1. ChatGPT의 서비스 제약
Chat-GPT 정책 링크주소 : https://openai.com/ko-KR/policies/privacy-policy/
"위에서 설명한 바와 같이, OpenAI는 ChatGPT의 기반이 되는 모델을 훈련시키는 등 서비스를 개선하기 위하여 귀하가 OpenAI에 제공하는 콘텐츠를 이용할 수 있습니다. OpenAI의 모델을 훈련시키기 위한 귀하의 콘텐츠 이용을 거부할 수 있는 방법에 대해서는 관련 설명(opens in a new window)을 확인하시기 바랍니다."
2. private endpoint
* Private endpoint는 네트워크 상에서 특정 리소스나 서비스에 대한 접근을 내부적으로 제한하는 연결 지점입니다.
* 일반적으로 클라우드 서비스나 데이터베이스와 같은 리소스에 외부의 인터넷 연결을 통한 접근을 방지하고, 사설 네트워크 내에서만 안전하게 연결될 수 있도록 설정됩니다.
* 이를 통해 보안이 강화되고, 데이터가 공용 인터넷을 통해 전송되지 않으므로 민감한 정보의 유출을 방지할 수 있습니다.

Azure OpenAI
* Azure OpenAI는 Microsoft Azure 플랫폼에서 제공하는 OpenAI의 인공지능 모델을 기반으로 한 서비스입니다.
* 이를 통해 기업과 개발자들은 OpenAI의 GPT(Generative Pre-trained Transformer)와 같은 고급 자연어 처리 모델을 Azure의 클라우드 환경에서 손쉽게 활용할 수 있습니다.
* Azure OpenAI는 텍스트 생성, 번역, 요약, 질문 응답 등 다양한 AI 기능을 제공하며, 사용자는 API를 통해 이러한 기능을 자신들의 애플리케이션에 통합할 수 있습니다. 또한, Microsoft의 보안 및 관리 기능이 결합되어 기업 환경에서도 안정적으로 활용할 수 있습니다.
3. 파인 튜닝
* 파인튜닝(fine-tuning)은 사전 훈련된 언어 모델을 특정 작업에 맞게 조정하는 과정을 말합니다.
* 파인튜닝은 모델이 더 정확하고 일관성 있는 결과를 생성하도록, 특정 도메인이나 응용 프로그램에 맞춰 추가적인 학습을 진행하는 과정입니다.
* 이를 통해 모델은 검색된 정보와 생성된 텍스트의 품질을 향상시키고, 더 높은 성능을 발휘할 수 있습니다.
* OpenAI에서는 다양한 모델에 대해 파인튜닝을 지원하며, 각 모델의 비용은 아래 링크와 같습니다.
링크 주소 : https://platform.openai.com/docs/guides/fine-tuning
예제 1)
# gpt 4o-mini가 효율적이다
# 과금이 되니 파인튜닝은 조심해서 사용하도록 한다
import json
import pandas as pd
from openai import OpenAI
예제 2)
# 질문과 답변할 사항을 적어줌
df = pd.DataFrame({
'questions':[
'12시 땡!',
'1지망 학교 떨어졌어',
'3박4일 놀러가고 싶다',
'PPL 심하네',
'SD카드 망가졌어',
'SD카드 안돼',
'SNS 맞팔 왜 안하지ㅠㅠ',
'SNS 시간낭비인 거 아는데 매일 하는 중',
'SNS 시간낭비인데 자꾸 보게됨',
'SNS보면 나만 빼고 다 행복해보여'],
'answers':[
'하루가 또 가네요',
'위로해 드립니다.',
'여행은 언제나 좋죠',
'눈살이 찌푸려지죠',
'다시 새로 사는 게 마음 편해요',
'다시 새로 사는 게 마음 편해요',
'잘 모르고 있을 수도 있어요',
'시간을 정하고 해보세요',
'시간을 정하고 해보세요',
'자랑하는 자리니까요'],
})
예제 3)
# top 5 추출
df.head()--->

예제 4)
# 원본 DataFrame(df)에서 'questions' 와 'answers' 를 선택하여
# 새로운 DataFrame(df_gpt)을 생성
df_gpt = df[['questions', 'answers']]
# 생성된 df_gpt DataFrame의 상위 5개 출력
df_gpt.head()--->

예제 5)
# df_gpt DataFrame의 열 이름을 'prompt'와 'completion'으로 변경합니다.
# 기존에는 'questions'와 'answers'라는 열 이름이었지만,
# 모델 학습이나 데이터 처리에 맞추어 더 의미 있는 이름으로 변경한 것입니다.
df_gpt.columns = ['prompt', 'completion']
# 상위 5개 출력
df_gpt.head()--->
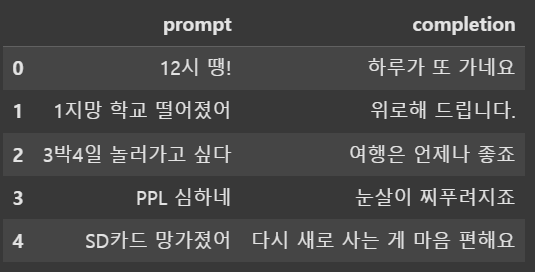
예제 6)
# df_gpt DataFrame의 각 행(row)을 순회하며, 각 행에 대해 대화 형식의 메시지 구조를 생성
formatted_data = [
{
'messages': [
# 시스템 메시지: 챗봇에게 "친절한 말동무" 역할을 수행하라는 초기 지시를 제공
{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'},
# 사용자 메시지: 각 행의 'prompt' 열 값을 메시지 내용으로 사용
{'role': 'user', 'content': row['prompt']},
# 어시스턴트 메시지: 각 행의 'completion' 열 값을 챗봇의 답변으로 사용
{'role': 'assistant', 'content': row['completion']}
]
}
# df_gpt DataFrame의 모든 행에 대해 위와 같은 구조의 딕셔너리를 생성
for _, row in df_gpt.iterrows()
]
예제 7)
# 각 항목은 대화 형식의 메시지 구조를 담고 있는 딕셔너리
# 각 entry의 내용을 콘솔에 출력하여 구조와 데이터를 확인
for entry in formatted_data:
print(entry)
--->
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': '12시 땡!'}, {'role': 'assistant', 'content': '하루가 또 가네요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': '1지망 학교 떨어졌어'}, {'role': 'assistant', 'content': '위로해 드립니다.'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': '3박4일 놀러가고 싶다'}, {'role': 'assistant', 'content': '여행은 언제나 좋죠'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'PPL 심하네'}, {'role': 'assistant', 'content': '눈살이 찌푸려지죠'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SD카드 망가졌어'}, {'role': 'assistant', 'content': '다시 새로 사는 게 마음 편해요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SD카드 안돼'}, {'role': 'assistant', 'content': '다시 새로 사는 게 마음 편해요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SNS 맞팔 왜 안하지ㅠㅠ'}, {'role': 'assistant', 'content': '잘 모르고 있을 수도 있어요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SNS 시간낭비인 거 아는데 매일 하는 중'}, {'role': 'assistant', 'content': '시간을 정하고 해보세요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SNS 시간낭비인데 자꾸 보게됨'}, {'role': 'assistant', 'content': '시간을 정하고 해보세요'}]}
{'messages': [{'role': 'system', 'content': '너는 나와 말동무를 해주는 친절한 챗봇이야'}, {'role': 'user', 'content': 'SNS보면 나만 빼고 다 행복해보여'}, {'role': 'assistant', 'content': '자랑하는 자리니까요'}]}
jsonl
* .jsonl (JSON Lines)은 JSON 포맷의 변형으로, 여러 개의 JSON 객체를 한 파일 내에서 각 줄마다 구분하여 저장하는 방식입니다.
* 이 형식은 각 줄에 하나의 JSON 객체를 포함하므로 대용량 데이터를 처리할 때 유용하며, 스트리밍 데이터나 로그 데이터를 다룰 때 주로 사용됩니다.
* 각 줄은 독립적인 JSON 객체로 구성되어 있기 때문에, 파일을 한 줄씩 읽으면서 데이터를 처리할 수 있습니다.
예제 1)
# 'training_data.jsonl' 파일을 쓰기 모드('w')로 연다
# 이 파일은 JSON Lines 형식으로 저장되어, 각 줄이 하나의 JSON 객체를 나타냄
with open('training_data.jsonl', 'w') as f:
# formatted_data 리스트의 각 entry(딕셔너리)를 순회
for entry in formatted_data:
# 각 entry를 JSON 문자열로 변환한 후, 줄바꿈 문자('\n')를 추가하여 파일에 기록
f.write(json.dumps(entry) + '\n')
예제 2)
# OpenAI API 키를 사용하여 OpenAI 클라이언트 객체를 생성
# 이 클라이언트를 통해 API 호출
client = OpenAI(
api_key='자기 API 키'
)
# 'training_data.jsonl' 파일을 바이너리 읽기 모드('rb')로 열고,
# 파인튜닝(fine-tune)을 목적으로 파일을 업로드
client.files.create(
file=open('training_data.jsonl', 'rb'),
purpose='fine-tune'
)
예제 3)
# client.fine_tuning.jobs.create() 함수를 사용하여 파인튜닝 작업을 생성
job_create = client.fine_tuning.jobs.create(
# 업로드된 학습 데이터 파일의 ID를 지정
training_file='file-파일 아이디',
# 파인튜닝할 모델의 이름을 지정
model='gpt-4o-mini-2024-07-18'
)
# 생성된 파인튜닝 작업의 정보를 출력하여 작업의 상태나 ID 등 세부 정보를 확인
job_create
예제 4)
# 파인튜닝 job 리스트 10개 나열
res = client.fine_tuning.jobs.list(limit=10)
res
예제 5)
# 파인튜닝 상태 확인
client.fine_tuning.jobs.retrieve('아이디값')
--->
FineTuningJob(iㅇㄴㅁㅇㄴㅁ)ㅇ...생략
예제 6)
# 여기서 과금되니 한번 돌려보실려면 돌려보세요
completion = client.chat.completions.create(
model = 'ft:자기 모델',
messages = [
{'role':'system','content':'너는 나와 말동무를 해주는 친절한 챗봇이야'},
{'role':'user', 'content':'SNS 맞팔 왜 안하지ㅠㅠ'}
]
)
completion.choices[0].message
-->
ChatCompletionMessage(content='잘 모르고 있을 수도 있어요', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None)
4. RAG
* RAG(Retrieval-Augmented Generation)는 정보를 검색하여 이를 기반으로 텍스트를 생성하는 자연어 처리 모델입니다.
* 이 모델은 두 가지 주요 구성 요소로 이루어져 있습니다: 검색 모듈과 생성 모듈. 첫 번째로, 사용자가 입력한 질문이나 요청에 대해 관련된 정보를 외부 데이터베이스나 문서에서 검색한 후, 그 정보를 바탕으로 텍스트를 생성하는 방식입니다.
* 이렇게 검색된 정보를 활용하여 보다 정확하고 신뢰성 있는 응답을 생성할 수 있으며, 특히 복잡한 질문에 대해서는 사전 지식이 부족한 모델보다 유용한 결과를 제공할 수 있습니다.
* RAG는 정보 검색과 생성 모델을 결합하여, 더 나은 성능을 발휘할 수 있는 방식입니다.

1. 검색 단계 (Retrieval)
* 사용자가 질문을 입력하면, RAG는 먼저 이 질문에 관련된 정보를 검색합니다.
* 이 정보는 모델이 사전에 학습한 외부 데이터베이스나 문서 집합에서 검색됩니다. 예를 들어, 모델이 인터넷이나 특정 문서 집합을 검색하여 질문에 대한 관련 정보를 찾아냅니다.
* 검색 모듈은 이 데이터를 가장 관련성이 높은 부분을 선택하고, 해당 정보들을 "컨텍스트"로 모델에게 전달합니다.
2. 생성 단계 (Generation)
* 검색된 정보가 준비되면, 생성 모듈이 이를 바탕으로 응답을 생성합니다.
* 이 생성 단계에서 모델은 질문과 함께 검색된 정보를 이용하여 자연스러운 문장을 만듭니다. 즉, 질문에 대한 직접적인 답을 주기 위해 필요한 정보를 잘 조합하여 자연어로 출력합니다.
* 여기서 중요한 점은, 생성 모듈이 검색된 정보만을 이용해 답을 생성하므로, 사실관계에 기반한 정확한 답변을 만들 수 있습니다.
5. 정킹
* 정킹(Chunking)은 자연어 처리(NLP)에서 문장에서 의미 있는 단위를 그룹으로 묶는 과정입니다.
* 주로 품사 태깅을 기반으로 명사구(NP), 동사구(VP) 등의 구(Chunk)를 추출하는 데 사용됩니다.
* 예를 들어, "빠른 여우가 점프했다"라는 문장에서 "빠른 여우"를 하나의 명사구로 정킹할 수 있습니다.
* 이를 통해 문장의 구조를 더 잘 이해하고, 정보 추출, 개체명 인식(NER) 등 다양한 NLP 작업에서 활용할 수 있습니다.
예시 1)
text = """Content filters work by identifying online communication that needs to be filtered such as website URLs, emails, or SMS. \
By categorizing the form of communication based on filters set by the user the system \
can compare the categorized online communication to a list of restricted content. Based on the comparison \n\n \
the system decides to allow or block access the users access to the content. Content filtering can be performed on different levels. \
Using email filters, web filters, or messaging filters you can analyze the content of emails, web pages, \
or messages, blocking or allowing them based on specific criteria, such as keywords or categories.\
to certain websites or applications based on specific policies set by an organization."""
예시 2)
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
예시 3)
chunk_size = 26 # 청크 사이즈(길이)
chunk_overlap = 4 # 각 청크가 겹치는 부분(중복되는 글자 수)
예시 4)
# RecursiveCharacterTextSplitter는 텍스트를 재귀적으로 분할
# 즉, 먼저 문장 단위로, 그 다음 문단 단위로, 그리고 최종적으로 글자 단위로 나눌 수 있으며,
# 각 분할 단계에서 최대한 원래 문장의 의미를 유지
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # 한 청크(chunk)의 최대 크기를 지정합니다.
chunk_overlap=chunk_overlap # 각 청크 사이에 겹칠 글자 수를 지정합니다.
)
# CharacterTextSplitter는 텍스트를 단순하게 지정된 크기로 잘라냅니다.
# 여기서는 단순히 텍스트를 주어진 chunk_size로 분할하며,
# 분할된 청크들 사이에 일정 부분이 중복되도록 chunk_overlap을 유지
# separator 파라미터는 분할할 때 기준이 되는 구분자(여기서는 공백)를 지정
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size, # 청크의 최대 크기를 지정
chunk_overlap=chunk_overlap, # 청크 간 겹칠 글자 수를 지정
separator=' ' # 텍스트를 분할할 때 사용할 구분자를 공백으로 지정
)
예시 5)
# r_splitter 객체를 사용하여 주어진 텍스트를 지정된 크기(chunk_size)와 겹침(chunk_overlap)을 고려해 분할
# 이 메소드는 텍스트를 재귀적으로 분할하며, 가능한 한 원래 문장의 의미를 유지
r_splitter.split_text(text)
--->
['Content filters work by',
'by identifying online',
'communication that needs',
'to be filtered such as',
'as website URLs, emails,',
'or SMS. By categorizing',
'the form of communication',
'based on filters set by',
'by the user the system',
'can compare the',
'the categorized online',
'communication to a list',
'of restricted content.',
'Based on the comparison',
'the system decides to'
]
예시 6)
r_splitter.split_text("인공지능은 데이터를 학습하여 패턴을 찾고 예측하는 기술이다")
--->
['인공지능은 데이터를 학습하여 패턴을 찾고', '찾고 예측하는 기술이다']
예시 7)
c_splitter.split_text(text)
-->
['Content filters work by',
'by identifying online',
'communication that needs',
'to be filtered such as',
'as website URLs, emails,',
'or SMS. By categorizing',
'the form of communication',
'based on filters set by',
'by the user the system can',
'can compare the',
'the categorized online',
'communication to a list of',
'of restricted content.',
'Based on the comparison',
'the system decides to',
'to allow or block access'
]
예시 8)
c_splitter.split_text('인공지능은 데이터를 학습하여 패턴을 찾고 예측하는 기술이다')
--->
['인공지능은 데이터를 학습하여 패턴을 찾고', '찾고 예측하는 기술이다']
예시 9)
# 청크(chunk)의 최대 크기를 2로,
# 각 청크가 겹치는 부분을 1로 지정
chunk_size = 2
chunk_overlap = 1
# RecursiveCharacterTextSplitter 인스턴스를 생성
# 이 객체는 텍스트를 재귀적으로 분할하는데,
# 가능한 한 문장의 의미를 유지하면서,
# 먼저 문장, 그 후 문단, 마지막으로 글자 단위로 나누려고 시도
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# 'text' 변수에 저장된 텍스트를 분할
# 이 메서드는 지정된 청크 크기와 겹침을 고려하여 텍스트를 여러 부분으로 나눔
r_splitter.split_text(text)
예시 10)
# langchain-community 패키지 설치
!pip install langchain-community
예시 11)
from langchain.document_loaders import WebBaseLoader
예시 12)
loader = WebBaseLoader('https://darktrace.com/cyber-ai-glossary/content-filtering')
docs = loader.load()
docs
--->
[Document(metadata={'source': 'https://darktrace.com/cyber-ai-glossary/content-filtering', 'title': 'What is Content Filtering? Explanation & Applications', 'description': 'Explore why screening and restricting objectionable content is crucial for a safe online environment. Learn how to filter your emails and web searches here.', 'language': 'en'}, page_content='What is Content Filtering? Explanation & Applications\n\n\n\n\n\n\n\n\n\n\nDarktrace has completed the acquisition of Cado Security.Read the announcement press release here\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nPlatformProducts\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ NETWORKProactive protection\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ EMAILCloud-native AI security\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ CLOUDComplete cloud coverage\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ OTComprehensive risk management\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ IDENTITY360° user protection\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ ENDPOINTCoverage for every device\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ Proactive Exposure Management\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ Attack Surface Management\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n/ Incident Readiness & Recov
예시 13)
# docs 리스트의 첫 번째 문서에서 page_content 속성의 앞 500자만 추출하여 출력
# 이 코드는 해당 문서의 일부 내용을 미리보기 위해 사용
print(docs[0].page_content[:500])
--->
What is Content Filtering? Explanation & Applications
예시 1)
PDF 파일을 불러오는 예시를 해보겠습니다.
from langchain.document_loaders import PyPDFLoader
예시 2)
# PyPDFLoader 클래스를 사용하여 '1130_ChatGPT API를 활용한 서비스 개발.pdf' 파일을 불러옴.
loader = PyPDFLoader('1130_ChatGPT API를 활용한 서비스 개발.pdf')
# 불러온 PDF 파일의 모든 데이터 저장
pages = loader.load()
# 불러온 페이지의 총 개수를 출력하여, 파일 내 페이지 수를 확인
print(len(pages))
-->
88
예시 3)
# pages 리스트의 첫 번째 페이지에서 page_content 속성의 처음 500자를 출력
# 이 코드는 해당 페이지의 내용을 일부 미리보기 위해 사용
print(pages[0].page_content[0:500])
--->
1
ChatGPT API를 활용한 서비스 개발
OpenAPI 활용
https://chat.openai.com/
OpenAI Chat GPT
* 긴 문장이나 단락을 유지함. 문장 중간에서 끊기지 않도록 일부 내용을 다음 청크에도 포함
* GPT 같은 모델이 긴 문서를 이해할 때 문맥이 끊기면 성능이 떨어지기 때문에 일부 중요한 단어가 잘리지 않도록 적절한 Overlap 적용(보통 chunk_size의 문장 10~20%를 선택)
'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 15. RAG기반 챗봇 만들기 (6) | 2025.02.19 |
|---|---|
| 14. 벡터 데이터베이스 (4) | 2025.02.19 |
| 12. 사전 학습된 언어 모델(PML) (4) | 2025.02.13 |
| 11. 트랜스포머 (2) | 2025.02.12 |
| 10. 어텐션 메커니즘 (1) | 2025.02.12 |