범주형 데이터를 직접 처리할 수 없으므로, 이를 수치형 데이터로 변환하기 위해 사용.
# - 원-핫 인코딩은 범주형 데이터를 수치화하면서 순서 정보 없이 각 범주를 독립적으로 표현.
# .head() 메서드는 rent_df의 상위 5개의 행을 출력한다.
rent_df.head()-->

예시 12)
# 데이터프레임 rent_df에서 머신러닝 모델에 사용할 독립변수(X)와 종속변수(y)를 정의한다.
# X: 독립변수(features)
# - rent_df.drop('Rent', axis=1)는 'Rent' 열을 제외한 모든 열을 선택하여 독립변수로 지정.
# - axis=1은 열(column) 기준으로 데이터를 제거하라는 의미.
# - 'Rent' 열은 종속변수(y)이므로 독립변수(features)에서 제거한다.
# - 결과적으로, X에는 모델이 예측에 사용하는 입력 데이터가 포함된다.
X = rent_df.drop('Rent', axis=1) # 'Rent' 열 제거 -> 독립변수(features) 생성.
# y: 종속변수(target)
# - rent_df['Rent']는 데이터프레임 rent_df에서 'Rent' 열을 선택.
# - 'Rent'는 예측하고자 하는 값(월세)으로, 모델의 종속변수로 설정.
# - 결과적으로, y에는 모델이 학습하고 예측해야 하는 목표 데이터가 포함된다.
y = rent_df['Rent'] # 'Rent' 열 선택 -> 종속변수(target) 생성.
# 사용 목적:
# - X는 모델이 학습할 때 사용하는 입력 데이터(특징).
# - y는 모델이 예측해야 하는 출력 데이터(목표 변수).
# - 이 작업은 독립변수와 종속변수를 분리하여 머신러닝 모델링에 적합한 형태로 데이터를 준비하는 과정이다.
예시 13)
y.head()-->

예시 14)
# 데이터를 학습용(train)과 테스트용(test)으로 분리하는 과정이다.
# train_test_split은 사이킷런의 함수로, 독립변수(X)와 종속변수(y)를 입력으로 받아 데이터를 무작위로 분리한다.
# 매개변수 설명:
# - X: 독립변수(features), 즉 모델이 학습에 사용할 입력 데이터.
# - y: 종속변수(target), 즉 모델이 예측해야 하는 출력 데이터.
# - test_size=0.3: 전체 데이터의 30%를 테스트 데이터로 사용. 나머지 70%는 학습 데이터로 사용.
# - random_state=2025: 랜덤 시드를 고정하여 동일한 데이터 분할 결과를 재현 가능하도록 설정.
X_train, X_test, y_train, y_test = train_test_split(
X, # 독립변수(features)
y, # 종속변수(target)
test_size=0.3, # 테스트 데이터 비율: 30%
random_state=2025 # 랜덤 시드 고정
)
# 반환값:
# - X_train: 학습용 독립변수(features).
# - X_test: 테스트용 독립변수(features).
# - y_train: 학습용 종속변수(target).
# - y_test: 테스트용 종속변수(target).
# 학습 데이터와 테스트 데이터의 크기를 확인:
# - X_train.shape: 학습용 독립변수의 데이터 크기(샘플 수, 특징 수).
# - X_test.shape: 테스트용 독립변수의 데이터 크기(샘플 수, 특징 수).
X_train.shape, X_test.shape
# 출력의 의미:
# - X_train.shape: 학습 데이터에는 700개의 샘플과 10개의 특징이 포함.
# - X_test.shape: 테스트 데이터에는 300개의 샘플과 10개의 특징이 포함.
# 사용 목적:
# - 데이터를 학습용과 테스트용으로 분리하여 모델이 학습하지 않은 데이터(X_test)에서 성능을 평가할 수 있도록 함.
# - 학습 데이터(X_train, y_train)로 모델을 학습한 뒤, 테스트 데이터(X_test, y_test)로 정확도를 평가.
X_train.shape, X_test.shape
-->
((3322, 21), (1424, 21))
y_train.shape, y_test.shape
-->
((3322,), (1424,))
4. 알고리즘으로 모델링
from sklearn.linear_model import LinearRegression
>선형 회귀
* 선형 회귀(Linear Regression)는 독립 변수(Feature)와 종속 변수(Target) 간의 선형적 관계(Linear Relationship)를 찾아내어 예측을 수행하는 통계적 모델입니다. * 주어진 데이터를 통해 최적의 직선(회귀선, Regression Line)을 찾아내며, 이 직선은 데이터 포인트와의 오차(Residuals)를 최소화하는 방향으로 설정됩니다.
* 수식으로는 y=wx+b로 표현되며, 여기서 w는 기울기(Weight), b는 절편(Bias)입니다. 주로 수식적 최적화(일반 최소제곱법, OLS)를 통해 학습되며, 해석이 명확하고 계산이 효율적이라는 장점이 있습니다.
> 최소 제곱법
* 최소 제곱법(Least Squares Method)은 주어진 데이터 포인트들과 예측 모델(주로 직선) 사이의 오차(Residuals)의 제곱합(Sum of Squared Errors, SSE)을 최소화하여 최적의 예측 모델을 찾아내는 통계적 방법입니다.
* 이 방법은 선형 회귀 분석에서 가장 널리 사용되며, 데이터 포인트들이 회귀선(Regression Line)에 최대한 가깝도록 조정합니다.
* 수학적으로는 오차의 제곱합을 최소화하는 기울기(w)와 절편(b)을 계산하여 모델을 최적화합니다.

예시 1)
# 선형 회귀(Linear Regression) 모델을 생성하고 학습시키며, 테스트 데이터로 예측을 수행하는 코드이다.
# 1. LinearRegression() 객체 생성:
# - lr = LinearRegression()는 선형 회귀 모델 객체를 생성.
# - 선형 회귀는 입력 특징(X)과 출력(y) 사이의 선형 관계를 학습하는 지도 학습 알고리즘.
lr = LinearRegression()
# 2. 모델 학습:
# - lr.fit(X_train, y_train)는 학습용 데이터(X_train, y_train)를 사용하여 모델을 학습시킨다.
# - fit() 메서드는 선형 회귀 모델의 가중치와 절편을 학습 데이터에 맞게 계산한다.
# - 학습된 모델은 독립변수 X와 종속변수 y 간의 선형 관계를 기반으로 새로운 데이터를 예측할 수 있다.
lr.fit(X_train, y_train)
# 3. 테스트 데이터 예측:
# - lr.predict(X_test)는 학습된 모델을 사용하여 테스트 데이터(X_test)에 대한 예측을 수행.
# - X_test는 테스트용 독립변수이며, predict() 메서드는 이 데이터를 입력으로 받아 종속변수의 값을 예측.
# - 반환값(pred)은 테스트 데이터에 대한 예측값(연속형 데이터) 배열이다.
pred = lr.predict(X_test)
# 사용 목적:
# - LinearRegression()으로 생성한 모델을 학습 데이터에 맞게 훈련하고, 테스트 데이터로 예측을 수행.
# - pred는 테스트 데이터의 실제 값(y_test)와 비교하여 모델 성능을 평가하는 데 사용.
예시 1-1)
pred
-->
array([168427.98865322, 37550.57051365, 46227.94809703, ...,
5359.0119441 , 55103.27974897, -13749.95956338])
예시 2)
from sklearn.metrics import mean_squared_error, root_mean_squared_error
print(mean_squared_error(y_test, pred))
print(root_mean_squared_error(y_test, pred))
-->
1845945611.7086728
42964.46917755034
-----------------------------
# sklearn.metrics 모듈에서 제공하는 mean_squared_error와 root_mean_squared_error를 사용하여 모델의 성능을 평가한다.
# 이 메트릭은 예측값(pred)과 실제값(y_test) 간의 차이를 측정하여 모델의 정확도를 평가한다.
from sklearn.metrics import mean_squared_error, root_mean_squared_error
# 1. Mean Squared Error (MSE):
# - mean_squared_error(y_test, pred)는 평균 제곱 오차(MSE)를 계산.
# - MSE는 예측값(pred)과 실제값(y_test) 간의 오차를 제곱하여 평균낸 값.
# - 값이 작을수록 예측값이 실제값에 더 가깝다는 의미.
# - 공식: MSE = Σ((y_test - pred)^2) / N
# (N은 샘플 수)
print(mean_squared_error(y_test, pred))
# 2. Root Mean Squared Error (RMSE):
# - root_mean_squared_error(y_test, pred)는 MSE의 제곱근을 계산하여 RMSE를 구한다.
# - RMSE는 오차의 크기를 원래 단위로 표현하므로 MSE보다 해석하기 더 쉽다.
# - 공식: RMSE = sqrt(MSE)
print(root_mean_squared_error(y_test, pred))
# 출력 결과:
# - 1845945611.7086728 (MSE): 예측값과 실제값 사이의 평균 제곱 오차.
# - 42964.46917755034 (RMSE): 평균 제곱 오차의 제곱근. 예측값과 실제값 간의 평균적인 오차를 나타냄.
# 예를 들어, 이 값은 월세 금액의 평균적인 예측 오차가 약 42,964 단위임을 의미.
# 사용 목적:
# - MSE와 RMSE를 사용하여 모델이 얼마나 정확히 예측했는지 평가.
# - 값이 작을수록 모델의 예측이 실제값에 더 가깝다는 것을 의미.
# - RMSE는 MSE에 비해 단위가 원래 데이터와 동일하므로 해석이 직관적임.
예시 3)
X_train.loc[1837]-->

예시 4)
y_train.loc[1837]
->
3500000
예시 5)
# 특정 인덱스(1837)에 해당하는 데이터를 학습용 데이터(X_train, y_train)에서 제거하는 코드이다.
# 1. X_train.drop(1837, inplace=True):
# - X_train은 독립변수(입력 데이터)를 포함한 데이터프레임이다.
# - drop(1837)는 데이터프레임 X_train에서 인덱스 1837에 해당하는 행(row)을 제거한다.
# - inplace=True는 원본 데이터프레임(X_train)을 직접 수정하여 행을 제거한다.
# (inplace=False가 기본값이며, False일 경우 수정된 데이터프레임을 반환하고 원본은 유지됨.)
X_train.drop(1837, inplace=True)
# 2. y_train.drop(1837, inplace=True):
# - y_train은 종속변수(목표값)를 포함한 Series 객체이다.
# - drop(1837)는 Series y_train에서 인덱스 1837에 해당하는 데이터를 제거한다.
# - inplace=True는 원본 Series(y_train)를 직접 수정하여 데이터를 제거한다.
y_train.drop(1837, inplace=True)
# 사용 목적:
# - 특정 인덱스(1837)에 해당하는 데이터가 이상치(outlier)거나 모델 학습에 부적합하다고 판단하여 제거.
# - 학습 데이터를 정리하고, 모델의 성능을 개선하기 위해 특정 데이터를 제거할 수 있음.
# - 제거 후 X_train과 y_train의 인덱스는 그대로 유지되며, 원래의 인덱스 번호는 변경되지 않음.
예시 6)
# 선형 회귀 모델을 학습하고, 새로운 예측값을 계산한 후, RMSE를 평가하는 코드이다.
# 1. 선형 회귀 모델 객체 생성:
# - lr = LinearRegression()는 선형 회귀 모델 객체를 생성.
# - LinearRegression은 입력 특징(X)과 출력(y) 사이의 선형 관계를 학습하는 알고리즘.
lr = LinearRegression()
# 2. 모델 학습:
# - lr.fit(X_train, y_train)는 학습용 데이터(X_train, y_train)를 사용하여 모델을 학습시킨다.
# - fit() 메서드는 선형 회귀 모델의 가중치와 절편을 학습 데이터에 맞게 계산한다.
lr.fit(X_train, y_train)
# 3. 새로운 예측 수행:
# - lr.predict(X_test)는 학습된 모델을 사용하여 테스트 데이터(X_test)에 대한 예측값(new_pred)을 계산한다.
# - new_pred는 테스트 데이터의 독립변수(X_test)를 입력으로 받아 종속변수(y)의 예측값을 반환.
new_pred = lr.predict(X_test)
# 4. 새로운 RMSE 계산:
# - root_mean_squared_error(y_test, new_pred)는 새로운 예측값(new_pred)과 실제값(y_test) 간의 RMSE를 계산.
# - RMSE(Root Mean Squared Error)는 평균 제곱 오차(MSE)의 제곱근으로, 모델의 예측 오차 크기를 나타낸다.
# - 공식: RMSE = sqrt(Σ((y_test - new_pred)^2) / N), N은 데이터 샘플 수.
root_mean_squared_error(y_test, new_pred)
-->
42987.37959096641
# 반환 값:
# - RMSE 값은 테스트 데이터에서 모델이 평균적으로 얼마나 오차가 있는지를 나타낸다.
# - 값이 작을수록 모델의 예측이 실제값에 더 가깝다는 의미.
# 사용 목적:
# - 학습 데이터에서 특정 이상치(1837번 데이터)를 제거한 후, 모델 성능이 개선되었는지 확인.
# - 새로운 RMSE 값이 이전 값보다 작다면, 이상치 제거가 모델 성능에 긍정적인 영향을 미쳤음을 의미.
예시 7)
#pred - new_pred
42964.46917755034 - 42987.37959096641
-->
-22.910413416073425
5. 로그 변환으로 RMSE 개선
* 주택 임대료 데이터셋은 오른쪽으로 치우친 분포를 가지고 있습니다.
* 값이 큰 임대료(Outliers)가 평균과 모델 예측 결과에 큰 영향을 미치기 때문에 로그 변환을 통해 값의 범위를 축소하고, 분포를 정규 분포(Normal Distribution)에 가깝게 만듭니다.
* 로그 변환은 극단적으로 높은 값의 영향을 줄여주기 때문에 모델이 이상치에 덜 민감하게 반응하고 RMSE가 감소할 수 있습니다.
> 정규 분포
* 정규 분포(Normal Distribution)는 데이터가 평균을 중심으로 좌우 대칭을 이루며 종 모양(Bell Curve)으로 퍼져 있는 통계적 분포입니다.
* 대부분의 값은 평균 근처에 몰려 있고, 평균에서 멀어질수록 값의 빈도가 급격히 감소합니다.
* 이는 자연현상, 시험 점수, 사람들의 키와 같은 많은 실제 데이터에서 흔하게 나타납니다.
예시 1)
# 로그 변환을 사용하여 종속 변수(y_train, y_test)를 변환한 뒤, 선형 회귀 모델을 학습하고,
# 테스트 데이터에 대한 예측값을 원래 값으로 변환한 후, RMSE를 계산하는 코드이다.
# 1. 로그 변환:
# - np.log1p(y_train): y_train에 자연 로그를 적용한 값으로 변환 (log(1 + y_train)).
# 로그 변환은 데이터의 스케일을 줄이고, 값이 큰 데이터의 영향을 완화하여 모델 성능을 향상시킬 수 있음.
# - np.log1p(y_test): 테스트 데이터 y_test에도 동일한 변환을 적용.
y_train = np.log1p(y_train)
y_test = np.log1p(y_test)
# 2. 선형 회귀 모델 객체 생성 및 학습:
# - lr = LinearRegression()는 선형 회귀 모델 객체를 생성.
# - lr.fit(X_train, y_train)는 학습용 데이터(X_train, y_train)를 사용하여 모델을 학습.
lr = LinearRegression()
lr.fit(X_train, y_train)
# 3. 테스트 데이터 예측:
# - lr.predict(X_test)는 학습된 모델로 테스트 데이터(X_test)에 대한 예측값(y_pred_log)을 계산.
# - 예측값(y_pred_log)은 로그 변환된 스케일에서의 값.
y_pred_log = lr.predict(X_test)
# 4. 로그 변환된 예측값과 실제값을 원래 스케일로 변환:
# - np.expm1(y_pred_log): 로그 변환된 예측값(y_pred_log)을 원래 값으로 되돌림 (expm1은 exp(x) - 1을 계산).
# - np.expm1(y_test): 로그 변환된 실제값(y_test)을 원래 값으로 되돌림.
log_pred = np.expm1(y_pred_log)
y_test_original = np.expm1(y_test)
# 5. RMSE 계산:
# - root_mean_squared_error(y_test_original, log_pred)는 원래 스케일에서의 예측값(log_pred)과 실제값(y_test_original) 간의 RMSE를 계산.
# - RMSE는 평균적인 예측 오차를 나타내며, 값이 작을수록 예측이 정확함을 의미.
root_mean_squared_error(y_test_original, log_pred)
# 사용 목적:
# - 로그 변환은 데이터의 분포가 치우쳐 있을 때 모델의 학습 성능을 개선.
# - 모델 예측 후 로그 변환을 되돌려 실제값과 비교하여 성능 평가.
# - 이 방법은 특히 종속 변수의 값이 크게 분포하는 회귀 문제에서 효과적임.
6. 앙상블 모델 적용
* 앙상블 모델(Ensemble Model)은 여러 개의 머신러닝 모델을 조합하여 하나의 강력한 예측 모델을 만드는 방법입니다.
* 각 개별 모델(약한 학습기, Weak Learner)이 가진 장점을 결합하고 약점을 보완함으로써 예측 정확도와 안정성을 향상시킵니다.
* 대표적인 앙상블 기법으로는 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)이 있으며, 랜덤 포레스트(Random Forest)와 XGBoost는 각각 배깅과 부스팅을 대표하는 알고리즘입니다.
* 앙상블 모델은 특히 복잡한 문제나 다양한 패턴이 존재하는 데이터셋에서 뛰어난 성능을 발휘합니다.
> 랜덤 포레스트
* 랜덤 포레스트(Random Forest)는 다수의 결정 트리(Decision Tree)를 결합해 예측을 수행하는 앙상블 학습 방법입니다.
* 각각의 트리는 무작위로 선택된 데이터 샘플과 특성(feature)을 사용해 학습되며, 분류 문제에서는 다수결 투표, 회귀 문제에서는 평균을 통해 최종 예측값을 도출합니다.
* 이 방식은 과적합(overfitting) 위험을 줄이고 안정적인 성능을 보장하며, 비선형 관계를 잘 포착하고 이상치(outlier)에 강인한 특성을 가지고 있습니다.
* 또한, 변수 중요도(Feature Importance)를 제공해 어떤 특성이 예측에 중요한 역할을 하는지 이해할 수 있습니다.
> XGBoost
* XGBoost (eXtreme Gradient Boosting)는 그레디언트 부스팅(Gradient Boosting) 알고리즘을 기반으로 한 강력한 머신러닝 앙상블 모델입니다.
* 여러 개의 약한 학습기(Weak Learner), 주로 결정 트리(Decision Tree)를 순차적으로 학습시키며, 이전 트리의 오차를 보정해 예측 성능을 점진적으로 개선합니다.
* 정확도, 속도, 과적합 방지 측면에서 뛰어난 성능을 자랑하며, 결측치 처리, 과적합 제어, 병렬 학습 등의 기능을 지원합니다.
* 주로 복잡한 패턴을 학습해야 하는 대규모 데이터셋이나 비선형 데이터 문제에서 뛰어난 성능을 보입니다.
예시 1)
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
models = {
'Linear Regression': LinearRegression(),
'Random Forest': RandomForestRegressor(n_estimators=100, random_state=2025),
'XGBoost': XGBRegressor(n_estimators=100, random_state=2025)
}
-->
# 선형 회귀, 랜덤 포레스트, XGBoost 회귀 모델을 정의하여 모델 딕셔너리에 저장하는 코드이다.
# 이 코드는 여러 모델을 비교하거나 평가하는 데 사용된다.
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
# 1. 딕셔너리 형태로 여러 모델 정의:
# - 'Linear Regression': LinearRegression() 객체를 생성. 선형 회귀 모델.
# - 'Random Forest': RandomForestRegressor 객체를 생성. 랜덤 포레스트 회귀 모델.
# - n_estimators=100: 의사결정 나무의 개수를 100으로 설정.
# - random_state=2025: 랜덤 시드를 고정하여 동일한 결과를 재현 가능하도록 설정.
# - 'XGBoost': XGBRegressor 객체를 생성. XGBoost 회귀 모델.
# - n_estimators=100: 부스팅 반복 횟수를 100으로 설정.
# - random_state=2025: 랜덤 시드를 고정하여 동일한 결과를 재현 가능하도록 설정.
models = {
'Linear Regression': LinearRegression(), # 선형 회귀 모델
'Random Forest': RandomForestRegressor(n_estimators=100, random_state=2025), # 랜덤 포레스트 회귀 모델
'XGBoost': XGBRegressor(n_estimators=100, random_state=2025) # XGBoost 회귀 모델
}
# 사용 목적:
# - 여러 회귀 모델을 정의하고, 모델별 성능 비교나 평가를 수행하기 위해 사용.
# - models 딕셔너리로 각 모델에 접근하여 학습(fit), 예측(predict), 평가(metrics)를 통합적으로 관리 가능.
# - 예를 들어, for 루프를 사용하여 각 모델의 성능을 평가할 수 있다.
예시 2)
# 여러 회귀 모델을 학습시키고, 테스트 데이터에 대해 예측을 수행한 뒤, RMSE를 계산하여 모델 성능을 비교한다.
results = {} # 각 모델의 RMSE 값을 저장할 딕셔너리.
# models 딕셔너리에 정의된 각 모델을 순회하며 학습 및 평가 수행.
for model_name, model in models.items():
# 모델 학습:
# - 학습용 데이터(X_train, y_train)를 사용하여 모델을 학습시킨다.
model.fit(X_train, y_train)
# 테스트 데이터 예측:
# - 학습된 모델을 사용하여 테스트 데이터(X_test)에 대한 로그 스케일 예측값(y_pred_log)을 생성.
y_pred_log = model.predict(X_test)
# 로그 변환을 원래 값으로 복구:
# - np.expm1(y_pred_log)는 로그 변환된 예측값을 원래 스케일로 변환 (expm1은 exp(x) - 1 계산).
# - y_test도 원래 값으로 복구.
y_pred = np.expm1(y_pred_log)
y_test_original = np.expm1(y_test)
# RMSE 계산:
# - RMSE는 평균 제곱 오차(MSE)의 제곱근으로, 예측값과 실제값 간의 평균적인 오차를 나타냄.
# - RMSE 값이 작을수록 모델의 예측이 정확하다는 의미.
rmse = np.sqrt(mean_squared_error(y_test_original, y_pred))
# 결과 저장:
# - 각 모델의 이름과 RMSE 값을 results 딕셔너리에 저장.
results[model_name] = rmse
# 모델의 RMSE를 출력.
print(f'{model_name} RMSE: {rmse:.2f}')
# 최적 모델 확인:
# - min(results, key=results.get)는 RMSE 값이 가장 작은 모델의 이름을 반환.
best_model = min(results, key=results.get)
# 최적 모델 이름과 해당 RMSE를 출력.
print(f'Best Model: {best_model} RMSE: {results[best_model]:.2f}')
# 출력 예시:
# Linear Regression RMSE: 33187.45
# Random Forest RMSE: 33406.61
# XGBoost RMSE: 36102.18
# Best Model: Linear Regression RMSE: 33187.45
# 출력 내용 설명:
# - 각 모델의 RMSE 값: 테스트 데이터에서 예측값과 실제값 간의 평균적인 오차를 나타냄.
# - Best Model: RMSE가 가장 작은 모델로, 테스트 데이터에 대해 가장 정확한 예측을 수행한 모델.
# 예: Linear Regression 모델이 가장 낮은 RMSE(33187.45)를 기록하여 최적 모델로 선택됨.
----------------------------------------
results = {}
for model_name, model in models.items():
model.fit(X_train, y_train)
y_pred_log = model.predict(X_test)
# 로그 변환을 원래 값으로 복구
y_pred = np.expm1(y_pred_log)
y_test_original = np.expm1(y_test)
# RMSE 계산
rmse = np.sqrt(mean_squared_error(y_test_original, y_pred))
results[model_name] = rmse
print(f'{model_name} RMSE: {rmse:.2f}')
# 최적 모델 확인
best_model = min(results, key=results.get)
print(f'Best Model: {best_model} RMSE: {results[best_model]:.2f}')
-->
Linear Regression RMSE: 33187.45
Random Forest RMSE: 33406.61
XGBoost RMSE: 36102.18
Best Model: Linear Regression RMSE: 33187.45'LLM(Large Language Model)의 기초 > 데이터 분석' 카테고리의 다른 글
| 14. 파이토치로 구현한 논리 회귀 (2) | 2025.01.08 |
|---|---|
| 13. 서울 자전거 공유 수요 예측 데이터셋 (0) | 2025.01.08 |
| 11. 사이킷런 (0) | 2025.01.07 |
| 10. 파이토치로 구현한 선형 회귀 (2) | 2025.01.06 |
| 9. 파이토치 프레임워크 (2) | 2025.01.06 |