1. PML
* PLM(Pre-trained Language Model)은 대량의 텍스트 데이터를 사전 학습하여 자연어 이해와 생성 능력을 갖춘 인공지능 모델입니다.
* 대표적으로 BERT, GPT, T5 등이 있으며, 이들은 대규모 데이터에서 단어의 의미와 문맥을 학습한 후, 특정 작업(예: 문장 분류, 번역, 질의응답 등)에 맞게 추가 학습(Fine-tuning)하여 활용됩니다.
* PLM은 문맥을 고려한 자연어 처리 능력이 뛰어나며, 다양한 언어 기반 AI 애플리케이션에서 핵심 기술로 사용됩니다.
1-1. BERT(Bidirectional Encoder Representations from Transformers)
* BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 개발한 사전 훈련된 자연어 처리(NLP) 모델로, Transformer 아키텍처를 기반으로 양방향 문맥 이해가 가능하도록 설계되었습니다.
* 기존 NLP 모델들은 단어의 앞 또는 뒤 방향으로만 문맥을 고려하는 경우가 많았지만, BERT는 문장의 양쪽 방향에서 동시에 문맥을 학습하여 더 정교한 언어 이해가 가능합니다.
* BERT는 두 가지 주요 사전 훈련 기법인 Masked Language Model(MLM)과 Next Sentence Prediction(NSP)을 사용하여 텍스트의 의미를 효과적으로 학습하며, 이를 통해 다양한 NLP 태스크(예: 문장 분류, 개체명 인식, 질의응답 시스템 등)에 적용될 수 있습니다.
* 또한, BERT는 기본적으로 사전 훈련된 후 특정 작업(Task-Specific Fine-tuning)을 통해 원하는 NLP 태스크에 맞게 미세 조정(fine-tuning)할 수 있어 강력한 성능을 발휘합니다.
논문 링크 주소 : https://arxiv.org/abs/1810.04805?source=post_page
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
1-2. GPT
* GPT(Generative Pre-trained Transformer)는 OpenAI에서 개발한 사전 훈련된 자연어 처리(NLP) 모델로, Transformer 아키텍처를 기반으로 한 자동회귀(Auto-regressive) 모델입니다.
* GPT는 대량의 텍스트 데이터로 사전 훈련을 수행한 후, 특정 태스크(Task-Specific Fine-tuning) 없이도 문장 생성, 번역, 요약 등 다양한 언어 관련 작업을 수행할 수 있습니다.
* 특히, GPT는 단방향 학습(unidirectional learning) 방식을 사용하여 입력된 문맥을 기반으로 다음 단어를 예측하며 텍스트를 생성하는데, 이는 챗봇, 스토리 생성, 코드 자동 완성 등 창의적인 콘텐츠 생성에 강력한 성능을 발휘합니다.
* GPT 시리즈는 버전이 업그레이드될수록 모델 크기와 성능이 향상되었으며, 특히 GPT-3와 GPT-4는 대규모 데이터를 활용한 학습으로 더욱 정교한 언어 이해와 생성 능력을 갖추고 있습니다.

2. Hugging Face
* Hugging Face는 자연어 처리(NLP)와 머신러닝(ML) 모델을 쉽게 활용할 수 있도록 지원하는 오픈소스 플랫폼이자 AI 회사입니다.
* 대표적으로 Transformers 라이브러리를 통해 BERT, GPT, T5 등 다양한 사전 학습된 모델을 제공하며, Datasets 라이브러리로 다양한 데이터셋을 효율적으로 활용할 수 있습니다.
* 또한, Hugging Face Hub에서는 연구자와 개발자들이 AI 모델과 데이터셋을 공유할 수 있으며, Gradio와 Spaces를 활용해 간단한 웹 애플리케이션으로 AI 모델을 배포할 수도 있습니다.
* PyTorch와 TensorFlow를 모두 지원하며, AI 연구 및 애플리케이션 개발을 보다 쉽게 만들어주는 강력한 도구입니다.
2-1. Hugging Face 모델 허브
* Hugging Face 모델 허브는 BERT, GPT, T5, Stable Diffusion 등 다양한 사전 학습된 AI 모델을 제공하는 공개 플랫폼입니다.
* 사용자는 자연어 처리(NLP), 컴퓨터 비전, 음성 인식 등 다양한 분야의 모델을 검색하고, PyTorch 또는 TensorFlow와 함께 손쉽게 활용할 수 있습니다.
* 모델마다 설명, 예제 코드, 라이선스 정보가 제공되며, 직접 학습한 모델을 업로드하거나 다른 연구자들이 공유한 모델을 다운로드하여 활용할 수도 있습니다.
* 이를 통해 연구자와 개발자는 AI 모델을 빠르게 실험하고 실제 애플리케이션에 적용할 수 있습니다.
* 검색창에 'ko' 또는 'kor'를 입력하여 한국어 모델을 서치할 수 있습니다.
Hugging Face 모델 링크 주소 : https://huggingface.co/models
2-2. Hugging Face를 이용한 토큰화
* Hugging Face의 각 모델은 각 모델과 맵핑되는 토크나이저가 존재합니다.
* A모델을 사용한다면 A모델의 토크나이저를 사용해야 합니다.
* 각 토크나이저는 Vocabulary 정보를 담고 있으므로 A모델에 B토크나이저를 사용할 경우, 입력을 이해하지 못하는 상황이 발생합니다.
* 예를 들어 A모델은 단어 '사과'가 3번이고, B모델은 단어 '사과'가 51번인데, 입력으로 '사과가 먹고싶다'라는 문장이 들어올 경우 입력의 혼선이 발생하게됩니다.
3. 한국어 금융 뉴스 긍정, 부정, 중립 분류하기
* 금융 뉴스 문장 감성 분석 데이터셋(Finance Sentiment Corpus)은 금융 관련 뉴스 문장을 긍정(Positive), 부정(Negative), 중립(Neutral)으로 분류한 감성 분석 데이터셋입니다.
* 이 데이터셋은 주식시장 예측, 금융 리포트 분석, 투자 전략 수립 등을 위해 자연어 처리(NLP) 모델을 훈련하는 데 활용됩니다.
* 일반적으로 주식 시장의 변동성과 연관된 뉴스 기사의 영향을 분석하는 데 유용하며, 금융 전문가의 의견, 기업 실적 발표, 경제 지표 등의 내용을 감성 레이블과 함께 제공합니다.
예시 1)
!pip install transformers
!pip install datasets
예시 2)
!wget https://raw.githubusercontent.com/ukairia777/finance_sentiment_corpus/main/finance_data.csv
예시 3)
import pandas as pd
import numpy as np
import random
import time
import datetime
import csv
import os
import torch
import torch.nn.functional as F
from tqdm import tqdm
from datasets import load_dataset
from torch.nn.utils.rnn import pad_sequence
# Huggomg Face Transformers 라이브러리
from transformers import pipeline
from transformers import BertTokenizer
from transformers import BertForSequenceClassification, AdamW, BertConfig
from transformers import get_linear_schedule_with_warmup
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from torch.nn.utils.rnn import pad_sequence
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score, hamming_loss
예시 4)
import pandas as pd # pandas 라이브러리를 불러옴
df = pd.read_csv('finance_data.csv') # 'finance_data.csv'라는 CSV 파일을 읽어와 데이터프레임(df)으로 저장
df.head() # 데이터프레임(df)의 상위 5개 행을 출력하여 데이터의 구조를 확인--->
예시 5)
# 'labels' 열에 있는 문자열 값을 숫자로 변환하여 업데이트
df['labels'] = df['labels'].replace(
['neutral', 'positive', 'negative'], # 변경할 기존 문자열 값들
[0, 1, 2] # 변경 후 숫자 값들 (neutral → 0, positive → 1, negative → 2)
)
df.head() # 데이터프레임(df)의 상위 5개 행을 출력하여 변경 사항 확인--->
예시 6)
# 데이터셋 불러오기
# load_dataset: 허깅페이스에서 데이터셋 불러오거나 내가 가지고있는 csv파일을 데이터셋으로 로드
all_data = load_dataset("csv", data_files={"train": "finance_data.csv"})
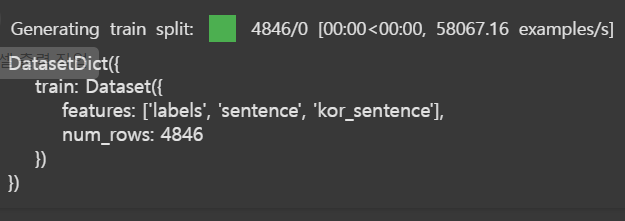
all_data
-->
DatasetDict({
train: Dataset({
features: ['labels', 'sentence', 'kor_sentence'],
num_rows: 4846
})
})
-->--->
예시 7)
def encode_labels(data):
label_map = {'neutral':0, 'positive':1, 'negative':2}
data['labels'] = label_map[data['labels']]
return data
예시 8)
# 데이터의 'labels' 컬럼을 숫자로 변환하는 함수
def encode_labels(data):
# 문자열 라벨을 숫자로 매핑하기 위한 딕셔너리 생성
label_map = {'neutral': 0, 'positive': 1, 'negative': 2}
# 주어진 데이터에서 'labels' 키의 값을 label_map에서 해당하는 숫자로 변환
data['labels'] = label_map[data['labels']]
return data # 변환된 데이터를 반환
예시 9)
# train 데이터의 각 행에 대해 encode_labels 함수를 적용하여 'labels'을 숫자로 변환
all_data['train'] = all_data['train'].map(encode_labels) # 여기서 map()은 각 행에 encode_labels 함수를 적용--->

예시 10)
# 학습 데이터를 80:20 비율로 나눈 후, 다시 학습 데이터와 검증 데이터를 80:20으로 분할
cs = all_data['train'].train_test_split(0.2) # 전체 train 데이터를 80% 학습, 20% 테스트로 나눔
train_cs = cs["train"] # 학습 데이터 (80%)
test_cs = cs["test"] # 테스트 데이터 (20%)
train_cs # 학습 데이터 출력
-->
Dataset({
features: ['labels', 'sentence', 'kor_sentence'],
num_rows: 3876
})
예시 11)
# 테스트 데이터
test_cs
-->
Dataset({
features: ['labels', 'sentence', 'kor_sentence'],
num_rows: 970
})
예시 12)
# 테스트로 빼고 나머지 train_cs데이터에서 20%를 검증데이터로 나눈다
cs = train_cs.train_test_split(0.2)
train_cs = cs["train"]
valid_cs = cs["test"]
-->
Dataset({
features: ['labels', 'sentence', 'kor_sentence'],
num_rows: 3876
})
예시 13)
# 검증 데이터
valid_cs
-->
Dataset({
features: ['labels', 'sentence', 'kor_sentence'],
num_rows: 776
})
예시 14)
print('두번째 샘플 출력 :', train_cs['kor_sentence'][1])
print('두번째 샘플의 레이블 출력 :', train_cs['labels'][1])
--->
두번째 샘플 출력 : 헬싱키 AFX - KCI 코네크란스는 인도 철강 생산업체인 부샨 스틸 앤 스트립스(Bushan Streel and Strips Ltd)로부터 4대의 뜨거운 금속 레이들 크레인을 수주했다고 밝혔다.
두번째 샘플의 레이블 출력 : 1
예시 15)
# CLS : BERT 모델의 문장의 시작을 나타내는 특수 토큰
# [SEP] : BER 모델의 문장의 끝을 나타내는 특수 토큰, 문장의 구분으로도 사용
# BERT 모델에서 사용하는 특수 토큰 [CLS]와 [SEP]을 문장 앞뒤에 추가
train_sentences = list(map(lambda x: ' [CLS] ' + str(x) + ' [SEP] ', train_cs['kor_sentence']))
validation_sentences = list(map(lambda x: ' [CLS] ' + str(x) + ' [SEP] ', valid_cs['kor_sentence']))
test_sentences = list(map(lambda x: ' [CLS] ' + str(x) + ' [SEP] ', test_cs['kor_sentence']))
예시 16)
# 학습(train), 검증(validation), 테스트(test) 데이터에서 'labels' 컬럼만 추출하여 변수에 저장
# 학습 데이터(train_cs)에서 'labels' 컬럼을 추출하여 train_labels 변수에 저장
train_labels = train_cs['labels']
# 검증 데이터(valid_cs)에서 'labels' 컬럼을 추출하여 validation_labels 변수에 저장
validation_labels = valid_cs['labels']
# 테스트 데이터(test_cs)에서 'labels' 컬럼을 추출하여 test_labels 변수에 저장
test_labels = test_cs['labels']
예시 17)
train_sentences[:5] #5개만 추출
--->
[' [CLS] 회사는 2005년 해당 기간의 손실액이 1.9 mn이었던 것에 비해 0.4 mn의 손실을 보고하고 있습니다. [SEP] ',
' [CLS] 헬싱키 AFX - KCI 코네크란스는 인도 철강 생산업체인 부샨 스틸 앤 스트립스(Bushan Streel and Strips Ltd)로부터 4대의 뜨거운 금속 레이들 크레인을 수주했다고 밝혔다. [SEP] ',
' [CLS] 알마미디어의 2006년 옵션 프로그램 약관에 따르면 2006A 옵션권 주식가입가격은 주당 4.88유로, 장부상 역가치는 주당 0.60유로였다. [SEP] ',
' [CLS] Matti Tikkakoski의 사장 겸 CEO에 따르면, 이 회사의 스웨덴 사업부는 1/4분기에 크게 개선되었다. [SEP] ',
' [CLS] 주문 금액은 거의 EUR400m입니다. [SEP] ']
예시 18)
test_labels[:5] # 테스트 데이터셋에서 처음 5개의 라벨 출력
-->
[1, 0, 2, 1, 1]
예시 19)
# 한국어 BERT 중 하나인 'klue/bert-base'를 사용
tokenizer = BertTokenizer.from_pretrained('klue/bert-base')
--->--->
예시 20)
# BERT 모델에 입력 스퀀스의 최대 문장 길이
MAX_LEN = 128
def data_to_tensor(sentences, labels, tokenizer):
# 정수 인코딩: 각 텍스트를 토큰화한 후 Vocabulary에 맵핑되는 정수 시퀀스로 변환
# 문장을 BERT 모델이 이행할수 있도록 토큰 단위로 변환
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
# 토큰을 정수 인덱스로 변환
input_ids = [torch.tensor(tokenizer.convert_tokens_to_ids(x)) for x in tokenized_texts]
# PyTorch의 pad_sequence 사용 (batch_first=True로 설정)
padded_inputs = pad_sequence(input_ids, batch_first=True, padding_value=0)
# 고정된 MAX_LEN 길이로 패딩 적용 (부족하면 0 추가, 길면 자름)
if padded_inputs.shape[1] < MAX_LEN:
padded_inputs = F.pad(padded_inputs, (0, MAX_LEN - padded_inputs.shape[1]), value=0)
else:
padded_inputs = padded_inputs[:, :MAX_LEN]
# Attention Mask 생성 (0이 아닌 값은 1, 0은 0)
# 패딩되지 않은 부분(실제 문장) : 1. 패딩된 부분(0) : 0
# BERT 모델은 패딩 부분을 무시하도록 생성
attention_masks = (padded_inputs != 0).float()
# 텐서 변환
tensor_inputs = padded_inputs
tensor_labels = torch.tensor(labels)
tensor_masks = attention_masks
return tensor_inputs, tensor_labels, tensor_masks
예시 21)
# 데이터를 텐서 형태로 변환
train_inputs, train_labels, train_masks = data_to_tensor(train_sentences, train_labels, tokenizer)
validation_inputs, validation_labels, validation_masks = data_to_tensor(validation_sentences, validation_labels, tokenizer)
test_inputs, test_labels, test_masks = data_to_tensor(test_sentences, test_labels, tokenizer)
# 변환된 첫 번째 학습 데이터 샘플 확인
print(train_inputs[0]) # 첫 번째 문장의 입력 텐서 출력
print(train_labels[0]) # 첫 번째 문장의 라벨 출력
--->
tensor([ 2, 67, 67, 4515, 5208, 27135, 9191, 7285, 12908, 2116,
2259, 3635, 2116, 1513, 2219, 3606, 18, 6, 3609, 14570,
1370, 2116, 1041, 2371, 2219, 3606, 18, 3, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0])
tensor(2)
예시 22)
print(train_labels[:5]) # 처음 5개 라벨 출력
--->
tensor([2, 0, 0, ..., 1, 1, 0])
예시 23)
# BERT 토크나이저를 사용하여 특정 토큰 ID를 디코딩하여 해당하는 문자(토큰) 출력
# 토큰 ID 2를 디코딩하여 출력 (BERT 모델에서 [SEP] 또는 </s>일 가능성이 높음)
print(tokenizer.decode([2]))
# 토큰 ID 3을 디코딩하여 출력 (BERT 모델에서 [unused0]으로 나올 가능성이 있음)
print(tokenizer.decode([3]))
# 토큰 ID 4을 디코딩하여 출력 (BERT 모델에서 [unused1]으로 나올 가능성이 있음)
print(tokenizer.decode([4]))
--->
[CLS]
[SEP]
[MASK]
예시 24)
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
# 배치 크기 설정
batch_size = 32
# 학습 데이터 (Training Data) 생성 및 데이터로더 설정
# 텐서 데이터셋 생성 (입력값, 어텐션 마스크, 라벨을 하나의 데이터셋으로 묶음)
train_data = TensorDataset(train_inputs, train_masks, train_labels)
# 학습 데이터는 랜덤하게 섞어서 배치 단위로 학습하기 위해 랜덤 샘플링 적용
train_sampler = RandomSampler(train_data)
# DataLoader를 사용해 미니배치 단위로 데이터 제공
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
# 검증 데이터 (Validation Data) 생성 및 데이터로더 설정
# 텐서 데이터셋 생성 (입력값, 어텐션 마스크, 라벨 포함)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
# 검증 데이터는 순차적으로 모델 평가를 진행해야 하므로 SequentialSampler 사용
validation_sampler = SequentialSampler(validation_data)
# 검증 데이터도 DataLoader를 사용해 배치 단위로 제공
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
# 테스트 데이터 (Test Data) 생성 및 데이터로더 설정
# 텐서 데이터셋 생성 (입력값, 어텐션 마스크, 라벨 포함)
test_data = TensorDataset(test_inputs, test_masks, test_labels)
# 테스트 데이터도 랜덤 샘플링을 적용하여 평가 시 모델이 데이터 분포를 다양하게 접하도록 함
test_sampler = RandomSampler(test_data)
# 테스트 데이터도 DataLoader를 사용해 배치 단위로 제공
test_dataloader = DataLoader(test_data, sampler=test_sampler, batch_size=batch_size)
# 데이터 크기 출력
print('훈련 데이터의 크기:', len(train_labels)) # 학습 데이터 개수 출력
print('검증 데이터의 크기:', len(validation_labels)) # 검증 데이터 개수 출력
print('테스트 데이터의 크기:', len(test_labels)) # 테스트 데이터 개수 출력
--->
훈련 데이터의 크기: 3100
검증 데이터의 크기: 776
테스트 데이터의 크기: 970
예시 25)
num_labels = 3
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
-->
device(type='cuda')
### 결과 출력 추가하였습니다.
예시 26)
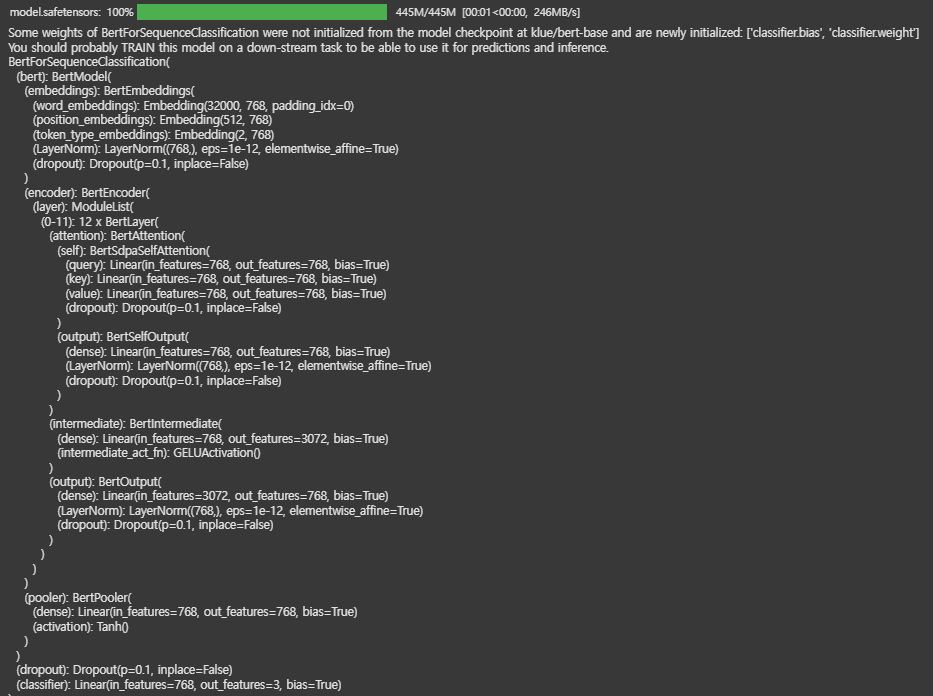
from transformers import BertForSequenceClassification
# 사전 학습된 KLUE-BERT 모델을 불러와 분류 모델로 사용
model = BertForSequenceClassification.from_pretrained("klue/bert-base", num_labels=num_labels)
# 모델을 GPU로 이동 (CUDA 사용)
model.cuda()--->
예시 27)
# BERT에 추천 알고리즘 : 0.00002
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
epochs = 5
total_steps = len(train_dataloader) * epochs
# 학습 초반에는 학습률을 천천히 증가시킨 후, 점진적으로 감소시키는 방법
# num_warmup_steps: 0, 처음 설정된 값으로 학습 시작
# num_training_steps : 총 학습 스텝 수
# 보통 num_warmup_steps의 10% 정도를 설정
# 총 485스텝 중 10% 학습률을 증가시키고 이후 감소
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
-->
/usr/local/lib/python3.11/dist-packages/transformers/optimization.py:591: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
예시 28)
# train_dataloader의 길이(= 전체 미니배치 개수)를 구한 후, 5번 반복(에포크 5) 동안 총 배치 개수를 계산
# train_dataloader는 미니배치 단위로 데이터를 불러오는 DataLoader 객체
# len(train_dataloader)는 전체 학습 데이터를 배치 크기(batch_size)로 나눈 미니배치 개수를 반환
num_batches = len(train_dataloader)
# 전체 학습 과정에서 5번(에포크 5) 반복할 경우, 총 학습 스텝(배치 개수) 계산
total_train_steps = num_batches * 5
# 총 학습 스텝 출력
print("총 학습 스텝 수:", total_train_steps)
-->
485
예제 29)
import datetime
from sklearn.metrics import accuracy_score, f1_score
# 경과 시간을 "시:분:초" 형식으로 변환하는 함수
def format_time(elapsed):
elapsed_rounded = int(round((elapsed))) # 초 단위로 반올림
return str(datetime.timedelta(seconds=elapsed_rounded)) # 시:분:초 형식으로 변환하여 반환
# 예측값과 실제값을 비교하여 정확도 및 F1-score를 계산하는 함수
def metrics(predictions, labels):
y_pred = predictions # 모델이 예측한 값
y_true = labels # 실제 정답 라벨
# 정확도(Accuracy) 계산
accuracy = accuracy_score(y_true, y_pred)
# 각 클래스별 F1-score를 구한 후 평균 (클래스 간 균형 고려)
f1_macro_average = f1_score(y_true=y_true, y_pred=y_pred, average='macro', zero_division=0)
# 전체 샘플을 기준으로 F1-score를 계산 (데이터 불균형이 심할 때 사용)
f1_micro_average = f1_score(y_true=y_true, y_pred=y_pred, average='micro', zero_division=0)
# 각 클래스의 샘플 수를 고려하여 가중 평균을 적용 (클래스 개수가 많을 때 유용)
f1_weighted_average = f1_score(y_true=y_true, y_pred=y_pred, average='weighted', zero_division=0)
# 모든 메트릭 결과를 딕셔너리로 저장하여 반환
metrics_result = {
'accuracy': accuracy, # 정확도
'f1_macro': f1_macro_average, # 클래스별 동일 가중 평균 F1-score
'f1_micro': f1_micro_average, # 전체 샘플 기준 F1-score
'f1_weighted': f1_weighted_average # 가중 평균 F1-score
}
return metrics_result # 메트릭 결과 반환
예시 30)
# 랜덤 시드값 설정
seed_val = 2025
# Python의 기본 랜덤 모듈의 시드값 설정 (random 모듈 사용 시 동일한 결과 보장)
random.seed(seed_val)
# NumPy의 랜덤 시드값 설정 (NumPy 사용 시 동일한 결과 보장)
np.random.seed(seed_val)
# PyTorch의 랜덤 시드값 설정 (CPU 연산 시 동일한 결과 보장)
torch.manual_seed(seed_val)
# PyTorch의 CUDA(그래픽 카드)에서 실행되는 연산의 랜덤 시드값 설정 (GPU 연산 시 동일한 결과 보장)
torch.cuda.manual_seed_all(seed_val)
예시 31)
model.zero_grad() # PyTorch 모델의 모든 기울기(gradient)를 초기화하는 역할
예시 32)
import time
from tqdm import tqdm
# 학습 루프 (총 epochs 만큼 반복)
for epoch_i in range(0, epochs):
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs)) # 현재 에포크 표시
t0 = time.time() # 에포크 시작 시간 저장
total_loss = 0 # 총 손실값 초기화
model.train() # 모델을 학습 모드로 설정 (dropout 등 활성화)
# 미니배치 단위로 학습 진행
for step, batch in tqdm(enumerate(train_dataloader)): # tqdm을 이용해 진행률 표시
# 500번째 배치마다 진행 상태 출력
if step % 500 == 0 and not step == 0:
elapsed = format_time(time.time() - t0) # 경과 시간 계산
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 배치를 GPU/CPU 디바이스로 이동 (PyTorch 텐서를 해당 장치로 변환)
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch # 배치에서 입력 데이터, 마스크, 라벨 분리
# 순전파(FORWARD)
outputs = model(b_input_ids,
token_type_ids=None, # 문장 구분을 위한 토큰 (여기서는 사용 안 함)
attention_mask=b_input_mask, # 패딩된 부분을 무시하도록 마스크 적용
labels=b_labels) # 정답 라벨 입력 (자동으로 loss 계산됨)
loss = outputs[0] # 모델이 반환하는 첫 번째 값이 손실(loss)
total_loss += loss.item() # 총 손실값 업데이트
loss.backward() # 역전파(BACKPROPAGATION) 수행하여 기울기 계산
# gradient clipping (기울기 값이 너무 커지는 것을 방지하여 안정적 학습)
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step() # 옵티마이저를 사용해 가중치 업데이트
scheduler.step() # 학습률 스케줄러 업데이트 (학습률 조정)
model.zero_grad() # 다음 스텝을 위해 기울기 초기화
# 평균 학습 손실값 계산
avg_train_loss = total_loss / len(train_dataloader)
# 에포크 종료 후 학습 결과 출력
print("")
print(" Average training loss: {0:.4f}".format(avg_train_loss)) # 평균 손실값 출력
print(" Training epoch took: {:}".format(format_time(time.time() - t0))) # 에포크당 학습 소요 시간 출력
---->
======== Epoch 1 / 5 ========
97it [00:57, 1.70it/s]
Average training loss: 0.5710
Training epcoh took: 0:00:57
======== Epoch 2 / 5 ========
97it [00:59, 1.63it/s]
Average training loss: 0.3084
Training epcoh took: 0:01:00
======== Epoch 3 / 5 ========
97it [00:59, 1.64it/s]
Average training loss: 0.1976
Training epcoh took: 0:00:59
======== Epoch 4 / 5 ========
97it [00:59, 1.63it/s]
Average training loss: 0.1175
Training epcoh took: 0:00:59
======== Epoch 5 / 5 ========
97it [00:59, 1.63it/s]
Average training loss: 0.0750
Training epcoh took: 0:00:59
예제 33)
import time
import numpy as np
import torch
# 검증 시작 시간 기록
t0 = time.time()
# 모델을 평가 모드로 변경 (Dropout, BatchNorm 등이 비활성화됨)
model.eval()
# 예측값과 실제 라벨을 저장할 리스트 초기화
accum_logits, accum_label_ids = [], []
# 검증 데이터셋을 배치 단위로 예측
for batch in validation_dataloader:
# 배치를 GPU/CPU 디바이스로 이동
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch # 입력 데이터, 마스크, 라벨 분리
# 역전파(Gradient 계산) 비활성화 (메모리 절약)
with torch.no_grad():
outputs = model(b_input_ids,
token_type_ids=None, # 문장 구분을 위한 토큰 (사용 안 함)
attention_mask=b_input_mask) # 패딩된 부분을 무시하도록 마스크 적용
# 모델 출력값 (logits) 가져오기
logits = outputs[0]
# logits을 CPU로 이동 후 NumPy 배열로 변환
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 예측값 저장
for b in logits:
# 3개의 클래스 중 가장 큰 값(확률)을 가진 인덱스를 예측값으로 결정
# 예: [3.51, -0.30, -2.11] => np.argmax([3.51, -0.30, -2.11]) => 0
accum_logits.append(np.argmax(b))
# 실제 라벨 저장
for b in label_ids:
accum_label_ids.append(b)
# 리스트를 NumPy 배열로 변환
accum_logits = np.array(accum_logits) # 모델 예측값
accum_label_ids = np.array(accum_label_ids) # 실제 정답 라벨
# 정확도 및 F1-score 계산
results = metrics(accum_logits, accum_label_ids)
# 평가 결과 출력
print("Accuracy: {0:.4f}".format(results['accuracy']))
print("F1 (Macro) Score: {0:.4f}".format(results['f1_macro']))
print("F1 (Micro) Score: {0:.4f}".format(results['f1_micro']))
print("F1 (Weighted) Score: {0:.4f}".format(results['f1_weighted']))
--->
Accuracy: 0.8531
F1 (Macro) Score: 0.8419
F1 (Micro) Score: 0.8419
F1 (Weighted) Score: 0.8544
예제 34)
# 현재 작업 디렉토리(폴더)를 출력하는 리눅스 명령어
%pwd
-->
/content
예제 35)
# 현재 작업 디렉토리 내에 'model'이라는 새로운 폴더(디렉토리)를 생성하는 리눅스 명령어
%mkdir model
예제 36)
# 'path' 변수에 폴더 경로를 저장
path = '/content/model/'
예제 37)
import torch
# 현재 학습된 모델의 가중치(state_dict)를 저장하는 코드
# path 변수에 저장된 디렉토리에 "BERT_news_positive_negative_model.pt" 파일로 저장
torch.save(model.state_dict(), path + "BERT_news_positive_negative_model.pt")
예제 38)
import torch
# 저장된 모델 가중치를 로드하여 현재 모델에 적용하는 코드
model.load_state_dict(torch.load(path + "BERT_news_positive_negative_model.pt"))
-->
<ipython-input-38-ca45ec3611a6>:1: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
model.load_state_dict(torch.load(path+"BERT_news_positive_negative_model.pt"))
<All keys matched successfully>
예제 39)
import time
import numpy as np
import torch
from tqdm import tqdm
# 평가 시작 시간 기록
t0 = time.time()
# 모델을 평가 모드로 변경 (Dropout, BatchNorm 등 비활성화됨)
model.eval()
# 예측값과 실제 라벨을 저장할 리스트 초기화
accum_logits, accum_label_ids = [], []
# 테스트 데이터셋을 배치 단위로 예측
for step, batch in tqdm(enumerate(test_dataloader)):
# 100번째 배치마다 진행 상태 출력
if step % 100 == 0 and not step == 0:
elapsed = format_time(time.time() - t0) # 경과 시간 계산
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(test_dataloader), elapsed))
# 배치를 GPU/CPU 디바이스로 이동 (모델이 실행될 장치에 맞춤)
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch # 입력 데이터, 마스크, 라벨 분리
# 그래디언트 계산 비활성화 (메모리 절약, 연산 속도 향상)
with torch.no_grad():
outputs = model(b_input_ids,
token_type_ids=None, # 문장 구분을 위한 토큰 (사용 안 함)
attention_mask=b_input_mask) # 패딩된 부분을 무시하도록 마스크 적용
# 모델 출력값 (logits) 가져오기
logits = outputs[0]
# logits을 CPU로 이동 후 NumPy 배열로 변환
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 예측값 저장
for b in logits:
# 3개의 클래스 중 가장 높은 값(확률)을 가진 인덱스를 예측값으로 결정
# 예: [3.51, -0.30, -2.11] => np.argmax([3.51, -0.30, -2.11]) => 0
accum_logits.append(np.argmax(b))
# 실제 라벨 저장
for b in label_ids:
accum_label_ids.append(b)
# 리스트를 NumPy 배열로 변환
accum_logits = np.array(accum_logits) # 모델 예측값
accum_label_ids = np.array(accum_label_ids) # 실제 정답 라벨
# 정확도 및 F1-score 계산
results = metrics(accum_logits, accum_label_ids)
# 평가 결과 출력
print("Accuracy: {0:.4f}".format(results['accuracy']))
print("F1 (Macro) Score: {0:.4f}".format(results['f1_macro']))
print("F1 (Micro) Score: {0:.4f}".format(results['f1_micro']))
print("F1 (Weighted) Score: {0:.4f}".format(results['f1_weighted']))
--->
31it [00:06, 4.91it/s]Accuracy: 0.8485
F1 (Macro) Score: 0.8314
F1 (Micro) Score: 0.8314
F1 (Weighted) Score: 0.8498
예제 40)
from transformers import pipeline
# Hugging Face의 transformers 라이브러리에서 제공하는 'pipeline' 함수를 사용하여
# 사전 학습된 BERT 모델을 활용한 텍스트 분류 파이프라인을 생성
pipe = pipeline(
"text-classification", # 파이프라인 유형: 텍스트 분류 모델 실행
model=model.cuda(), # 학습된 BERT 모델을 GPU에서 실행
tokenizer=tokenizer, # 사용할 토크나이저 (BERT 모델과 동일한 토크나이저 사용)
device=0, # GPU(디바이스 0번)에서 실행 (CPU 사용 시 device=-1)
max_length=512, # 입력 문장의 최대 길이를 512 토큰으로 제한 (BERT의 최대 길이)
return_all_scores=True, # 모든 클래스(라벨)에 대한 확률 점수를 반환
function_to_apply='softmax' # softmax 함수를 적용하여 확률 값으로 변환
)
예제 41)
result = pipe('SK하이닉스가 매출이 급성장하였다') # 모델을 사용하여 분류 수행
print(result)
예제 42)
from transformers import pipeline
# Hugging Face의 transformers 라이브러리에서 제공하는 'pipeline' 함수를 사용하여
# 사전 학습된 BERT 모델을 활용한 텍스트 분류 파이프라인을 생성
pipe = pipeline(
"text-classification", # 파이프라인 유형: 텍스트 분류 모델 실행
model=model.cuda(), # 학습된 BERT 모델을 GPU에서 실행
tokenizer=tokenizer, # 사용할 토크나이저 (BERT 모델과 동일한 토크나이저 사용)
device=0, # GPU(디바이스 0번)에서 실행 (CPU 사용 시 device=-1)
max_length=512, # 입력 문장의 최대 길이를 512 토큰으로 제한 (BERT의 최대 길이)
function_to_apply='softmax' # softmax 함수를 적용하여 확률 값으로 변환
)
-->
Device set to use cuda:0
/usr/local/lib/python3.11/dist-packages/transformers/pipelines/text_classification.py:106: UserWarning: `return_all_scores` is now deprecated, if want a similar functionality use `top_k=None` instead of `return_all_scores=True` or `top_k=1` instead of `return_all_scores=False`.
warnings.warn(
예제 43)
result = pipe('SK하이닉스가 매출이 급성장하였다')
print(result)
-->
Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
[[{'label': 'LABEL_0', 'score': 0.0050628227181732655}, {'label': 'LABEL_1', 'score': 0.9905217885971069}, {'label': 'LABEL_2', 'score': 0.004415479023009539}]]
예제 44)
from transformers import pipeline
# text-classification(텍스트 분류) 작업을 위한 pipeline 생성
pipe = pipeline(
"text-classification", # 분류 작업을 수행할 파이프라인 지정
model=model.cuda(), # 미리 로드된 모델을 GPU로 이동하여 사용
tokenizer=tokenizer, # 토크나이저 설정
device=0, # GPU 사용 (CUDA 장치 번호 0번 사용)
max_length=512, # 입력 텍스트의 최대 길이를 512 토큰으로 제한
function_to_apply='softmax' # 출력값에 소프트맥스 함수를 적용하여 확률값 반환
)
예제 45)
# 모델이 반환하는 라벨(Label) 값을 사람이 이해하기 쉬운 한글 라벨로 매핑하는 딕셔너리
label_dict = {
'LABEL_0': '중립', # 모델이 'LABEL_0'을 반환하면 '중립'으로 해석
'LABEL_1': '긍정', # 모델이 'LABEL_1'을 반환하면 '긍정'으로 해석
'LABEL_2': '부정' # 모델이 'LABEL_2'을 반환하면 '부정'으로 해석
}
예제 46)
# 입력된 텍스트를 BERT 모델을 사용하여 감성 분석하고, 결과를 한글 라벨로 변환하는 함수
def prediction(text):
# Hugging Face의 pipeline을 사용하여 텍스트 분류 수행
result = pipe(text)
# 모델이 반환한 라벨 값을 한글 라벨로 변환하여 리스트 형태로 반환
return [label_dict[result[0]['label']]]
예제 47)
prediction('인공지능 기술의 발전으로 누군가는 기회를 얻을 것이고, 누군가는 얻지 못할 것이다') # ['중립']
prediction('많은 중소기업들이 회사를 정리하고 있다') # ['부정']
4. 학습 테크닉의 발전
4-1. 전이 학습(Transfer Learning)
* 전이 학습(Transfer Learning)은 한 작업(Task)에서 학습한 지식을 다른 관련 작업에 적용하는 머신러닝 기법입니다.
* 일반적으로 대량의 데이터와 연산 자원이 필요한 모델을 처음부터 새롭게 훈련하는 대신, 사전 훈련된 모델(Pre-trained Model)의 가중치를 가져와 새로운 데이터에 맞게 일부 층을 조정(Fine-tuning)하거나 특정 기능을 고정(Feature Extraction)하여 활용합니다.
* 예를 들어, 이미지 분류 모델로 사전 훈련된 CNN(합성곱 신경망) 모델의 초기 계층을 고정하고, 마지막 분류 계층만 새로운 데이터에 맞게 학습시키는 방식이 대표적입니다.
* 이는 데이터가 적거나 학습 시간이 제한된 상황에서 높은 성능을 얻을 수 있도록 도와주며, 자연어 처리(NLP), 컴퓨터 비전(CV) 등 다양한 분야에서 널리 사용됩니다.
4-2. Multi-task Learning
* 멀티 태스크 러닝(Multi-task Learning, MTL)은 하나의 모델이 여러 관련된 작업(Task)을 동시에 학습하도록 하는 머신러닝 기법입니다.
* 이는 여러 개의 작업이 공통된 정보를 공유할 수 있다는 가정하에, 하나의 모델이 다양한 태스크에서 학습한 지식을 활용하여 성능을 향상시키도록 합니다.
* 일반적으로 MTL 모델은 공유된 표현 학습(Shared Representation Learning)을 통해 서로 다른 태스크 간에 특징(feature)을 공유하며, 이를 통해 데이터 효율성을 높이고 과적합(overfitting)을 방지할 수 있습니다.
* 예를 들어, 자연어 처리(NLP)에서는 문장 분류, 개체명 인식(NER), 감정 분석 등의 작업을 하나의 모델에서 함께 학습할 수 있으며, 컴퓨터 비전에서는 물체 감지(Object Detection)와 이미지 분할(Segmentation)을 동시에 수행할 수 있습니다.
* MTL은 모델이 일반화 성능을 높이고 특정 태스크에 대한 편향을 줄이는 데 유용하게 활용됩니다.
4-3. Zero-shot & Few-shot Learning
* Zero-shot Learning(ZSL)과 Few-shot Learning(FSL)은 적은 양의 데이터 또는 전혀 학습되지 않은 클래스에 대해 모델이 일반화하여 예측할 수 있도록 하는 기법입니다.
* Zero-shot Learning(ZSL)은 특정 태스크나 클래스에 대한 사전 학습 없이, 모델이 기존에 학습한 개념과 관계를 활용하여 새로운 개념을 이해하고 예측하는 방법입니다.
* 예를 들어, 이미지 분류에서 "코끼리"라는 클래스를 학습한 적이 없더라도, "큰 몸집, 긴 코"와 같은 속성 정보를 기반으로 새로운 클래스를 예측할 수 있습니다.
* 반면, Few-shot Learning(FSL)은 매우 적은 데이터 샘플(예: 1~5개)만 가지고도 새로운 태스크를 학습할 수 있도록 하는 방법으로, 대표적인 접근법으로는 메타 학습(Meta-learning)과 사전 훈련된 대규모 모델을 활용한 방법이 있습니다.
* 이러한 기법들은 특히 자연어 처리(NLP), 이미지 분류, 의료 진단 등 데이터가 제한적인 환경에서 강력한 성능을 발휘합니다.
4-4. Hierachical Attention
* Hierarchical Attention(계층적 어텐션)은 자연어 처리(NLP)에서 문서 또는 긴 문장을 보다 효과적으로 이해하기 위해 어텐션 메커니즘을 계층적으로 적용하는 기법입니다.
* 일반적인 어텐션 메커니즘은 모든 단어에 동일한 방식으로 가중치를 부여하지만, 계층적 어텐션은 문서 구조를 반영하여 단어 수준(word-level) 어텐션과 문장 수준(sentence-level) 어텐션을 각각 학습합니다.
* 먼저 단어 수준 어텐션을 사용하여 각 문장에서 중요한 단어를 강조한 후, 문장 수준 어텐션을 통해 전체 문서에서 중요한 문장을 추출하는 방식으로 동작합니다.
* 이를 통해 모델은 긴 문서에서도 핵심 정보를 효과적으로 추출할 수 있으며, 감성 분석, 문서 요약, 기계 번역 등 다양한 NLP 태스크에서 성능을 향상시키는 데 활용됩니다.
* 대표적인 예로는 Hierarchical Attention Networks(HAN) 모델이 있으며, 이는 문맥을 보다 깊이 있게 반영하여 문서 분류 작업에서 강력한 성능을 보입니다.
4-5. Knowledge Distillation
* Knowledge Distillation(지식 증류)은 크고 복잡한 모델(Teacher Model)의 지식을 작은 모델(Student Model)에 전달하여 성능을 유지하면서도 경량화하는 모델 압축 기법입니다.
* 일반적으로 대규모 신경망은 높은 성능을 가지지만 연산 비용이 크고 실시간 응용에 적합하지 않은 경우가 많습니다.
* 이를 해결하기 위해 Knowledge Distillation에서는 Teacher Model이 예측한 소프트 확률 분포(Soft Targets)를 Student Model이 학습하도록 하여 일반적인 정답 레이블(Hard Labels)보다 더 풍부한 정보(예: 클래스 간 관계)를 제공받을 수 있도록 합니다.
* 이 과정에서 온도 매개변수(Temperature Scaling)를 활용하여 Soft Targets의 정보를 조절하며, Student Model은 이를 통해 일반화 성능을 개선하고 모델의 크기와 추론 속도를 최적화할 수 있습니다.
* Knowledge Distillation은 모바일 기기, 임베디드 시스템 등 제한된 자원 환경에서 강력한 모델을 구현하는 데 유용하며, 자연어 처리(NLP), 컴퓨터 비전(CV) 등 다양한 분야에서 널리 활용됩니다.
4-6. Human Feedback 기반의 Reinforcement Learning
* Human Feedback 기반 강화 학습(RLHF, Reinforcement Learning from Human Feedback)은 전통적인 강화 학습(RL)에서 보상 함수(Reward Function)를 사람이 직접 제공하는 피드백을 활용하여 학습하는 방법입니다.
* 일반적인 RL에서는 환경에서 자동으로 계산된 보상을 기반으로 에이전트가 최적의 행동을 학습하지만, RLHF에서는 사람이 직접 행동에 대한 선호도(Preference)나 보상을 제공하여 보다 직관적이고 정교한 학습이 가능합니다.
* 이 방법은 특히 명확한 보상 설계가 어려운 자연어 처리(NLP)나 윤리적 AI 개발에서 효과적이며, 예를 들어 OpenAI의 GPT 모델은 RLHF를 활용하여 사용자에게 더욱 자연스럽고 유용한 응답을 생성하도록 학습되었습니다.
* RLHF는 먼저 사람이 데이터에 태그를 달아 보상 모델(Reward Model)을 학습하고, 이후 강화 학습을 통해 모델이 인간의 선호도를 반영하도록 최적화하는 과정을 거칩니다.
* 이를 통해 AI 모델이 단순히 성능 최적화뿐만 아니라, 보다 인간 친화적이고 윤리적인 결과를 생성할 수 있도록 돕습니다.
'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 14. 벡터 데이터베이스 (6) | 2025.02.19 |
|---|---|
| 13. RAG (2) | 2025.02.17 |
| 11. 트랜스포머 (2) | 2025.02.12 |
| 10. 어텐션 메커니즘 (1) | 2025.02.12 |
| 8. Seq2Seq (0) | 2025.02.11 |