2025. 1. 9. 11:20ㆍLLM(Large Language Model)의 기초/머신러닝과 딥러닝
1. 호텔 예약 수요 데이터셋
데이터셋은 일반적으로 호텔 예약에 대한 수요 패턴을 분석하기 위한 데이터셋입니다. 이 데이터셋은 예약 취소, 체크인 날짜, 고객 유형, 체류 기간, 객실 유형, 예약 경로 등 다양한 요소를 포함하며, 주로 예약 트렌드 분석, 고객 행동 예측, 수요 예측 등에 사용됩니다.
데이터 다운받아서 구글 드라이브에 첨부해줍니다.
링크 주소 : https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand/data
Hotel booking demand
From the paper: hotel booking demand datasets
www.kaggle.com
2. 데이터셋 컬럼 설명
* hotel: 호텔 유형 (Resort Hotel, City Hotel)
* is_canceled: 예약 취소 여부 (0: 예약 유지, 1: 예약 취소)
* lead_time: 예약과 실제 체크인 사이의 기간(일 단위)
* arrival_date_year: 도착 연도
* arrival_date_month: 도착 월
* arrival_date_week_number: 해당 주의 주차
* arrival_date_day_of_month: 도착 일
* stays_in_weekend_nights: 주말(토, 일) 동안의 숙박일 수
* stays_in_week_nights: 주중(월~금) 동안의 숙박일 수
* adults: 성인 투숙객 수
* children: 어린이 투숙객 수
* babies: 유아 투숙객 수
* meal: 예약된 식사 유형
* country: 고객의 국가
* market_segment: 예약 시장 세그먼트
* distribution_channel: 예약 채널 (예: 온라인, 오프라인)
* is_repeated_guest: 재방문 여부
* previous_cancellations: 이전 예약 취소 횟수
* reserved_room_type: 예약된 객실 유형
* assigned_room_type: 실제 배정된 객실 유형
* booking_changes: 예약 변경 횟수
* deposit_type: 보증금 유형 (No Deposit, Non Refund, Refundable)
* days_in_waiting_list: 대기자 명단에 있었던 일 수
* customer_type: 고객 유형 (예: Transient, Group)
* adr: 평균 일일 요금 (유로)
* required_car_parking_spaces: 주차 공간 요구 수
* total_of_special_requests: 특별 요청 수
* reservation_status: 예약 상태 (Check-Out, Canceled, No-Show)
* reservation_status_date: 예약 상태가 마지막으로 업데이트된 날짜
3. 데이터 전처리 및 EDA
파이토치를 import 해줍니다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
자기 경로를 맞춰줍니다.
hotel_df = pd.read_csv('/본인의 구글드라이브 경로/hotel_bookings.csv')
hotel_df--->

예시 1)
hotel_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119390 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 119390 non-null object
1 is_canceled 119390 non-null int64
2 lead_time 119390 non-null int64
3 arrival_date_year 119390 non-null int64
4 arrival_date_month 119390 non-null object
5 arrival_date_week_number 119390 non-null int64
6 arrival_date_day_of_month 119390 non-null int64
7 stays_in_weekend_nights 119390 non-null int64
8 stays_in_week_nights 119390 non-null int64
9 adults 119390 non-null int64
10 children 119386 non-null float64
11 babies 119390 non-null int64
12 meal 119390 non-null object
13 country 118902 non-null object
14 market_segment 119390 non-null object
15 distribution_channel 119390 non-null object
16 is_repeated_guest 119390 non-null int64
17 previous_cancellations 119390 non-null int64
18 previous_bookings_not_canceled 119390 non-null int64
19 reserved_room_type 119390 non-null object
20 assigned_room_type 119390 non-null object
21 booking_changes 119390 non-null int64
22 deposit_type 119390 non-null object
23 agent 103050 non-null float64
24 company 6797 non-null float64
25 days_in_waiting_list 119390 non-null int64
26 customer_type 119390 non-null object
27 adr 119390 non-null float64
28 required_car_parking_spaces 119390 non-null int64
29 total_of_special_requests 119390 non-null int64
30 reservation_status 119390 non-null object
31 reservation_status_date 119390 non-null object
dtypes: float64(4), int64(16), object(12)
memory usage: 29.1+ MB
예시 2)
hotel_df.describe()
--->--->

예시 3)
# Seaborn 라이브러리의 displot() 함수는 데이터의 분포를 시각화하기 위해 히스토그램 또는 KDE(커널 밀도 추정) 그래프를 생성하는 데 사용됩니다.
# 여기서는 hotel_df 데이터프레임의 'lead_time' 열(예약이 이루어진 시점과 실제 체크인 날짜 사이의 시간 간격)을 기준으로
# 해당 값들의 분포를 그래프로 그립니다.
# 이 코드는 'lead_time' 열 값들이 주로 어떤 범위에 분포되어 있는지를 확인하기 위해 사용됩니다.
sns.displot(hotel_df['lead_time'])
-->
<seaborn.axisgrid.FacetGrid at 0x7d487bbc9ea0>--->

예시 4)
# Seaborn 라이브러리의 boxplot() 함수는 데이터의 분포를 요약하여 시각화하는 데 사용됩니다.
# 여기서는 hotel_df 데이터프레임의 'lead_time' 열(예약이 이루어진 시점과 실제 체크인 날짜 사이의 시간 간격)을 기준으로
# 박스플롯(box plot)을 생성합니다.
# 박스플롯은 데이터의 중심 경향(중앙값), 사분위 범위(IQR), 이상치(outlier)를 확인하는 데 유용합니다.
# 주요 구성 요소:
# - 상자(box): 데이터의 중간 50%(Q1~Q3, 즉 1사분위수와 3사분위수 사이)를 나타냅니다.
# - 중앙선(median line): 데이터의 중앙값을 나타냅니다.
# - 수염(whiskers): IQR의 1.5배 이내 범위를 나타내며, 이 범위 밖의 데이터는 이상치로 표시됩니다.
sns.boxplot(hotel_df['lead_time'])
-->
<Axes: ylabel='lead_time'>--->

예제 5)
# Q1과 Q3는 데이터의 1사분위수와 3사분위수를 계산하는 데 사용됩니다.
# 데이터프레임 hotel_df의 'lead_time' 열(예약과 실제 체크인 날짜 간의 시간)을 기준으로 사분위수를 계산합니다.
Q1 = hotel_df['lead_time'].quantile(0.25)
# Q1: 1사분위수(25번째 백분위수)를 계산합니다.
# 이는 데이터의 하위 25%에 해당하는 값으로, 데이터가 작은 쪽에서부터 25% 지점에 해당하는 값을 의미합니다.
Q3 = hotel_df['lead_time'].quantile(0.75)
# Q3: 3사분위수(75번째 백분위수)를 계산합니다.
# 이는 데이터의 하위 75%에 해당하는 값으로, 데이터가 작은 쪽에서부터 75% 지점에 해당하는 값을 의미합니다.
# 이 코드는 'lead_time' 데이터의 사분위 범위를 확인하거나, 이상치를 탐지하기 위한 추가 분석을 준비하는 데 사용됩니다.
print(Q1)
# 계산된 1사분위수(Q1)를 출력합니다.
-->
18.0
print(Q3)
# 계산된 3사분위수(Q3)를 출력합니다.
--->
160.0
예제 6)
# 이 코드는 IQR(Interquartile Range, 사분위 범위)을 계산하고, 이상치를 탐지하기 위한 하한선과 상한선을 설정합니다.
IQR = Q3 - Q1
# IQR: 사분위 범위를 계산합니다.
# 사분위 범위는 3사분위수(Q3)와 1사분위수(Q1)의 차이를 나타내며, 데이터의 중간 50%를 포함하는 범위입니다.
lower_bound = Q1 - 1.5 * IQR
# 하한선(lower bound): IQR의 1.5배를 1사분위수(Q1)에서 뺀 값입니다.
# 하한선보다 작은 값들은 일반적으로 이상치(outlier)로 간주됩니다.
upper_bound = Q3 + 1.5 * IQR
# 상한선(upper bound): IQR의 1.5배를 3사분위수(Q3)에 더한 값입니다.
# 상한선보다 큰 값들도 일반적으로 이상치로 간주됩니다.
# 이 코드는 'lead_time' 열에서 이상치를 정의하고, 이상치 탐지를 위해 필요한 기준을 설정하는 데 사용됩니다.
print(lower_bound)
# 계산된 하한선을 출력합니다.
-->
-195.0
print(upper_bound)
# 계산된 상한선을 출력합니다.
-->
373.0
예제 7)
# 이 코드는 데이터프레임 hotel_df에서 'lead_time' 열의 이상치를 제거한 후, 필터링된 데이터프레임의 행 수를 계산합니다.
hotel_df = hotel_df[(hotel_df['lead_time'] >= lower_bound) & (hotel_df['lead_time'] <= upper_bound)]
# 데이터프레임 필터링:
# 'lead_time' 값이 하한선(lower_bound) 이상이고 상한선(upper_bound) 이하인 행만 선택합니다.
# 즉, 사분위 범위(IQR)의 1.5배를 기준으로 이상치로 간주된 값들은 제거됩니다.
len(hotel_df)
# 필터링된 데이터프레임 hotel_df의 행 수(레코드 개수)를 계산하고 반환합니다.
# 이는 이상치를 제거한 후 남아있는 데이터의 크기를 확인하는 데 사용됩니다.
--->
116385
예제 8)
# Seaborn 라이브러리의 boxplot() 함수는 데이터의 분포를 시각적으로 요약하여 표시하는 데 사용됩니다.
# 여기서는 hotel_df 데이터프레임의 'lead_time' 열(예약이 이루어진 시점과 실제 체크인 날짜 사이의 시간 간격)을 기준으로
# 박스플롯(box plot)을 생성합니다.
# 박스플롯 구성 요소:
# - 상자(box): 데이터의 중간 50% (1사분위수(Q1)에서 3사분위수(Q3) 사이)를 나타냅니다.
# - 중앙선(median line): 데이터의 중앙값(중간에 위치한 값)을 표시합니다.
# - 수염(whiskers): IQR(사분위 범위)의 1.5배 이내 범위를 나타냅니다.
# - 이상치(outlier): 수염 밖에 위치한 데이터 포인트를 점으로 표시합니다.
# 이 그래프는 'lead_time' 열 값의 분포, 중앙값, 변동성, 그리고 이상치가 있는지 여부를 쉽게 확인할 수 있도록 시각화합니다.
sns.boxplot(hotel_df['lead_time'])
--->
<Axes: ylabel='lead_time'>---->

예제 9)
# Seaborn 라이브러리의 barplot() 함수는 범주형 데이터와 수치형 데이터 간의 관계를 시각화하는 막대 그래프를 생성합니다.
# 여기서는 hotel_df 데이터프레임의 'distribution_channel'(예약 채널)별로 'is_canceled'(예약 취소 여부)의 평균 값을 표시합니다.
# x: 범주형 데이터로 'distribution_channel' 열을 설정합니다.
# y: 수치형 데이터로 'is_canceled' 열을 설정합니다.
# 'is_canceled' 열은 0(취소되지 않음)과 1(취소됨) 값을 가지므로, 막대 그래프의 높이는 각 예약 채널에서 취소된 예약의 비율을 나타냅니다.
# 예를 들어:
# - 특정 'distribution_channel'에서 막대의 높이가 0.3이라면, 해당 채널에서 예약이 취소될 확률이 30%임을 의미합니다.
# - 모든 'distribution_channel'에 대해 평균 취소율을 비교할 수 있습니다.
# 이 그래프는 예약 채널별로 예약 취소율의 차이를 시각적으로 이해하는 데 유용합니다.
sns.barplot(x=hotel_df['distribution_channel'], y=hotel_df['is_canceled'])
--->
<Axes: xlabel='distribution_channel', ylabel='is_canceled'>--->

예제 10)
# 이 코드는 hotel_df 데이터프레임에서 'distribution_channel' 열의 값들을 세고,
# 각 값(즉, 각 예약 채널)의 발생 횟수를 계산합니다.
# value_counts():
# - 'distribution_channel' 열에서 각 고유 값(예약 채널)이 몇 번 나타나는지를 세어줍니다.
# - 결과는 예약 채널별로 데이터를 집계한 Series 형태로 반환됩니다.
# - 반환된 Series는 기본적으로 값이 많은 순서대로 정렬됩니다.
# 이 코드는 데이터 내에서 각 예약 채널의 사용 빈도를 분석하거나,
# 특정 채널이 데이터에서 얼마나 중요한지를 확인하는 데 유용합니다.
hotel_df['distribution_channel'].value_counts()
--->---->

예제 11)
# Seaborn 라이브러리의 barplot() 함수는 범주형 데이터와 수치형 데이터 간의 관계를 시각화하는 막대 그래프를 생성합니다.
# 여기서는 hotel_df 데이터프레임의 'hotel'(호텔 유형)별로 'is_canceled'(예약 취소 여부)의 평균 값을 표시합니다.
# x: 범주형 데이터로 'hotel' 열을 설정합니다.
# - 'hotel'은 호텔 유형을 나타내며, 예를 들어 "Resort Hotel"과 "City Hotel" 등의 값을 가질 수 있습니다.
# y: 수치형 데이터로 'is_canceled' 열을 설정합니다.
# - 'is_canceled'은 예약 취소 여부를 나타내며, 0(취소되지 않음)과 1(취소됨)의 값을 가집니다.
# - 막대 그래프의 높이는 각 호텔 유형에서 취소된 예약의 평균 비율(확률)을 나타냅니다.
# 예:
# - 특정 호텔 유형의 막대 높이가 0.4라면, 해당 호텔에서 예약이 취소될 확률이 40%임을 의미합니다.
# - 이를 통해 호텔 유형에 따른 예약 취소율의 차이를 비교할 수 있습니다.
# 이 그래프는 특정 호텔 유형(예: Resort Hotel vs. City Hotel)에서 예약 취소율이 어떻게 다른지 시각적으로 보여주는 데 유용합니다.
sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
--->
<Axes: xlabel='hotel', ylabel='is_canceled'>--->

예제 12)
# 이 코드는 hotel_df 데이터프레임에서 'hotel' 열의 각 고유 값(호텔 유형)의 발생 빈도를 계산합니다.
# value_counts():
# - 'hotel' 열에서 각 고유 값(호텔 유형)이 몇 번 나타나는지를 세어줍니다.
# - 반환 결과는 각 호텔 유형별로 데이터가 몇 건 포함되어 있는지를 나타내는 Series 형태입니다.
# - 결과는 기본적으로 값이 많은 순서대로 정렬됩니다.
# 예:
# 데이터에 "Resort Hotel"이 300건, "City Hotel"이 700건 포함되어 있다면, 결과는 다음과 같습니다:
# City Hotel 700
# Resort Hotel 300
# 이 코드는 데이터에서 각 호텔 유형의 비중(즉, 해당 호텔 유형의 예약 수)을 분석하고,
# 특정 호텔 유형의 상대적 중요성을 확인하는 데 유용합니다.
hotel_df['hotel'].value_counts()
--->--->

예제 13)
# 이 코드는 호텔 예약 데이터에서 월별 예약 취소율을 시각화하기 위해 막대 그래프를 생성합니다.
plt.figure(figsize=(15, 5))
# plt.figure(): 새로운 그래프의 크기를 설정합니다.
# figsize=(15, 5): 가로 15인치, 세로 5인치 크기의 그래프를 생성하여,
# 월별 데이터를 명확하게 표시할 수 있도록 가로로 넓은 그래프를 만듭니다.
# sns.barplot():
# - x축: 'arrival_date_month' 열을 설정합니다.
# 이 열은 도착 날짜의 월을 나타내며, 예를 들어 "January", "February" 등의 값을 가질 수 있습니다.
# - y축: 'is_canceled' 열을 설정합니다.
# 'is_canceled'은 예약 취소 여부를 나타내며, 0(취소되지 않음)과 1(취소됨)의 값을 가집니다.
# - 막대의 높이는 각 월별로 취소된 예약의 평균 비율(취소 확률)을 나타냅니다.
# 그래프의 의미:
# - 각 월별로 예약 취소율을 비교할 수 있습니다.
# - 예를 들어, "January" 막대의 높이가 0.2라면, 해당 월의 예약 취소 확률이 20%임을 의미합니다.
# - 특정 월에 취소율이 높은지 낮은지를 확인하여, 계절적 또는 월별 경향을 분석하는 데 유용합니다.
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'])
--->
<Axes: xlabel='arrival_date_month', ylabel='is_canceled'>--->

예제 14)
# 이 코드는 calendar 모듈을 사용하여 월 이름을 출력합니다.
# calendar.month_name은 1부터 12까지의 정수 인덱스에 해당하는 월 이름을 반환하는 리스트입니다.
print(calendar.month_name[1])
# calendar.month_name[1]: "January"를 반환합니다.
# 리스트의 첫 번째 요소(인덱스 1)는 1월(January)을 나타냅니다.
print(calendar.month_name[2])
# calendar.month_name[2]: "February"를 반환합니다.
# 리스트의 두 번째 요소(인덱스 2)는 2월(February)을 나타냅니다.
print(calendar.month_name[3])
# calendar.month_name[3]: "March"를 반환합니다.
# 리스트의 세 번째 요소(인덱스 3)는 3월(March)을 나타냅니다.
# calendar.month_name은 1부터 12까지의 인덱스에 월 이름이 매핑된 리스트로,
# 0번 인덱스는 빈 문자열("")로 설정되어 있습니다.
# 이를 통해 숫자를 월 이름으로 쉽게 변환할 수 있습니다.
--->
import calendar
print(calendar.month_name[1])
print(calendar.month_name[2])
print(calendar.month_name[3])
-->
January
February
March
예제 15)
# 이 코드는 calendar 모듈을 사용하여 1월부터 12월까지의 월 이름을 리스트에 저장합니다.
months = []
# 빈 리스트 months를 생성합니다. 이 리스트는 월 이름을 저장하는 데 사용됩니다.
for i in range(1, 13):
# for 루프: 1부터 12까지의 숫자(i)를 반복합니다.
# 1부터 12까지는 각각 1월부터 12월에 해당합니다.
months.append(calendar.month_name[i])
# calendar.month_name[i]: 현재 반복 중인 숫자 i에 해당하는 월 이름을 반환합니다.
# 예: i=1이면 "January", i=2이면 "February" 등.
# 반환된 월 이름을 months 리스트에 추가합니다.
months
# 반복이 끝난 후, months 리스트에는 1월부터 12월까지의 월 이름이 순서대로 저장되어 있습니다.
# 최종 결과는 다음과 같습니다:
# ['January', 'February', 'March', 'April', 'May', 'June',
# 'July', 'August', 'September', 'October', 'November', 'December']
---->
months = []
for i in range(1, 13):
months.append(calendar.month_name[i])
months
예제 16)
# 이 코드는 호텔 예약 데이터에서 월별 예약 취소율을 시각화하는 막대 그래프를 생성하며,
# 월 순서를 지정하여 그래프의 가독성을 높입니다.
plt.figure(figsize=(15, 5))
# plt.figure(): 새로운 그래프의 크기를 설정합니다.
# figsize=(15, 5): 가로 15인치, 세로 5인치 크기의 그래프를 생성하여,
# 월별 데이터를 넓은 화면에 명확하게 표시합니다.
# sns.barplot():
# - x축: 'arrival_date_month' 열을 설정합니다.
# 이 열은 도착 날짜의 월을 나타내며, 예를 들어 "January", "February" 등의 값을 가질 수 있습니다.
# - y축: 'is_canceled' 열을 설정합니다.
# 'is_canceled'은 예약 취소 여부를 나타내며, 0(취소되지 않음)과 1(취소됨)의 값을 가집니다.
# - order=months:
# - 월 이름의 순서를 강제로 지정합니다.
# - months 리스트는 ['January', 'February', ..., 'December']와 같은 월 이름을 포함하고 있어,
# 데이터가 월 순서대로 정렬되도록 보장합니다.
# 데이터가 사전순으로 정렬되지 않고 1월부터 12월까지 순서대로 표시됩니다.
# 이 그래프는 각 월의 평균 예약 취소율을 보여줍니다.
# 예를 들어:
# - "January" 막대의 높이가 0.25라면, 1월의 평균 예약 취소 확률이 25%임을 의미합니다.
# 이 그래프는 계절적 경향이나 특정 월의 취소율 차이를 분석하는 데 유용합니다.
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'], order=months)
--->
<Axes: xlabel='arrival_date_month', ylabel='is_canceled'>---->

예제 17)
hotel_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 116385 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 116385 non-null object
1 is_canceled 116385 non-null int64
2 lead_time 116385 non-null int64
3 arrival_date_year 116385 non-null int64
4 arrival_date_month 116385 non-null object
5 arrival_date_week_number 116385 non-null int64
6 arrival_date_day_of_month 116385 non-null int64
7 stays_in_weekend_nights 116385 non-null int64
8 stays_in_week_nights 116385 non-null int64
9 adults 116385 non-null int64
10 children 116381 non-null float64
11 babies 116385 non-null int64
12 meal 116385 non-null object
13 country 115897 non-null object
14 market_segment 116385 non-null object
15 distribution_channel 116385 non-null object
16 is_repeated_guest 116385 non-null int64
17 previous_cancellations 116385 non-null int64
18 previous_bookings_not_canceled 116385 non-null int64
19 reserved_room_type 116385 non-null object
20 assigned_room_type 116385 non-null object
21 booking_changes 116385 non-null int64
22 deposit_type 116385 non-null object
23 agent 100193 non-null float64
24 company 6797 non-null float64
25 days_in_waiting_list 116385 non-null int64
26 customer_type 116385 non-null object
27 adr 116385 non-null float64
28 required_car_parking_spaces 116385 non-null int64
29 total_of_special_requests 116385 non-null int64
30 reservation_status 116385 non-null object
31 reservation_status_date 116385 non-null object
dtypes: float64(4), int64(16), object(12)
memory usage: 29.3+ MB
예제 18)
# 이 코드는 hotel_df 데이터프레임에서 각 열에 포함된 결측값(NaN)의 개수를 계산합니다.
# hotel_df.isna():
# - 데이터프레임의 각 셀에 대해 결측값(NaN) 여부를 확인합니다.
# - 결측값이 있는 경우 True를 반환하고, 그렇지 않으면 False를 반환합니다.
# - 반환 결과는 동일한 크기의 데이터프레임으로 표시됩니다.
# .sum():
# - 각 열(column)에 대해 True 값(결측값)의 개수를 합산합니다.
# - 결측값이 존재하는 열의 총 개수를 계산하여 반환합니다.
# 결과:
# - 반환 값은 각 열 이름과 해당 열에서 발견된 결측값의 개수로 구성된 Series입니다.
# - 예:
# column_1 5
# column_2 0
# column_3 12
# dtype: int64
# - 이는 column_1에는 결측값이 5개, column_2에는 결측값이 없고, column_3에는 결측값이 12개 있다는 것을 의미합니다.
# 이 코드는 데이터의 결측값 분포를 확인하고, 데이터 전처리 과정에서 결측값 처리가 필요한 열을 파악하는 데 사용됩니다.
hotel_df.isna().sum()--->
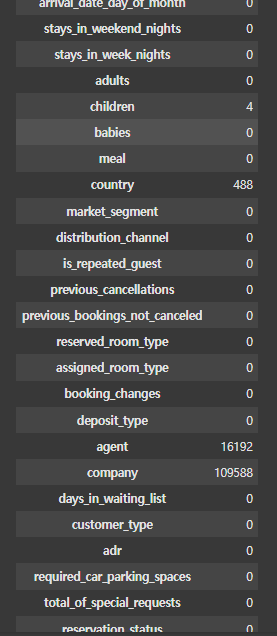
예제 19)
#hotel_df['children'].value_counts(dropna=False)
hotel_df['children'].value_counts()
--->
# 이 코드는 hotel_df 데이터프레임에서 'hotel' 열의 각 고유 값(호텔 유형)의 발생 빈도를 계산합니다.
# value_counts():
# - 'hotel' 열에서 각 고유 값(호텔 유형)이 몇 번 나타나는지를 세어줍니다.
# - 반환 결과는 각 호텔 유형별로 데이터가 몇 건 포함되어 있는지를 나타내는 Series 형태입니다.
# - 결과는 기본적으로 값이 많은 순서대로 정렬됩니다.
# 예:
# 데이터에 "Resort Hotel"이 300건, "City Hotel"이 700건 포함되어 있다면, 결과는 다음과 같습니다:
# City Hotel 700
# Resort Hotel 300
# 이 코드는 데이터에서 각 호텔 유형의 비중(즉, 해당 호텔 유형의 예약 수)을 분석하고,
# 특정 호텔 유형의 상대적 중요성을 확인하는 데 유용합니다.
hotel_df['hotel'].value_counts()
예제 20)
# 이 코드는 hotel_df 데이터프레임의 'children' 열에서 결측값(NaN)을 0으로 채웁니다.
# 'children' 열에서 결측값을 처리하기 위해 fillna() 메서드를 사용합니다.
# fillna(0):
# - 'children' 열에서 NaN(결측값)을 0으로 대체합니다.
# - 결측값을 0으로 설정하는 것은 해당 데이터가 "자녀가 없는 상태"를 나타낸다고 가정한 처리 방식입니다.
# - 이 작업은 결측값이 분석에 영향을 미치지 않도록 데이터를 정리하는 데 사용됩니다.
# 예:
# 원래 'children' 열의 값:
# [1, NaN, 2, NaN, 0]
# fillna(0) 적용 후:
# [1, 0, 2, 0, 0]
# 이 코드는 데이터 전처리 단계에서 결측값 처리를 수행하여,
# 'children' 열에서 NaN 값을 제거하고 분석 가능하도록 준비합니다.
hotel_df['children'] = hotel_df['children'].fillna(0)
--->
<ipython-input-23-c7c9f0491e27>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['children'] = hotel_df['children'].fillna(0)
예제 21)
hotel_df[hotel_df['adults'] == 0]
--->
# 이 코드는 hotel_df 데이터프레임에서 'adults' 열의 값이 0인 행만 필터링하여 반환합니다.
# hotel_df['adults'] == 0:
# - 'adults' 열에서 값이 0인 행을 찾습니다.
# - 조건식이 True인 경우 해당 행을 선택합니다.
# 예: 'adults' 열 값이 [2, 0, 1, 0]이라면, 조건식이 True인 행은 2번째(0)와 4번째(0) 행입니다.
# hotel_df[조건식]:
# - 조건식을 만족하는 행들만 데이터프레임 형태로 반환합니다.
# - 여기서는 'adults' 값이 0인 모든 행이 반환됩니다.
# 반환 결과:
# - 'adults'가 0인 예약 데이터만 포함된 새로운 데이터프레임이 출력됩니다.
# - 이는 성인이 없는 예약 데이터를 분석하거나 처리하는 데 사용됩니다.
# 주의:
# 성인이 0인 데이터는 비정상적인 예약 데이터일 가능성이 있으므로,
# 이를 통해 데이터 정합성 검증이나 이상치 처리를 수행할 수 있습니다.--->

예제 22)
# 이 코드는 hotel_df 데이터프레임에 새로운 열 'people'을 추가합니다.
# 'people' 열은 예약 시 포함된 성인(adults), 어린이(children), 아기(babies)의 총 인원을 나타냅니다.
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
# 'adults', 'children', 'babies' 열의 값을 더하여 'people' 열을 생성합니다.
# - 'adults': 성인의 수
# - 'children': 어린이의 수
# - 'babies': 아기의 수
# 각 행마다 위 3개 열의 값을 더한 결과가 새로운 'people' 열에 저장됩니다.
hotel_df.head()
# head(): 데이터프레임의 상위 5개 행을 출력합니다.
# 이를 통해 새로 추가된 'people' 열과 기존 데이터의 구조를 확인할 수 있습니다.
--->
<ipython-input-25-bfcd605c11fa>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']---->

예제 23)
# 이 코드는 hotel_df 데이터프레임에서 'people' 열의 값이 0인 행만 필터링하여 반환합니다.
# hotel_df['people'] == 0:
# - 'people' 열에서 값이 0인 행을 찾습니다.
# - 조건식이 True인 경우 해당 행이 선택됩니다.
# - 'people' 값이 0이라는 것은 성인(adults), 어린이(children), 아기(babies)의 합이 0임을 의미합니다.
# 즉, 예약에 포함된 사람이 아무도 없는 비정상적인 데이터입니다.
# hotel_df[조건식]:
# - 조건식을 만족하는 행들만 데이터프레임 형태로 반환합니다.
# - 여기서는 'people' 값이 0인 모든 행이 반환됩니다.
# 반환 결과:
# - 'people'이 0인 예약 데이터만 포함된 새로운 데이터프레임이 출력됩니다.
# - 이는 데이터의 정합성을 검토하거나 비정상적인 예약 데이터를 분석하는 데 사용됩니다.
hotel_df[hotel_df['people'] == 0]--->

예제 24)
#hotel_df = hotel_df[hotel_df['people'] != 0]
#179 rows people 삭제하기
hotel_df.drop(hotel_df[hotel_df['people'] == 0].index, inplace=True)
---->
# 이 코드는 hotel_df 데이터프레임에서 'people' 값이 0인 행을 삭제합니다.
hotel_df.drop(hotel_df[hotel_df['people'] == 0].index, inplace=True)
# hotel_df['people'] == 0:
# - 'people' 열의 값이 0인 행을 찾습니다.
# - 이는 성인(adults), 어린이(children), 아기(babies) 모두가 0인, 사람이 포함되지 않은 예약 데이터를 의미합니다.
# .index:
# - 조건을 만족하는 행(여기서는 'people' 값이 0인 행)의 인덱스를 반환합니다.
# - 해당 행들을 삭제하기 위해 필요한 행 번호를 제공합니다.
# hotel_df.drop(..., inplace=True):
# - drop() 메서드는 특정 행 또는 열을 데이터프레임에서 제거합니다.
# - 첫 번째 인수로 제거할 행의 인덱스를 전달합니다.
# - inplace=True:
# - 데이터프레임을 원본에서 바로 수정합니다.
# - 변경된 결과를 새 변수에 저장하지 않아도 원본 데이터프레임이 업데이트됩니다.
# 결과:
# - 'people' 값이 0인 모든 행이 데이터프레임에서 제거됩니다.
# - 비정상적인 예약 데이터를 삭제하여 데이터 정합성을 유지합니다.
# 참고:
# 'people' 값이 0인 데이터는 의미가 없거나 잘못 입력된 데이터일 가능성이 높으므로,
# 데이터 정리 과정에서 이를 삭제하는 것이 일반적입니다.
--->
<ipython-input-27-57205af2f238>:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(hotel_df[hotel_df['people'] == 0].index, inplace=True)
예제 25)
# 이 코드는 hotel_df 데이터프레임의 행(row) 개수를 계산하여 반환합니다.
len(hotel_df)
# len() 함수:
# - 데이터프레임의 총 행(row) 개수를 반환합니다.
# - 데이터프레임의 크기를 확인하거나 필터링, 삭제 후 남아있는 데이터의 개수를 확인하는 데 유용합니다.
# 예:
# 원래 데이터프레임에 1000개의 행이 있었다면,
# 'people' 값이 0인 179개의 행을 삭제한 후 len(hotel_df)를 실행하면, 결과는 821이 됩니다.
# 결과:
# - hotel_df 데이터프레임에 남아있는 총 행의 개수를 출력합니다.
# - 데이터 정리 작업이 올바르게 수행되었는지 확인하는 데 사용됩니다.
예제 26)
# 이 코드는 hotel_df 데이터프레임에서 'people' 열의 값이 0인 행만 필터링하여 반환합니다.
hotel_df[hotel_df['people'] == 0]
# hotel_df['people'] == 0:
# - 'people' 열에서 값이 0인 행을 찾습니다.
# - 조건식이 True인 경우 해당 행이 선택됩니다.
# - 'people' 값이 0이라는 것은 성인(adults), 어린이(children), 아기(babies)의 합이 0임을 의미합니다.
# 즉, 예약에 포함된 사람이 아무도 없는 비정상적인 데이터입니다.
# hotel_df[조건식]:
# - 조건식을 만족하는 행들만 데이터프레임 형태로 반환합니다.
# - 여기서는 'people' 값이 0인 모든 행이 반환됩니다.
# 반환 결과:
# - 'people'이 0인 예약 데이터만 포함된 새로운 데이터프레임이 출력됩니다.
# - 이는 데이터의 정합성을 검토하거나 비정상적인 예약 데이터를 분석하는 데 사용됩니다.
# 주의:
# 이전에 'people' 값이 0인 데이터를 삭제한 경우, 결과는 빈 데이터프레임이 반환됩니다.
# 이는 데이터 정리 작업이 성공적으로 수행되었음을 나타냅니다.
예제 27)
hotel_df.drop(['adults', 'children', 'babies'], axis=1, inplace=True)
--->
<ipython-input-30-f9dffa2f4f78>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(['adults', 'children', 'babies'], axis=1, inplace=True)
예제 28)
hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
hotel_df.head()
--->
# 이 코드는 hotel_df 데이터프레임에 새로운 열 'total_nights'를 추가합니다.
# 'total_nights' 열은 예약된 총 숙박일수를 나타냅니다.
hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
# 'stays_in_week_nights'와 'stays_in_weekend_nights' 열의 값을 더하여 'total_nights' 열을 생성합니다.
# - 'stays_in_week_nights': 평일(월~금) 동안 숙박한 일수.
# - 'stays_in_weekend_nights': 주말(토~일) 동안 숙박한 일수.
# 각 행마다 위 두 열의 값을 더한 결과가 'total_nights' 열에 저장됩니다.
hotel_df.head()
# head(): 데이터프레임의 상위 5개 행을 출력합니다.
# 이를 통해 새로 추가된 'total_nights' 열과 기존 데이터의 구조를 확인할 수 있습니다.
# 예:
# 원래 데이터가 다음과 같다면:
# | stays_in_week_nights | stays_in_weekend_nights |
# |----------------------|-------------------------|
# | 3 | 2 |
# | 5 | 0 |
#
# 'total_nights' 열이 추가된 데이터는 다음과 같이 표시됩니다:
# | stays_in_week_nights | stays_in_weekend_nights | total_nights |
# |----------------------|-------------------------|--------------|
# | 3 | 2 | 5 |
# | 5 | 0 | 5 |
--->
<ipython-input-31-7baafaaa2af0>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']--->

예제 29)
hotel_df.drop(['stays_in_week_nights', 'stays_in_weekend_nights'], axis=1, inplace=True)
-->
# 이 코드는 hotel_df 데이터프레임에서 'stays_in_week_nights'와 'stays_in_weekend_nights' 열을 삭제합니다.
# drop():
# - 특정 열이나 행을 데이터프레임에서 삭제하는 메서드입니다.
# - 첫 번째 인수에 삭제할 열(또는 행)을 리스트 형태로 전달합니다.
# 여기서는 ['stays_in_week_nights', 'stays_in_weekend_nights'] 열을 삭제 대상으로 지정합니다.
# axis=1:
# - 삭제할 대상이 열(columns)임을 나타냅니다.
# - axis=0은 행(rows)을 삭제할 때 사용합니다.
# inplace=True:
# - True로 설정하면 데이터프레임의 원본이 직접 수정됩니다.
# - False(기본값)로 설정하면 수정된 데이터프레임이 반환되며, 원본은 그대로 유지됩니다.
# 결과:
# - 'stays_in_week_nights'와 'stays_in_weekend_nights' 열이 데이터프레임에서 제거됩니다.
# - 데이터프레임에 'total_nights' 열이 이미 추가되어 있으므로,
# 이 두 열을 제거해 중복 정보를 없애고 데이터프레임을 간소화합니다.
# 사용 의도:
# - 데이터프레임의 크기를 줄이고 중복 데이터를 제거하여, 분석 및 처리 효율성을 높입니다.
--->
<ipython-input-32-b1c069c5ab91>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(['stays_in_week_nights', 'stays_in_weekend_nights'], axis=1, inplace=True)
예제 30)
# 이 코드는 'arrival_date_month'를 사용하여 계절(season) 정보를 생성하기 위해,
# 월 이름(month name)과 계절을 매핑하는 딕셔너리를 생성합니다.
season_dic = {'spring': [3, 4, 5], 'summer': [6, 7, 8], 'fall': [9, 10, 11], 'winter': [12, 1, 2]}
# season_dic:
# - 각 계절(season)에 해당하는 월(month)을 정의한 딕셔너리입니다.
# - 'spring'은 3월, 4월, 5월로 구성되고,
# 'summer'는 6월, 7월, 8월,
# 'fall'은 9월, 10월, 11월,
# 'winter'는 12월, 1월, 2월로 구성됩니다.
new_season_dic = {}
# new_season_dic:
# - 월 이름(month name)과 계절을 매핑하는 새로운 딕셔너리를 생성할 빈 딕셔너리입니다.
for i in season_dic:
# i: 계절 이름(예: 'spring', 'summer', 'fall', 'winter')을 순회합니다.
for j in season_dic[i]:
# j: 해당 계절에 포함된 월 번호(예: 3, 4, 5 등)를 순회합니다.
new_season_dic[calendar.month_name[j]] = i
# calendar.month_name[j]:
# - 월 번호 j를 사용해 해당 월의 이름(예: 'January', 'February', 'March')을 가져옵니다.
# new_season_dic[month_name] = i:
# - 월 이름을 키(key)로, 계절 이름을 값(value)으로 저장합니다.
# 결과:
# - new_season_dic은 월 이름을 키로 하고, 해당 월이 속하는 계절을 값으로 가진 딕셔너리가 생성됩니다.
--->
{'March': 'spring',
'April': 'spring',
'May': 'spring',
'June': 'summer',
'July': 'summer',
'August': 'summer',
'September': 'fall',
'October': 'fall',
'November': 'fall',
'December': 'winter',
'January': 'winter',
'February': 'winter'}
예제 31)
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
hotel_df.head()
--->
<ipython-input-34-9c7229666310>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)--->
예제 32)
# 이 코드는 hotel_df 데이터프레임에서 'arrival_date_month' 열을 삭제합니다.
# drop():
# - 특정 열이나 행을 데이터프레임에서 제거하는 메서드입니다.
# - 첫 번째 인수로 삭제할 열의 이름을 리스트 형태로 전달합니다.
# 여기서는 ['arrival_date_month'] 열을 삭제 대상으로 지정합니다.
# axis=1:
# - 삭제 대상이 열(columns)임을 나타냅니다.
# - axis=0은 행(rows)을 삭제할 때 사용합니다.
# inplace=True:
# - True로 설정하면 원본 데이터프레임(hotel_df)이 직접 수정됩니다.
# - False(기본값)로 설정하면 수정된 데이터프레임이 반환되며, 원본 데이터프레임은 그대로 유지됩니다.
# 결과:
# - hotel_df 데이터프레임에서 'arrival_date_month' 열이 삭제됩니다.
# 사용 의도:
# 'arrival_date_month' 열은 계절(season) 정보를 생성한 후 더 이상 필요하지 않을 수 있으므로,
# 이를 제거하여 데이터프레임을 간소화하고 중복 정보를 없앱니다.
hotel_df.drop(['arrival_date_month'], axis=1, inplace=True)
--->
<ipython-input-35-635f7152cd24>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(['arrival_date_month'], axis=1, inplace=True)
예시 33)
# 이 코드는 hotel_df 데이터프레임에 새로운 열 'expected_room_type'을 추가합니다.
# 'expected_room_type'은 예약된 방 유형과 배정된 방 유형이 동일한지 여부를 나타냅니다.
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)
# hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']:
# - 'reserved_room_type'(예약된 방 유형)과 'assigned_room_type'(배정된 방 유형)이 같은지 비교합니다.
# - 동일하면 True, 다르면 False를 반환합니다.
# .astype(int):
# - True는 1로, False는 0으로 변환합니다.
# - 결과적으로 'expected_room_type' 열에는 1(같음) 또는 0(다름)이 저장됩니다.
# 예:
# 원래 데이터:
# | reserved_room_type | assigned_room_type |
# |--------------------|--------------------|
# | A | A |
# | B | A |
# 결과:
# | reserved_room_type | assigned_room_type | expected_room_type |
# |--------------------|--------------------|---------------------|
# | A | A | 1 |
# | B | A | 0 |
hotel_df.head()
# head():
# - 데이터프레임의 상위 5개 행을 출력합니다.
# - 이를 통해 새로 추가된 'expected_room_type' 열과 기존 데이터의 구조를 확인할 수 있습니다.
# 사용 의도:
# 이 열은 예약된 방과 실제 배정된 방이 일치하는 비율을 분석하거나, 방 배정의 신뢰성을 평가하는 데 유용합니다.
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)
hotel_df.head()
--->
<ipython-input-36-ba417ea73ffe>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead--->

예시 34)
# 이 코드는 hotel_df 데이터프레임에서 'reserved_room_type'과 'assigned_room_type' 열을 삭제합니다.
# drop():
# - 특정 열이나 행을 데이터프레임에서 제거하는 메서드입니다.
# - 첫 번째 인수로 삭제할 열의 이름을 리스트 형태로 전달합니다.
# 여기서는 ['reserved_room_type', 'assigned_room_type'] 열을 삭제 대상으로 지정합니다.
# axis=1:
# - 삭제 대상이 열(columns)임을 나타냅니다.
# - axis=0은 행(rows)을 삭제할 때 사용합니다.
# inplace=True:
# - True로 설정하면 데이터프레임을 원본에서 바로 수정합니다.
# - False(기본값)로 설정하면 수정된 데이터프레임이 반환되며, 원본은 그대로 유지됩니다.
# 결과:
# - hotel_df 데이터프레임에서 'reserved_room_type'과 'assigned_room_type' 열이 삭제됩니다.
# 사용 의도:
# 'expected_room_type' 열을 생성하여 예약된 방과 배정된 방의 일치 여부를 표현했으므로,
# 더 이상 필요하지 않은 'reserved_room_type'과 'assigned_room_type' 열을 삭제하여 데이터프레임을 간소화합니다.
hotel_df.drop(['reserved_room_type', 'assigned_room_type'], axis=1, inplace=True)
--->
<ipython-input-37-006314302c2b>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(['reserved_room_type', 'assigned_room_type'], axis=1, inplace=True)
예제 35)
hotel_df['cancel_rate'] = hotel_df['previous_cancellations'] / (hotel_df['previous_cancellations'] + hotel_df['previous_bookings_not_canceled'])
hotel_df.head()
--->
# 이 코드는 hotel_df 데이터프레임에 새로운 열 'cancel_rate'를 추가합니다.
# 'cancel_rate'는 과거 예약 중 취소된 예약의 비율(취소율)을 계산하여 저장합니다.
hotel_df['cancel_rate'] = hotel_df['previous_cancellations'] / (hotel_df['previous_cancellations'] + hotel_df['previous_bookings_not_canceled'])
# 'previous_cancellations':
# - 과거에 취소된 예약 수를 나타냅니다.
# 'previous_bookings_not_canceled':
# - 과거에 취소되지 않은 예약 수를 나타냅니다.
# (hotel_df['previous_cancellations'] + hotel_df['previous_bookings_not_canceled']):
# - 과거 전체 예약 수를 계산합니다.
# 'previous_cancellations'을 전체 예약 수로 나누어 취소율을 계산합니다.
# 계산된 값이 'cancel_rate' 열에 저장됩니다.
# 'cancel_rate'의 값은 0에서 1 사이의 값으로, 과거 예약 취소의 비율을 나타냅니다.
# 예:
# - previous_cancellations=2, previous_bookings_not_canceled=8이면:
# cancel_rate = 2 / (2 + 8) = 0.2 (취소율 20%)
hotel_df.head()
# head():
# - 데이터프레임의 상위 5개 행을 출력합니다.
# - 새로 추가된 'cancel_rate' 열과 기존 데이터의 구조를 확인할 수 있습니다.
# 사용 의도:
# 이 열은 고객의 과거 예약 행동(취소 습관)을 나타내는 지표로 활용될 수 있습니다.
# 이를 통해 특정 고객의 예약 취소 가능성을 예측하거나 분석하는 데 유용합니다.
---->
<ipython-input-38-66990366192d>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead--->

예제 36)
# 이 코드는 hotel_df 데이터프레임에서 'cancel_rate' 열에 결측값(NaN)이 있는 행만 필터링하여 반환합니다.
# hotel_df['cancel_rate']:
# - 'cancel_rate' 열의 데이터를 가져옵니다.
# .isna():
# - 'cancel_rate' 열에서 값이 NaN(결측값)인지 확인합니다.
# - 값이 NaN인 경우 True를 반환하고, 그렇지 않으면 False를 반환합니다.
# hotel_df[조건식]:
# - 조건식을 만족하는 행들만 데이터프레임 형태로 반환합니다.
# - 여기서는 'cancel_rate' 값이 NaN인 모든 행이 반환됩니다.
# 예:
# 원래 데이터:
# | previous_cancellations | previous_bookings_not_canceled | cancel_rate |
# |------------------------|-------------------------------|-------------|
# | 2 | 3 | 0.4 |
# | 0 | 0 | NaN |
# | 1 | 4 | 0.2 |
# 결과:
# | previous_cancellations | previous_bookings_not_canceled | cancel_rate |
# |------------------------|-------------------------------|-------------|
# | 0 | 0 | NaN |
# 결과 해석:
# - 'cancel_rate'가 NaN인 경우는 과거 예약 데이터가 없는 경우(즉, previous_cancellations와 previous_bookings_not_canceled 모두 0인 경우)일 가능성이 높습니다.
# 사용 의도:
# 결측값(NaN)이 포함된 데이터를 확인하여,
# 이를 처리하거나(예: 특정 값으로 대체) 분석에서 제외하는 등의 데이터 전처리 작업을 수행할 수 있습니다.
hotel_df[hotel_df['cancel_rate'].isna()]--->

예제 37)
# 이 코드는 hotel_df 데이터프레임의 'cancel_rate' 열에서 결측값(NaN)을 -1로 대체합니다.
# .fillna(-1):
# - 'cancel_rate' 열에서 결측값(NaN)을 찾습니다.
# - 각 결측값을 -1로 대체합니다.
# - 결측값을 특정 값으로 채워 넣어 데이터 분석이나 머신러닝 모델링에서 결측값으로 인한 오류를 방지합니다.
# 이유:
# - 'cancel_rate'가 NaN인 경우는 과거 예약 데이터가 없는 경우(예: previous_cancellations와 previous_bookings_not_canceled가 모두 0인 경우)일 가능성이 높습니다.
# - 이런 경우를 -1로 설정하면, 이후 분석에서 이 데이터를 명확하게 구분하거나 처리할 수 있습니다.
# 예:
# 원래 데이터:
# | cancel_rate |
# |-------------|
# | 0.4 |
# | NaN |
# | 0.2 |
# fillna(-1) 적용 후:
# | cancel_rate |
# |-------------|
# | 0.4 |
# | -1 |
# | 0.2 |
# 결과:
# - 'cancel_rate' 열에서 결측값이 모두 -1로 대체됩니다.
hotel_df['cancel_rate'] = hotel_df['cancel_rate'].fillna(-1)
--->
<ipython-input-40-599e806aa6a0>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['cancel_rate'] = hotel_df['cancel_rate'].fillna(-1)
예제 38)
# 이 코드는 hotel_df 데이터프레임에서 'previous_cancellations'와 'previous_bookings_not_canceled' 열을 삭제합니다.
hotel_df.drop(['previous_cancellations', 'previous_bookings_not_canceled'], axis=1, inplace=True)
# drop():
# - 특정 열이나 행을 데이터프레임에서 제거하는 메서드입니다.
# - 첫 번째 인수로 삭제할 열의 이름을 리스트 형태로 전달합니다.
# 여기서는 ['previous_cancellations', 'previous_bookings_not_canceled'] 열을 삭제 대상으로 지정합니다.
# axis=1:
# - 삭제할 대상이 열(columns)임을 나타냅니다.
# - axis=0은 행(rows)을 삭제할 때 사용합니다.
# inplace=True:
# - True로 설정하면 원본 데이터프레임(hotel_df)을 직접 수정합니다.
# - False(기본값)로 설정하면 수정된 데이터프레임이 반환되며, 원본 데이터프레임은 그대로 유지됩니다.
# 결과:
# - hotel_df 데이터프레임에서 'previous_cancellations'와 'previous_bookings_not_canceled' 열이 삭제됩니다.
# 사용 의도:
# 'cancel_rate' 열을 생성하여 과거 예약 취소율 정보를 요약했으므로,
# 더 이상 필요하지 않은 'previous_cancellations'와 'previous_bookings_not_canceled' 열을 제거하여 데이터프레임을 간소화하고 중복 정보를 없앱니다.
#'previous_cancellations', 'previous_bookings_not_canceled 를 지워준다
hotel_df.drop(['previous_cancellations', 'previous_bookings_not_canceled'], axis=1, inplace=True)
예제 39)
hotel_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 116206 entries, 0 to 119389
Data columns (total 27 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 116206 non-null object
1 is_canceled 116206 non-null int64
2 lead_time 116206 non-null int64
3 arrival_date_year 116206 non-null int64
4 arrival_date_week_number 116206 non-null int64
5 arrival_date_day_of_month 116206 non-null int64
6 meal 116206 non-null object
7 country 115728 non-null object
8 market_segment 116206 non-null object
9 distribution_channel 116206 non-null object
10 is_repeated_guest 116206 non-null int64
11 booking_changes 116206 non-null int64
12 deposit_type 116206 non-null object
13 agent 100074 non-null float64
14 company 6768 non-null float64
15 days_in_waiting_list 116206 non-null int64
16 customer_type 116206 non-null object
17 adr 116206 non-null float64
18 required_car_parking_spaces 116206 non-null int64
19 total_of_special_requests 116206 non-null int64
20 reservation_status 116206 non-null object
21 reservation_status_date 116206 non-null object
22 people 116206 non-null float64
23 total_nights 116206 non-null int64
24 season 116206 non-null object
25 expected_room_type 116206 non-null int64
26 cancel_rate 116206 non-null float64
dtypes: float64(5), int64(12), object(10)
memory usage: 24.8+ MB
예제 40)
hotel_df.isna().sum() #0인 값을 출력 0인 값이 있으면 오류가 날 확률이 높다
--->--->

예제 41)
hotel_df['agent'].value_counts(dropna=False).sort_index()
--->
# 이 코드는 hotel_df 데이터프레임의 'agent' 열에서 각 고유 값의 발생 빈도를 계산하고, 이를 인덱스(값) 기준으로 정렬합니다.
# hotel_df['agent']:
# - 데이터프레임의 'agent' 열을 선택합니다.
# - 'agent'는 예약을 처리한 에이전트(또는 채널)를 나타냅니다.
# .value_counts(dropna=False):
# - 'agent' 열에서 각 고유 값의 발생 빈도를 계산합니다.
# - dropna=False:
# - 결측값(NaN)도 포함하여 발생 빈도를 계산합니다.
# - 결측값이 포함된 데이터를 분석하거나 처리할 때 유용합니다.
# - 결과는 각 고유 값과 그 빈도로 구성된 Series를 반환합니다.
# .sort_index():
# - 결과 Series를 인덱스(고유 값 기준) 순서대로 정렬합니다.
# - 기본적으로 value_counts()는 빈도 순서로 정렬되지만, 여기서는 고유 값(인덱스) 순으로 정렬됩니다.
# 예:
# 'agent' 열의 데이터가 다음과 같다면:
# [1, 2, NaN, 2, 1, 1, 3, NaN]
# value_counts(dropna=False)는 다음을 반환합니다:
# 1.0 3
# 2.0 2
# NaN 2
# 3.0 1
# sort_index()를 적용하면 결과는 다음과 같이 정렬됩니다:
# 1.0 3
# 2.0 2
# 3.0 1
# NaN 2
# 사용 의도:
# - 'agent' 열의 고유 값 분포를 확인하거나, 특정 에이전트의 데이터 양을 분석하는 데 유용합니다.
# - 결측값(NaN)의 개수와 다른 에이전트 값들의 정렬된 빈도를 쉽게 파악할 수 있습니다.
예제 42)
# 이 코드는 hotel_df 데이터프레임의 'agent' 열에서 결측값(NaN)을 -1로 대체합니다.
# .fillna(-1):
# - 'agent' 열에서 NaN(결측값)을 찾아 -1로 대체합니다.
# - 이는 NaN 값을 명시적으로 처리하여 분석이나 모델링 시 결측값으로 인한 오류를 방지합니다.
# 사용 이유:
# - NaN 값을 -1로 설정하여 결측값을 다른 값들과 구분할 수 있도록 명확히 합니다.
# - 'agent' 열에서 NaN은 특정 예약의 에이전트 정보가 없음을 나타내므로, 이를 -1로 치환하여 명시적으로 표현합니다.
# 예:
# 원래 데이터:
# | agent |
# |--------|
# | 1 |
# | NaN |
# | 2 |
# | NaN |
# 결과 데이터:
# | agent |
# |--------|
# | 1 |
# | -1 |
# | 2 |
# | -1 |
hotel_df['agent'] = hotel_df['agent'].fillna(-1)
--->
<ipython-input-45-d9838ad3419d>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['agent'] = hotel_df['agent'].fillna(-1)
예제 43)
# 이 코드는 hotel_df 데이터프레임의 'company' 열에서 각 고유 값의 발생 빈도를 계산하고, 이를 인덱스(값) 기준으로 정렬합니다.
# hotel_df['company']:
# - 데이터프레임의 'company' 열을 선택합니다.
# - 'company'는 예약과 관련된 회사 정보를 나타냅니다.
# .value_counts(dropna=False):
# - 'company' 열에서 각 고유 값(회사 ID)의 발생 빈도를 계산합니다.
# - dropna=False:
# - 결측값(NaN)도 포함하여 발생 빈도를 계산합니다.
# - 결측값의 개수를 확인할 수 있습니다.
# - 결과는 각 고유 값과 그 빈도로 구성된 Series를 반환합니다.
# .sort_index():
# - 반환된 Series를 인덱스(고유 값 기준) 순서로 정렬합니다.
# - 기본적으로 value_counts()는 빈도순으로 정렬되지만, 여기서는 고유 값(회사 ID) 순으로 정렬됩니다.
# 예:
# 'company' 열의 데이터가 다음과 같다면:
# [1, 2, NaN, 2, 1, NaN, 3, NaN]
# value_counts(dropna=False)는 다음을 반환합니다:
# NaN 3
# 1.0 2
# 2.0 2
# 3.0 1
# sort_index()를 적용하면 결과는 다음과 같이 정렬됩니다:
# 1.0 2
# 2.0 2
# 3.0 1
# NaN 3
# 사용 의도:
# - 'company' 열에서 회사별 예약 수를 분석하거나, 결측값(NaN)의 개수를 확인할 수 있습니다.
# - 인덱스(회사 ID) 순으로 정렬하여, 특정 회사의 데이터를 더 쉽게 찾을 수 있습니다.
hotel_df['company'].value_counts(dropna=False).sort_index()--->

예제 44)
# 이 코드는 hotel_df 데이터프레임의 'company' 열에서 결측값(NaN)을 -1로 대체합니다.
# .fillna(-1):
# - 'company' 열에서 NaN(결측값)을 찾아 -1로 대체합니다.
# - 이는 결측값을 명시적으로 처리하여 분석이나 모델링 시 결측값으로 인한 오류를 방지합니다.
# 사용 이유:
# - NaN 값을 -1로 설정하여 결측값을 다른 값들과 구분할 수 있도록 명확히 표시합니다.
# - 'company' 열에서 NaN은 특정 예약과 관련된 회사 정보가 없음을 나타내므로, 이를 -1로 대체하여 명시적으로 표현합니다.
# 예:
# 원래 데이터:
# | company |
# |---------|
# | 1 |
# | NaN |
# | 2 |
# | NaN |
# 결과 데이터:
# | company |
# |---------|
# | 1 |
# | -1 |
# | 2 |
# | -1 |
hotel_df['company'] = hotel_df['company'].fillna(-1)
--->
<ipython-input-49-f6b26db59211>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df['company'] = hotel_df['company'].fillna(-1)
예제 45)
# 이 코드는 hotel_df 데이터프레임에서 숫자형(number) 데이터 타입이 아닌 열(column)의 이름을 리스트 형태로 반환합니다.
# select_dtypes(exclude=['number']):
# - 데이터프레임의 열 중에서 특정 데이터 타입을 제외하고 선택합니다.
# - exclude=['number']:
# - 숫자형 데이터 타입(int, float 등)을 제외합니다.
# - 즉, 문자열(object), 범주형(category), 날짜(datetime) 등 숫자형이 아닌 열만 선택합니다.
# .columns:
# - 선택된 열의 이름을 반환합니다.
# .tolist():
# - 열 이름을 리스트 형태로 변환합니다.
# 결과:
# - hotel_df에서 숫자형이 아닌 데이터 타입을 가진 열 이름의 리스트를 반환합니다.
# 예:
# 데이터프레임에 다음과 같은 열이 있다고 가정:
# | col1 | col2 | col3 |
# |-------|--------|--------|
# | int | float | object |
# select_dtypes(exclude=['number'])는 'col3'만 선택합니다.
# 결과 리스트는 ['col3']가 됩니다.
# 사용 의도:
# - 데이터프레임에서 숫자형이 아닌 열을 식별하거나, 해당 열을 대상으로 분석 또는 전처리 작업을 수행할 때 유용합니다.
hotel_df.select_dtypes(exclude=['number']).columns.tolist()
--->
['hotel',
'meal',
'country',
'market_segment',
'distribution_channel',
'deposit_type',
'customer_type',
'reservation_status',
'reservation_status_date',
'season']
예제 46)
for i in hotel_df.select_dtypes(exclude=['number']).columns.tolist():
print(i, hotel_df[i].nunique())
# 이 코드는 hotel_df 데이터프레임에서 숫자형이 아닌 열에 대해, 각 열의 고유 값 개수를 출력합니다.
for i in hotel_df.select_dtypes(exclude=['number']).columns.tolist():
# hotel_df.select_dtypes(exclude=['number']):
# - 숫자형(number) 데이터 타입이 아닌 열만 선택합니다.
# .columns.tolist():
# - 선택된 열의 이름을 리스트 형태로 변환합니다.
# for i in ...:
# - 리스트에 있는 각 열 이름(i)에 대해 반복 작업을 수행합니다.
print(i, hotel_df[i].nunique())
# hotel_df[i]:
# - 현재 반복 중인 열(i)의 데이터를 가져옵니다.
# .nunique():
# - 해당 열에서 고유 값(unique value)의 개수를 계산합니다.
# print(i, ...):
# - 열 이름(i)과 고유 값의 개수를 출력합니다.
# 예:
# 데이터프레임이 다음과 같다면:
# | col1 | col2 | col3 |
# |--------|-------|-------|
# | A | X | dog |
# | B | Y | cat |
# | A | X | dog |
# - 숫자형이 아닌 열은 'col1', 'col2', 'col3'입니다.
# - col1의 고유 값 개수: 2 (A, B)
# - col2의 고유 값 개수: 2 (X, Y)
# - col3의 고유 값 개수: 2 (dog, cat)
# 결과 출력:
# col1 2
# col2 2
# col3 2
# 사용 의도:
# - 숫자형이 아닌 열에서 고유 값의 개수를 파악하여, 데이터의 다양성을 분석하거나,
# 범주형 데이터를 처리할 때 필요한 정보를 얻는 데 유용합니다.
--->
hotel 2
meal 5
country 177
market_segment 8
distribution_channel 5
deposit_type 3
customer_type 4
reservation_status 3
reservation_status_date 926
season 4
예제 47)
# 이 코드는 hotel_df 데이터프레임에서 'meal', 'country', 'reservation_status_date' 열을 삭제합니다.
# drop():
# - 데이터프레임에서 특정 열 또는 행을 제거하는 메서드입니다.
# - 첫 번째 인수로 삭제할 열의 이름을 리스트 형태로 전달합니다.
# 여기서는 ['meal', 'country', 'reservation_status_date'] 열을 삭제 대상으로 지정합니다.
# axis=1:
# - 삭제 대상이 열(columns)임을 나타냅니다.
# - axis=0은 행(rows)을 삭제할 때 사용됩니다.
# inplace=True:
# - True로 설정하면 원본 데이터프레임(hotel_df)을 직접 수정합니다.
# - False(기본값)로 설정하면 수정된 데이터프레임이 반환되며, 원본은 그대로 유지됩니다.
# 결과:
# - 'meal', 'country', 'reservation_status_date' 열이 데이터프레임에서 삭제됩니다.
# 사용 의도:
# - 분석에서 필요하지 않은 열을 제거하여 데이터프레임을 간소화하거나, 메모리 사용량을 줄이는 데 사용됩니다.
# - 예를 들어, 'meal'이나 'country' 열이 분석과 관련이 없거나,
# 'reservation_status_date'가 특정 정보와 중복되거나 불필요할 경우 이를 제거합니다.
hotel_df.drop(['meal', 'country', 'reservation_status_date'], axis=1, inplace=True)
--->
<ipython-input-52-0f634fb7c9b5>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
hotel_df.drop(['meal', 'country', 'reservation_status_date'], axis=1, inplace=True)
예제 48)
# 이 코드는 hotel_df 데이터프레임에서 숫자형이 아닌 열을 더미 변수(dummy variables)로 변환합니다.
hotel_df = pd.get_dummies(hotel_df, hotel_df.select_dtypes(exclude=['number']).columns.tolist(), drop_first=True)
# pd.get_dummies():
# - 범주형 데이터(숫자형이 아닌 데이터)를 0과 1로 구성된 더미 변수로 변환합니다.
# - 각 고유 값(category)에 대해 새로운 열을 생성하고, 데이터가 해당 카테고리에 속하면 1, 아니면 0을 기록합니다.
# 첫 번째 인수(hotel_df):
# - 원본 데이터프레임을 지정합니다.
# 두 번째 인수:
# - hotel_df.select_dtypes(exclude=['number']).columns.tolist():
# - 숫자형이 아닌 열 이름을 리스트로 추출하여 변환 대상 열로 지정합니다.
# - 범주형 데이터를 변환하기 위해 사용됩니다.
# drop_first=True:
# - 각 범주형 열에서 첫 번째 카테고리를 제거합니다.
# - 이 옵션은 다중공선성을 방지하고 데이터 크기를 줄이는 데 유용합니다.
# - 예를 들어, 'A', 'B', 'C' 세 가지 값이 있는 열은 'B'와 'C'만 더미 변수로 생성되고,
# 'A'는 기본 값으로 간주합니다.
# 결과:
# - 원본 데이터프레임은 숫자형 데이터는 그대로 유지되고,
# 범주형 데이터는 더미 변수로 변환됩니다.
# 예:
# 원래 데이터:
# | col1 | col2 |
# |-------|-------|
# | A | X |
# | B | Y |
# | A | Z |
# 변환된 데이터(drop_first=True):
# | col1_B | col2_Y | col2_Z |
# |---------|---------|--------|
# | 0 | 0 | 0 |
# | 1 | 1 | 0 |
# | 0 | 0 | 1 |
hotel_df.head()
# head():
# - 변환된 데이터프레임의 상위 5개 행을 출력하여, 변환 결과를 확인합니다.
hotel_df = pd.get_dummies(hotel_df, hotel_df.select_dtypes(exclude=['number']).columns.tolist(), drop_first=True)
hotel_df.head()--->

예제 49)
hotel_df.info()
--->
<class 'pandas.core.frame.DataFrame'>
Index: 116206 entries, 0 to 119389
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 is_canceled 116206 non-null int64
1 lead_time 116206 non-null int64
2 arrival_date_year 116206 non-null int64
3 arrival_date_week_number 116206 non-null int64
4 arrival_date_day_of_month 116206 non-null int64
5 is_repeated_guest 116206 non-null int64
6 booking_changes 116206 non-null int64
7 agent 116206 non-null float64
8 company 116206 non-null float64
9 days_in_waiting_list 116206 non-null int64
10 adr 116206 non-null float64
11 required_car_parking_spaces 116206 non-null int64
12 total_of_special_requests 116206 non-null int64
13 people 116206 non-null float64
14 total_nights 116206 non-null int64
15 expected_room_type 116206 non-null int64
16 cancel_rate 116206 non-null float64
17 hotel_Resort Hotel 116206 non-null bool
18 market_segment_Complementary 116206 non-null bool
19 market_segment_Corporate 116206 non-null bool
20 market_segment_Direct 116206 non-null bool
21 market_segment_Groups 116206 non-null bool
22 market_segment_Offline TA/TO 116206 non-null bool
23 market_segment_Online TA 116206 non-null bool
24 market_segment_Undefined 116206 non-null bool
25 distribution_channel_Direct 116206 non-null bool
26 distribution_channel_GDS 116206 non-null bool
27 distribution_channel_TA/TO 116206 non-null bool
28 distribution_channel_Undefined 116206 non-null bool
29 deposit_type_Non Refund 116206 non-null bool
30 deposit_type_Refundable 116206 non-null bool
31 customer_type_Group 116206 non-null bool
32 customer_type_Transient 116206 non-null bool
33 customer_type_Transient-Party 116206 non-null bool
34 reservation_status_Check-Out 116206 non-null bool
35 reservation_status_No-Show 116206 non-null bool
36 season_spring 116206 non-null bool
37 season_summer 116206 non-null bool
38 season_winter 116206 non-null bool
dtypes: bool(22), float64(5), int64(12)
memory usage: 18.4 MB
예제 50)
# 이 코드는 scikit-learn의 train_test_split 함수를 사용하여 데이터를 학습용 데이터와 테스트용 데이터로 분리합니다.
from sklearn.model_selection import train_test_split
# train_test_split:
# - 데이터를 학습용 데이터(train)과 테스트용 데이터(test)로 나누는 함수입니다.
# - 모델을 학습하고 평가하기 위해 데이터를 분리할 때 사용됩니다.
X_train, X_test, y_train, y_test = train_test_split(
hotel_df.drop('is_canceled', axis=1), # X(특징 데이터): 'is_canceled' 열을 제외한 데이터
hotel_df['is_canceled'], # y(타겟 데이터): 'is_canceled' 열
test_size=0.3, # 테스트 데이터의 비율: 전체 데이터의 30%를 테스트용으로 사용
random_state=2025 # 랜덤 시드: 데이터 분리를 재현 가능하게 만듭니다
)
# 인수 설명:
# - hotel_df.drop('is_canceled', axis=1):
# - 'is_canceled' 열을 제거하여 특징 데이터(X)를 만듭니다.
# - 이 데이터는 모델 학습에 사용됩니다.
# - hotel_df['is_canceled']:
# - 타겟 데이터(y)로 사용됩니다.
# - 이 열은 예약 취소 여부(0: 취소되지 않음, 1: 취소됨)를 나타냅니다.
# - test_size=0.3:
# - 데이터의 30%는 테스트 데이터로 사용되고, 나머지 70%는 학습 데이터로 사용됩니다.
# - random_state=2025:
# - 데이터 분할을 랜덤하게 수행하되, 동일한 결과를 재현할 수 있도록 고정된 시드를 설정합니다.
# 반환값:
# - X_train: 학습용 특징 데이터
# - X_test: 테스트용 특징 데이터
# - y_train: 학습용 타겟 데이터
# - y_test: 테스트용 타겟 데이터
# 사용 의도:
# - 학습 데이터(X_train, y_train)를 사용하여 모델을 학습시키고,
# 테스트 데이터(X_test, y_test)를 사용하여 모델의 성능을 평가합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis=1),
hotel_df['is_canceled'],
test_size=0.3, random_state=2025)
예제 51)
X_train.shape, X_test.shape
--->
((81344, 38), (34862, 38))
y_train.shape, y_test.shape
-->
((81344,), (34862,))
3. LogisticRegression
* 사이킷런의 LogisticRegression은 이진 분류(Binary Classification)와 다중 분류(Multiclass Classification) 문제를 해결하기 위한 머신러닝 알고리즘입니다. * 로지스틱 회귀는 선형 모델로, 입력 데이터에 대한 선형 결합을 통해 확률을 예측하고, 이 확률을 로지스틱 함수(시그모이드 함수)를 사용해 이진 또는 다중 클래스에 대한 예측을 수행합니다.
* 사이킷런의 LogisticRegression은 과적합을 방지하기 위한 규제(Regularization) 기법(penalty)을 지원합니다.
* 또한, 반복 최적화의 최대 횟수를 max_iter로 설정할 수 있으며, 모델의 성능 평가는 정확도, ROC-AUC 등 다양한 지표를 통해 수행할 수 있습니다.
* 이 모델은 특히 해석 가능성이 높고, 계산이 효율적이며, 선형적으로 구분 가능한 데이터셋에서 뛰어난 성능을 발휘합니다.
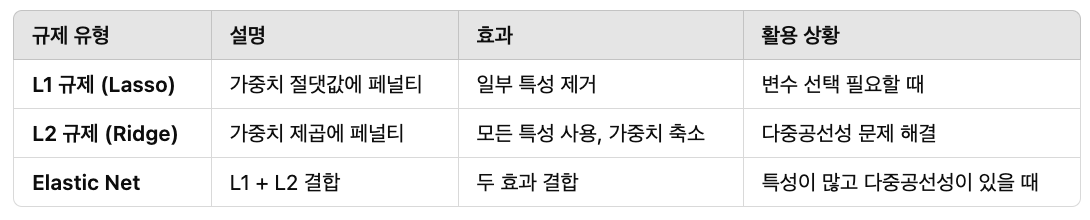
### 규제
* 규제(Regularization)는 머신러닝 모델이 과적합(Overfitting) 되는 것을 방지하기 위해 사용되는 기법입니다.
* 과적합은 모델이 학습 데이터에 지나치게 맞춰져서, 새로운 데이터(테스트 데이터)에는 제대로 일반화하지 못하는 현상입니다.
* 규제는 모델의 복잡도를 줄이고, 불필요한 가중치(Weights)를 작게 만들어 과적합을 방지합니다.
예제 1)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
--->
/usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_logistic.py:465: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(--->

* 반복 횟수가 부족하면 ConvergenceWarning 경고가 나타날 수 있습니다.
* 이는 알고리즘이 최적해를 찾지 못했다는 의미입니다.
* max_iter=1000: 최대 1000번 반복하여 최적의 가중치를 찾습니다.
* 기본값: max_iter=100
4. 데이터 스케일링
* 데이터 스케일링은 서로 다른 범위와 단위를 가진 데이터를 일정한 범위로 변환하여 모델 학습을 더 효율적으로 수행할 수 있도록 만드는 전처리 과정입니다.
* 주로 변수 간의 값의 크기 차이가 클 때 발생하는 불균형을 해결하기 위해 사용되며, 대표적인 방법으로 표준화(Standardization)와 정규화(Normalization)가 있습니다.
* 스케일링을 통해 학습 속도를 높이고, 기울기 소실(Gradient Vanishing) 문제를 완화하며, 특정 변수에 모델이 과도하게 의존하는 것을 방지할 수 있습니다.
### 4-1. 표준화
* 표준화(Standardization)는 데이터의 평균을 0으로, 표준편차를 1로 변환하여 모든 변수가 동일한 척도를 갖도록 만드는 데이터 전처리 기법입니다.
* 주로 데이터의 분포가 정규 분포를 따를 때 효과적이며, 값의 크기나 단위가 서로 다른 변수를 비교하거나 머신러닝 알고리즘(예: 로지스틱 회귀, SVM)에서 최적의 성능을 내기 위해 사용됩니다.

### 4-2. 정규화
* 정규화(Normalization)는 데이터의 값을 특정 범위(주로 0과 1 사이)로 변환하여 변수 간의 스케일 차이를 줄이는 데이터 전처리 기법입니다.
* 이는 주로 최소값과 최대값을 사용해 데이터를 조정하며, 대표적인 방법으로 Min-Max Scaling이 있습니다.

예제 1)
# 이 코드는 confusion_matrix 함수를 사용하여 예측값(pred)과 실제값(y_test)을 비교한 혼동 행렬(confusion matrix)을 생성합니다.
from sklearn.preprocessing import StandardScaler
# StandardScaler:
# - 데이터의 평균을 0, 표준 편차를 1로 조정하여 표준화(스케일링)합니다.
# - 모델 학습 시 각 특징의 스케일이 다른 경우 성능에 영향을 줄 수 있으므로,
# 데이터를 스케일링하여 균일하게 만듭니다.
# (참고: 이 코드에서는 StandardScaler를 임포트만 했고 사용되지 않았습니다.)
confusion_matrix(y_test, pred)
# confusion_matrix():
# - 예측값(pred)과 실제값(y_test)을 비교하여 분류 모델의 성능을 평가합니다.
# - 입력:
# - y_test: 실제 타겟값(테스트 데이터의 정답)
# - pred: 모델이 예측한 타겟값
# - 반환:
# - 혼동 행렬(confusion matrix), 2x2 행렬(이진 분류 기준)
# 혼동 행렬 구성:
# - 행: 실제값
# - 열: 예측값
# - 각 원소의 의미:
# - [0, 0]: 실제 0인 데이터를 0으로 예측한 개수 (True Negative, TN)
# - [0, 1]: 실제 0인 데이터를 1로 예측한 개수 (False Positive, FP)
# - [1, 0]: 실제 1인 데이터를 0으로 예측한 개수 (False Negative, FN)
# - [1, 1]: 실제 1인 데이터를 1로 예측한 개수 (True Positive, TP)
# 예:
# y_test: [0, 1, 1, 0, 1]
# pred: [0, 1, 0, 0, 1]
# confusion_matrix(y_test, pred):
# [[2, 0], # 실제 0인 데이터 2개를 0으로 예측 (TN), 0개를 1로 예측 (FP)
# [1, 2]] # 실제 1인 데이터 1개를 0으로 예측 (FN), 2개를 1로 예측 (TP)
# 사용 의도:
# - 모델이 얼마나 잘 예측했는지(정확성, 민감도, 정밀도 등)를 분석하는 데 사용됩니다.
# - 혼동 행렬을 기반으로 추가 성능 지표(예: F1-score, ROC-AUC)를 계산할 수 있습니다.
from sklearn.preprocessing import StandardScaler
confusion_matrix(y_test, pred)
--->
array([[21459, 758],
[ 1704, 10941]])
예제 2)
# 이 코드는 scikit-learn의 precision_score, recall_score, f1_score를 사용하여 모델의 성능을 평가합니다.
# 각각 정밀도(Precision), 재현율(Recall), F1 점수를 계산합니다.
from sklearn.metrics import precision_score, recall_score, f1_score
# precision_score, recall_score, f1_score:
# - 분류 모델의 성능 지표를 계산하는 함수입니다.
# - 예측값(pred)과 실제값(y_test)을 기반으로 각각의 지표를 계산합니다.
print(precision_score(y_test, pred))
# precision_score(y_test, pred):
# - 정밀도(Precision)를 계산합니다.
# - 정밀도는 모델이 예측한 Positive 값 중에서 실제로 Positive인 비율을 나타냅니다.
# - 공식: Precision = TP / (TP + FP)
# - TP(True Positive): 실제 Positive를 Positive로 예측한 수
# - FP(False Positive): 실제 Negative를 Positive로 잘못 예측한 수
# - 정밀도는 False Positive를 최소화하는 데 초점이 있습니다.
# - 값이 1에 가까울수록 정확히 Positive만 예측했다는 의미입니다.
print(recall_score(y_test, pred))
# recall_score(y_test, pred):
# - 재현율(Recall, 민감도)를 계산합니다.
# - 재현율은 실제 Positive 값 중에서 모델이 Positive로 정확히 예측한 비율을 나타냅니다.
# - 공식: Recall = TP / (TP + FN)
# - FN(False Negative): 실제 Positive를 Negative로 잘못 예측한 수
# - 재현율은 False Negative를 최소화하는 데 초점이 있습니다.
# - 값이 1에 가까울수록 모든 실제 Positive를 예측했다는 의미입니다.
print(f1_score(y_test, pred))
# f1_score(y_test, pred):
# - F1 점수를 계산합니다.
# - F1 점수는 정밀도와 재현율의 조화 평균(Harmonic Mean)으로, 두 지표 간의 균형을 평가합니다.
# - 공식: F1 = 2 * (Precision * Recall) / (Precision + Recall)
# - F1 점수는 정밀도와 재현율 사이에 trade-off가 있는 경우, 이를 종합적으로 평가하는 데 유용합니다.
# - 값이 1에 가까울수록 모델이 정밀도와 재현율 모두에서 우수한 성능을 보인다는 의미입니다.
# 예:
# y_test: [0, 1, 1, 0, 1]
# pred: [0, 1, 0, 0, 1]
# Precision: 2 / (2 + 0) = 1.0 (Positive 예측이 모두 정확)
# Recall: 2 / (2 + 1) = 0.6667 (실제 Positive 중 66.67%를 예측)
# F1: 2 * (1.0 * 0.6667) / (1.0 + 0.6667) = 0.8
---------------------------
from sklearn.metrics import precision_score, recall_score, f1_score
print(precision_score(y_test, pred))
print(recall_score(y_test, pred))
print(f1_score(y_test, pred))
--->
0.9352081374476451
0.8652431791221826
0.8988662504107788
예제 3)
lr.coef_ #기울기
--->
array([[ 9.18793261e-03, 1.44217354e-03, 2.18389627e-02,
5.96175587e-03, -6.62703157e-02, -9.83973926e-01,
2.98148521e-03, 1.68179915e-03, -9.12455121e-02,
1.19331642e-02, -4.56796792e-01, -1.95102426e+00,
-9.09444902e-02, -8.20492580e-01, 7.18528470e-01,
9.75744529e-01, -3.77896439e-01, -1.02874693e-02,
7.56234430e-03, -4.11976995e-01, 5.54643600e-01,
-2.44669414e-01, 1.02468932e-01, 2.37448194e-04,
-4.20637895e-01, -3.31488868e-03, 3.97971115e-01,
3.60541548e-04, 1.31276456e+00, -3.49220810e-03,
-2.08090538e-02, 7.24630585e-01, -6.14192129e-01,
-4.98244456e+00, 1.67590552e-01, 4.55759769e-02,
-2.32558856e-01, 1.48591543e-01]])
예제 4)
9.18793261e-03
-->
0.00918793261
예제 5)
hotel_df #39개의 기울기
------>

예제 6)
# 이 코드는 선형 모델에서 계산된 절편(intercept)을 반환합니다.
lr.intercept_
# lr:
# - 선형 회귀(Linear Regression) 또는 로지스틱 회귀(Logistic Regression)와 같은 선형 모델 객체입니다.
# - 모델이 학습된 후, 이 속성에서 절편 값을 확인할 수 있습니다.
# .intercept_:
# - 선형 모델의 절편(intercept)을 나타냅니다.
# - 절편은 회귀 직선 또는 평면이 y축과 만나는 점의 값으로,
# 모델이 입력(feature) 값이 모두 0일 때의 예측 값입니다.
# 예:
# - 회귀식이 y = mx + c 형태로 나타날 때, c가 절편(intercept)입니다.
# - 다중 회귀 모델에서는 y = m1x1 + m2x2 + ... + c에서 c가 절편입니다.
# 결과:
# - lr.intercept_는 float(1차원 회귀) 또는 배열 형태(다중 분류 모델)로 반환됩니다.
# - 예를 들어:
# - 단순 회귀: lr.intercept_ = 2.5
# - 다중 클래스 분류: lr.intercept_ = [2.5, -1.2, 0.7] (클래스별 절편)
# 사용 의도:
# - 모델의 절편 값을 확인하여 회귀식 또는 분류 경계의 수식을 이해하거나, 모델의 작동 방식을 분석할 때 유용합니다.
lr.intercept_ #절편
예제 7)
# 이 코드는 로지스틱 회귀 모델에서 테스트 데이터(X_test)에 대해 각 클래스에 속할 확률을 예측합니다.
proba = lr.predict_proba(X_test)
# lr.predict_proba():
# - 로지스틱 회귀 모델(lr)을 사용하여 입력 데이터(X_test)에 대해 각 클래스에 속할 확률을 계산합니다.
# - 반환 값은 2차원 배열로, 각 행이 샘플 하나에 대한 클래스별 확률을 나타냅니다.
# X_test:
# - 테스트 데이터로, 학습된 모델에 입력하여 각 클래스에 속할 확률을 예측합니다.
# 반환 값(proba):
# - 2차원 배열(NumPy array) 형태입니다.
# - 각 행(row)은 하나의 샘플, 각 열(column)은 해당 클래스에 대한 확률을 나타냅니다.
# - 예를 들어, 이진 분류 문제의 경우:
# - 첫 번째 열: 클래스 0에 속할 확률
# - 두 번째 열: 클래스 1에 속할 확률
# - 다중 클래스 분류의 경우 열이 클래스의 개수만큼 늘어납니다.
# 예:
# X_test = [[feature1, feature2], [feature3, feature4]]
# proba = lr.predict_proba(X_test)
# 결과:
# [[0.7, 0.3], # 첫 번째 샘플이 클래스 0일 확률 70%, 클래스 1일 확률 30%
# [0.2, 0.8]] # 두 번째 샘플이 클래스 0일 확률 20%, 클래스 1일 확률 80%
# 사용 의도:
# - 분류 결과에 대한 신뢰도를 확인하기 위해 확률 정보를 제공합니다.
# - 특정 임계값을 설정하여 클래스 예측을 조정하거나, 확률 기반의 후속 분석에 활용할 수 있습니다.
--->
array([[0.03802158, 0.96197842],
[0.63404974, 0.36595026],
[0.97801328, 0.02198672],
...,
[0.94531688, 0.05468312],
[0.11721987, 0.88278013],
[0.9862966 , 0.0137034 ]])
예제 8)
# 이 코드는 로지스틱 회귀 모델에서 테스트 데이터(X_test)에 대해,
# 클래스 1(Positive 클래스)에 속할 확률만을 추출합니다.
proba = lr.predict_proba(X_test)[:, 1]
# lr.predict_proba(X_test):
# - 로지스틱 회귀 모델(lr)을 사용하여 테스트 데이터(X_test)에 대해 각 클래스에 속할 확률을 계산합니다.
# - 반환 값은 2차원 배열로, 각 행이 샘플 하나에 대한 클래스별 확률을 나타냅니다.
# - 예: [[P(class=0), P(class=1)], [P(class=0), P(class=1)], ...]
# [:, 1]:
# - 2차원 배열에서 두 번째 열(인덱스 1)을 선택합니다.
# - 각 샘플에 대해 클래스 1(Positive 클래스)에 속할 확률만 추출합니다.
# 반환 값(proba):
# - 1차원 배열 형태로, 각 샘플이 클래스 1일 확률이 저장됩니다.
# 예:
# X_test = [[feature1, feature2], [feature3, feature4]]
# lr.predict_proba(X_test) = [[0.7, 0.3], [0.2, 0.8]]
# proba = lr.predict_proba(X_test)[:, 1]
# 결과:
# proba = [0.3, 0.8]
# - 첫 번째 샘플이 클래스 1일 확률: 30%
# - 두 번째 샘플이 클래스 1일 확률: 80%
# 사용 의도:
# - 이진 분류 문제에서 클래스 1(Positive 클래스)에 속할 확률만을 필요로 하는 경우 유용합니다.
# - 예를 들어, ROC 곡선, PR 곡선, 또는 사용자 정의 임계값을 설정할 때 활용됩니다.
proba = lr.predict_proba(X_test)[:, 1]
proba
-->
array([0.96197842, 0.36595026, 0.02198672, ..., 0.05468312, 0.88278013,
0.0137034 ])
예제 9)
# 이 코드는 예측 확률(proba)을 사용하여 특정 임계값(threshold)에 따라 최종 예측값(pred)을 생성합니다.
threshold = 0.5
# 임계값(threshold)을 0.5로 설정합니다.
# - 클래스 1(Positive)로 예측하기 위한 기준값입니다.
# - 확률(proba)이 0.5 이상이면 클래스 1로 예측하고, 그렇지 않으면 클래스 0으로 예측합니다.
pred = (proba >= threshold).astype(int)
# proba >= threshold:
# - 확률(proba)이 임계값(threshold) 이상인 경우 True, 미만인 경우 False를 반환합니다.
# - 예: proba = [0.3, 0.8, 0.5]
# - 0.3 >= 0.5: False
# - 0.8 >= 0.5: True
# - 0.5 >= 0.5: True
# 결과: [False, True, True]
# .astype(int):
# - Boolean 값을 정수형으로 변환합니다.
# - True는 1, False는 0으로 변환됩니다.
# - 위 예의 결과: [0, 1, 1]
# pred:
# - 최종적으로 생성된 이진 분류 예측값입니다.
# - 값은 0(클래스 0, Negative) 또는 1(클래스 1, Positive)로 이루어진 1차원 배열입니다.
# 사용 의도:
# - 모델이 예측한 확률(proba)을 기반으로 사용자 정의 임계값을 설정하여, 최종 클래스 예측(pred)을 생성합니다.
# - 임계값을 조정하여 모델의 정밀도(Precision) 또는 재현율(Recall) 우선 순위를 변경할 수 있습니다.
--->
array([1, 0, 0, ..., 0, 1, 0])
6. 분류 문제에서의 랜덤 포레스트
* 랜덤 포레스트는 결정 트리(Decision Trees)를 여러 개 만들어서 결합(앙상블)하여 예측 성능을 향상시키는 앙상블 학습(Ensemble Learning) 기법입니다.
* 분류 문제에서 랜덤 포레스트는 각 트리의 예측값을 모아서 다수결(Majority Voting)을 통해 최종 클래스를 결정합니다.
6-2. 분류 문제에서의 랜덤 포레스트
* 각 트리의 노드 분할(Split) 단계에서, 전체 특성이 아닌 무작위로 선택된 일부 특성만을 사용합니다.
* 이를 통해 트리 간의 상관관계를 줄이고, 과적합을 방지합니다.
* 각 트리에 들어가는 데이터의 개수는 원본 데이터셋 크기와 동일합니다.
* 그러나 중복을 허용하여 샘플링하므로, 일부 데이터는 여러 번 샘플링되고, 일부 데이터는 선택되지 않을 수 있습니다.
* 부트스트래핑된 데이터와 랜덤하게 선택된 특성을 사용하여 결정 트리를 학습합니다.
* 사이킷런(Sklearn)에서 랜덤 포레스트의 기본 트리 개수는 100개입니다.
* 다수결(Majority Voting): 분류 문제에서 가장 많이 예측된 클래스를 선택합니다.
예시 1)
# 이 코드는 RandomForestClassifier를 사용하여 데이터를 학습시키고 테스트 데이터에 대해 예측을 수행합니다.
X_train, X_test, y_train, y_test = train_test_split(
hotel_df.drop('is_canceled', axis=1), # X: 'is_canceled' 열을 제외한 데이터 (특징 데이터)
hotel_df['is_canceled'], # y: 'is_canceled' 열 (타겟 데이터)
test_size=0.3, # 테스트 데이터 비율: 전체 데이터의 30%
random_state=2025 # 랜덤 시드: 재현 가능한 데이터 분리를 위해 설정
)
from sklearn.ensemble import RandomForestClassifier
# RandomForestClassifier:
# - 랜덤 포레스트(Random Forest) 알고리즘을 사용한 분류 모델입니다.
# - 여러 개의 결정 트리(Decision Trees)를 학습하여 평균을 내거나 투표를 통해 예측을 수행합니다.
# - 과적합(overfitting)을 방지하고 높은 예측 성능을 제공합니다.
rf = RandomForestClassifier(random_state=2025)
# rf:
# - RandomForestClassifier 객체를 생성합니다.
# - random_state=2025:
# - 랜덤 시드를 고정하여 동일한 결과를 재현할 수 있도록 설정합니다.
rf.fit(X_train, y_train)
# fit():
# - 학습 데이터를 사용하여 랜덤 포레스트 모델(rf)을 학습시킵니다.
# - X_train: 학습용 특징 데이터
# - y_train: 학습용 타겟 데이터
pred = rf.predict(X_test)
# predict():
# - 학습된 랜덤 포레스트 모델(rf)을 사용하여 테스트 데이터(X_test)에 대한 예측을 수행합니다.
# - 반환 값(pred):
# - 테스트 데이터에 대한 예측 결과로, 0(취소되지 않음) 또는 1(취소됨)로 구성된 1차원 배열입니다.
# 예:
# y_test: [0, 1, 1, 0, 1] (실제값)
# pred: [0, 1, 0, 0, 1] (예측값)
# 사용 의도:
# - 랜덤 포레스트를 사용해 모델을 학습시키고 테스트 데이터에 대해 예측 결과를 생성합니다.
# - 이후, 예측 성능(정확도, 정밀도, 재현율 등)을 평가하거나 모델을 분석하는 데 사용됩니다.
---->
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis=1),
hotel_df['is_canceled'],
test_size=0.3, random_state=2025)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=2025)
rf.fit(X_train, y_train)
pred = rf.predict(X_test)
pred
--->
array([1, 1, 0, ..., 0, 0, 0])
예시 2)
# 이 코드는 RandomForestClassifier 모델을 사용하여 테스트 데이터(X_test)에 대해 각 클래스에 속할 확률을 예측합니다.
proba = rf.predict_proba(X_test)
# rf.predict_proba():
# - 랜덤 포레스트 모델(rf)을 사용하여 입력 데이터(X_test)에 대해 각 클래스에 속할 확률을 계산합니다.
# - 반환 값은 2차원 배열 형태입니다.
# - 각 행(row)은 하나의 샘플, 각 열(column)은 해당 클래스에 대한 확률을 나타냅니다.
# 반환 값(proba):
# - 2차원 배열(NumPy array)로 구성됩니다.
# - 이진 분류 문제의 경우:
# - 첫 번째 열: 클래스 0(취소되지 않음)일 확률
# - 두 번째 열: 클래스 1(취소됨)일 확률
# 예:
# X_test = [[feature1, feature2], [feature3, feature4]]
# proba = rf.predict_proba(X_test)
# 결과:
# [[0.7, 0.3], # 첫 번째 샘플이 클래스 0일 확률 70%, 클래스 1일 확률 30%
# [0.2, 0.8]] # 두 번째 샘플이 클래스 0일 확률 20%, 클래스 1일 확률 80%
# 사용 의도:
# - 모델의 예측 확률을 확인하여 분류의 신뢰도를 평가합니다.
# - 예를 들어, 특정 임계값(예: 0.5 이상)을 설정하여 클래스 예측을 조정하거나,
# ROC 곡선, PR 곡선과 같은 성능 지표를 계산하는 데 활용됩니다.
proba = rf.predict_proba(X_test)
proba
-->
array([[0. , 1. ],
[0.02, 0.98],
[0.96, 0.04],
...,
[1. , 0. ],
[0.99, 0.01],
[1. , 0. ]])
예시 3)
# 첫번째 테스트 데이터에 대한 예측 결과
proba[0]
--->
array([0., 1.])
예시 4)
# 모든 테스트 데이터에 대한 호텔 예약 취소할 확률만 출력
proba[:, 1]
--->
array([1. , 0.98, 0.04, ..., 0. , 0.01, 0. ])
예시 5)
# 이 코드는 테스트 데이터에 대한 모델의 정확도(accuracy)를 계산합니다.
accuracy_score(y_test, pred)
# accuracy_score():
# - scikit-learn에서 제공하는 함수로, 분류 모델의 정확도를 계산합니다.
# - 입력값:
# - y_test: 테스트 데이터의 실제 타겟값(정답)
# - pred: 모델이 예측한 타겟값
# 정확도 계산 공식:
# Accuracy = (TP + TN) / (TP + TN + FP + FN)
# - TP(True Positive): 실제 값과 예측 값이 모두 Positive(1)로 일치한 경우
# - TN(True Negative): 실제 값과 예측 값이 모두 Negative(0)로 일치한 경우
# - FP(False Positive): 실제 값이 Negative(0)인데 Positive(1)로 잘못 예측한 경우
# - FN(False Negative): 실제 값이 Positive(1)인데 Negative(0)로 잘못 예측한 경우
# - 정확도는 전체 예측 중에서 올바르게 예측한 비율을 나타냅니다.
# 반환 값:
# - 정확도는 0과 1 사이의 값으로 반환됩니다.
# - 1은 100% 정확한 예측, 0은 모든 예측이 틀렸음을 의미합니다.
# 예:
# y_test: [0, 1, 1, 0, 1]
# pred: [0, 1, 0, 0, 1]
# TP = 2 (1을 정확히 예측한 경우 2개)
# TN = 2 (0을 정확히 예측한 경우 2개)
# FP = 0 (0을 1로 잘못 예측한 경우 없음)
# FN = 1 (1을 0으로 잘못 예측한 경우 1개)
# Accuracy = (TP + TN) / (TP + TN + FP + FN) = (2 + 2) / (2 + 2 + 0 + 1) = 4/5 = 0.8
# 사용 의도:
# - 테스트 데이터에서 모델의 전반적인 성능을 평가하는 데 사용됩니다.
# - 높은 정확도는 모델이 대부분의 데이터를 정확히 예측했음을 나타냅니다.
accuracy_score(y_test, pred)
--->
1.0
예시 6)
# 이 코드는 confusion_matrix 함수를 사용하여 테스트 데이터(y_test)와 모델 예측 값(pred)을 비교한 혼동 행렬(confusion matrix)을 생성합니다.
confusion_matrix(y_test, pred)
# confusion_matrix():
# - 실제값(y_test)과 예측값(pred)을 비교하여 혼동 행렬을 생성합니다.
# - 입력:
# - y_test: 실제 타겟값(정답)
# - pred: 모델이 예측한 타겟값
# - 출력:
# - 혼동 행렬(confusion matrix), 이진 분류의 경우 2x2 배열로 반환됩니다.
# 혼동 행렬 구성:
# - 행: 실제값
# - 열: 예측값
# - 각 원소의 의미:
# - [0, 0]: 실제 0인 데이터를 0으로 예측한 개수 (True Negative, TN)
# - [0, 1]: 실제 0인 데이터를 1로 잘못 예측한 개수 (False Positive, FP)
# - [1, 0]: 실제 1인 데이터를 0으로 잘못 예측한 개수 (False Negative, FN)
# - [1, 1]: 실제 1인 데이터를 1로 예측한 개수 (True Positive, TP)
# 예:
# y_test: [0, 1, 1, 0, 1]
# pred: [0, 1, 0, 0, 1]
# confusion_matrix(y_test, pred):
# [[2, 0], # 실제 0인 데이터(TN=2), 0으로 예측(TN), 1로 잘못 예측(FP=0)
# [1, 2]] # 실제 1인 데이터(FN=1), 0으로 잘못 예측(FN), 1로 예측(TP=2)
# 사용 의도:
# - 모델이 얼마나 잘 예측했는지, 오류는 어디에서 발생했는지 확인할 수 있습니다.
# - 혼동 행렬은 정밀도(Precision), 재현율(Recall), F1 점수 등 추가 성능 지표를 계산하는 데 사용됩니다.
-->
array([[22217, 0],
[ 0, 12645]])
예시 7)
# 이 코드는 classification_report 함수를 사용하여 분류 모델의 성능에 대한 상세 보고서를 출력합니다.
from sklearn.metrics import classification_report
print(classification_report(y_test, pred))
# classification_report():
# - 실제 값(y_test)과 예측 값(pred)을 비교하여 모델 성능의 주요 지표를 계산한 보고서를 출력합니다.
# - 출력되는 주요 지표:
# 1. Precision (정밀도)
# - 모델이 Positive(1)로 예측한 것 중 실제로 Positive인 비율
# - 공식: Precision = TP / (TP + FP)
# 2. Recall (재현율, 민감도)
# - 실제 Positive(1) 값 중 모델이 정확히 예측한 비율
# - 공식: Recall = TP / (TP + FN)
# 3. F1-Score
# - Precision과 Recall의 조화 평균
# - 공식: F1 = 2 * (Precision * Recall) / (Precision + Recall)
# 4. Support
# - 각 클래스에 해당하는 실제 데이터의 개수
# 입력:
# - y_test: 테스트 데이터의 실제 타겟값(정답)
# - pred: 모델이 예측한 타겟값
# 출력 예:
# precision recall f1-score support
# 0 0.80 0.90 0.85 100
# 1 0.85 0.75 0.80 100
# accuracy 0.83 200
# macro avg 0.83 0.83 0.83 200
# weighted avg 0.83 0.83 0.83 200
# - precision, recall, f1-score: 클래스 0과 1 각각에 대해 계산된 값
# - support: 각 클래스의 실제 데이터 개수
# - accuracy: 전체 데이터에서 정확히 예측한 비율
# - macro avg: 모든 클래스의 평균 (클래스 간 가중치 동일)
# - weighted avg: 모든 클래스의 평균 (클래스의 데이터 수에 따라 가중치 부여)
# 사용 의도:
# - 모델의 성능을 종합적으로 평가할 수 있습니다.
# - 각 클래스의 분류 성능과 전체적인 성능을 확인하는 데 유용합니다.
from sklearn.metrics import classification_report
print(classification_report(y_test, pred))
---->--->

'LLM(Large Language Model)의 기초 > 머신러닝과 딥러닝' 카테고리의 다른 글
| 7. 파이토치로 구현한 논리 회귀 (2) | 2025.01.08 |
|---|---|
| 6. 서울 자전거 공유 수요 예측 데이터셋 (0) | 2025.01.08 |
| 5. 주택 임대료 예측 데이터셋 (0) | 2025.01.07 |
| 4. 사이킷런 (0) | 2025.01.07 |
| 3. 파이토치로 구현한 선형 회귀 (2) | 2025.01.06 |