2025. 2. 6. 01:26ㆍ자연어 처리/자연어 처리
RNN을 보기 전에 CNN Text Classification을 알아보자.
RNN은 CNN Text Classification을 먼저 구현해 본 후 보면 이해가 될 것이다.
1. CNN( "Convolutional Neural Networks)
* CNN은 컴퓨터 비전 분야를 위해 개발되었으며, 대중적으로 사용되고 있는 가장 보편화된 이미지 처리 알고리즘입니다.
* CNN(Convolutional Neural Network)을 사용하여 텍스트 데이터를 분류하는 방법을 의미합니다.
* 원래 CNN은 이미지 처리에 특화된 모델이지만, 자연어 처리(NLP)에서도 강력한 성능을 발휘할 수 있어. 특히, 문장의 패턴을 학습하는 데 효과적이라서 감성 분석(Sentiment Analysis), 뉴스 카테고리 분류, 스팸 탐지 등 여러 텍스트 분류 문제에서 사용됩니다.
* CNN은 가중치를 갖는 필터를 사용하기 때문에 개별 픽셀에 대한 가중치를 고려하지 않아도 됩니다.
* 따라서 CNN을 사용하는 모델은 파라미터를 효율적으로 사용하여 매우 큰 차원의 이미지를 처리할 수 있습니다.
예제 1)
import urllib.request # 웹에서 데이터를 다운로드할 수 있도록 도와주는 라이브러리
import pandas as pd # 데이터 분석 및 조작을 위한 라이브러리 (데이터프레임 사용 가능)
import numpy as np # 수학적 연산 및 배열 처리를 위한 라이브러리
import matplotlib.pyplot as plt # 데이터 시각화를 위한 라이브러리
import torch # PyTorch 라이브러리 (딥러닝을 위한 프레임워크)
import torch.nn as nn # PyTorch의 신경망 관련 모듈
import torch.optim as optim # PyTorch의 최적화 알고리즘 모듈
import torch.nn.functional as F # PyTorch의 다양한 신경망 함수들
from copy import deepcopy # 객체를 깊은 복사(deep copy)하기 위한 라이브러리
from torch.utils.data import Dataset, DataLoader # PyTorch의 데이터 처리 및 배치(batch) 로딩을 위한 유틸리티
from tqdm.auto import tqdm # 반복문 진행 상태를 시각적으로 보여주는 라이브러리 (진행률 표시)
예제 2)
# 'ratings_train.txt, 'ratings_test.txt 데이터 가져옴
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='ratings_train.txt' )
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='ratings_test.txt' )
예제 3)
# ratings_train.txt 파일을 train_dataset에 저장
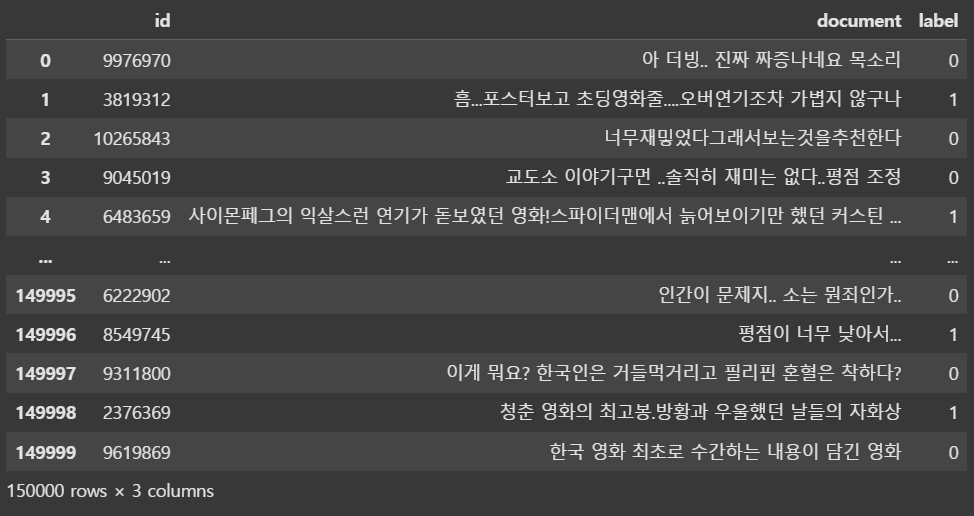
train_dataset = pd.read_table('ratings_train.txt')
train_dataset--->
예제 4)
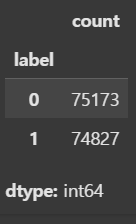
# 긍정 리뷰와 부정 리뷰의 개수를 세어 반환
train_dataset['label'].value_counts() # 0: negative, 1: positive-->
예제 5)
sum(train_dataset['document'].isnull()) # 결측치 확인
-->
5
예제 6)
train_dataset = train_dataset[~train_dataset['document'].isnull()] # 결측치 제거
예제 7)
sum(train_dataset['document'].isnull()) # 결측치 제거 후 확인
-->
0
예제 8)
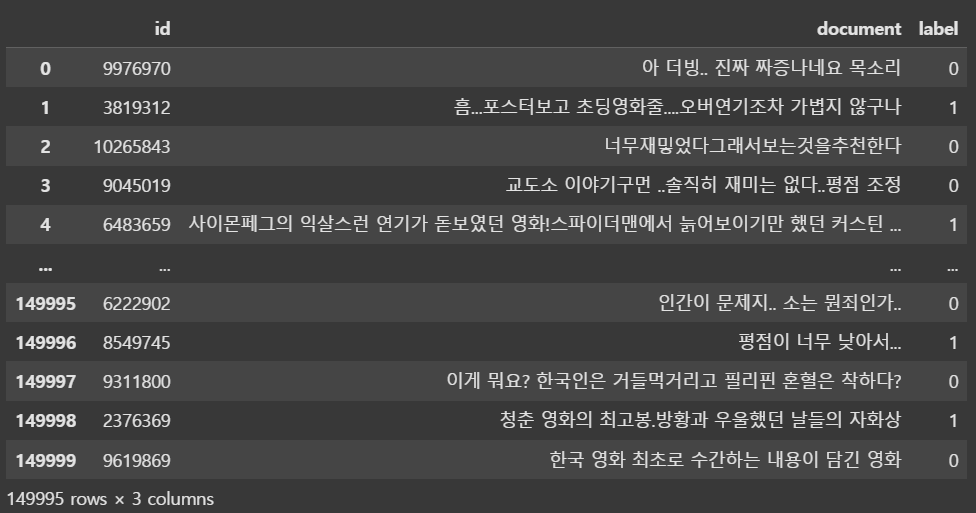
train_dataset # 결측치 제거 후 확인-->
예제 9)
# 'document' 영화 리뷰 텍스트 선택 후 열의 첫 번째(0번째) 리뷰를 가져옴
# 가져온 리뷰 문장을 공백(스페이스) 기준으로 나누어 리스트로 변환
train_dataset['document'].iloc[0].split()
-->
['아', '더빙..', '진짜', '짜증나네요', '목소리']
예제 10)
vocab = set() # 중복을 허용하지 않는 집합(set) 생성
for doc in train_dataset['document']: # 열의 각 리뷰 문장을 순회
for token in doc.split(): # 리뷰 문장을 공백 기준으로 나누어 단어(토큰)로 변환
vocab.add(token) # 단어(토큰)를 vocab 집합(set)에 추가
예제 11)
len(vocab) #vocab 문장 길이
-->
357862
예제 12)
# 단어 빈도수 구하기
vocab_cnt_dict = {} # 단어별 등장 횟수를 생성
for doc in train_dataset['document']: # 'document' 열의 각 리뷰 문장을 하나씩 가져옴
for token in doc.split(): # 문장을 공백 기준으로 나누어 단어(토큰) 리스트로 변환
if token not in vocab_cnt_dict: # 단어가 딕셔너리에 없으면 초기값 0으로 설정
vocab_cnt_dict[token] = 0
vocab_cnt_dict[token] += 1 # 해당 단어의 등장 횟수를 1 증가
예제 13)
# 단어 빈도수를 저장한 딕셔너리(vocab_cnt_dict)의 항목을 리스트로 변환
# vocab_cnt_dict.items()는 (단어, 등장 횟수) 형태의 튜플을 반환
# 리스트 컴프리헨션을 사용하여 (단어, 등장 횟수) 튜플 리스트를 생성
vocab_cnt_list = [(token, cnt) for token, cnt in vocab_cnt_dict.items()]
vocab_cnt_list[:10] # 리스트의 첫 10개 요소(단어와 해당 단어의 등장 횟수)를 확인
-->
[('아', 1204),
('더빙..', 2),
('진짜', 5929),
('짜증나네요', 10),
('목소리', 99),
('흠...포스터보고', 1),
('초딩영화줄....오버연기조차', 1),
('가볍지', 17),
('않구나', 2),
('너무재밓었다그래서보는것을추천한다', 1)]
예제 14)
# 단어 빈도 리스트를 등장 횟수 기준으로 내림차순 정렬
# key=lambda top: top[1]: 각 튜플의 두 번째 요소(단어 등장 횟수)를 기준으로 정렬
top_vocabs = sorted(vocab_cnt_list, key=lambda top: top[1], reverse=True)
top_vocabs[:10] # 상위 10개 단어 출력
-->
[('영화', 10825),
('너무', 8239),
('정말', 7791),
('진짜', 5929),
('이', 5059),
('영화.', 3598),
('왜', 3285),
('더', 3260),
('이런', 3249),
('그냥', 3237)]
예제 15)
cnts = [cnt for _, cnt in top_vocabs] # 리스트에서 단어 등장 횟수만 추출하여 cnts 리스트를 생성
np.mean(cnts) # 단어 등장 횟수들의 평균값(Mean)을 계산
-->
3.1792590439890236
예제 16)
sum(np.array(cnts) >= 2) # 등장 횟수가 2 이상인 단어의 개수를 계산하는 역할
-->
73090
예제 17)
n_vocab = sum(np.array(cnts) >= 2) # 등장 횟수가 2 이상인 단어의 갯수 계산을 n_vocab에 저장
예제 18)
# 상위 n_vocab개의 단어만 선택하여 새로운 리스트 생성하여 top_vocabs_truncated 에 저장하여
# 가장 자주 등장한 단어 n_vocab개를 top_vocabs_truncated에 저장
top_vocabs_truncated = top_vocabs[:n_vocab]
# 가장 자주 등장한 단어 리스트에서 상위 10개를 확인
top_vocabs_truncated[:10]
--->
[('영화', 10825),
('너무', 8239),
('정말', 7791),
('진짜', 5929),
('이', 5059),
('영화.', 3598),
('왜', 3285),
('더', 3260),
('이런', 3249),
('그냥', 3237)]
예제 19)
# top_vocabs_truncated 리스트에서 단어(token)만 추출하여 새로운 리스트 생성
# top_vocabs_truncated 리스트의 각 요소는 (단어, 빈도수) 형태의 튜플
vocabs = [token for token, _ in top_vocabs_truncated]
# 가장 많이 등장한 단어 리스트에서 상위 10개 단어만 출력
vocabs[:10]
-->
['영화', '너무', '정말', '진짜', '이', '영화.', '왜', '더', '이런', '그냥']
예제 20)
pad_token = '[PAD]' # 패딩(Padding) 토큰 정의 (고정된 길이로 맞출 때 사용)
unk_token = '[UNK]' # 미등록(Unknown) 단어 토큰 정의 (어휘 사전에 없는 단어 처리)
vocabs.insert(0, pad_token)
vocabs.insert(1, unk_token)
예제 21)
# 가장 많이 등장한 단어 리스트에서 상위 10개 단어만 출력
vocabs[:10]
-->
['[PAD]', '[UNK]', '영화', '너무', '정말', '진짜', '이', '영화.', '왜', '더']
예제 22)
# idx_to_token 리스트 생성 (단어 인덱스를 통해 단어를 찾을 수 있도록 함)
idx_to_token = vocabs
# token_to_idx 딕셔너리 생성 (단어를 인덱스로 변환할 수 있도록 함)
# enumerate(idx_to_token): 단어 리스트에서 (인덱스, 단어) 쌍을 생성히여 {단어: 인덱스} 형태로 만듦
token_to_idx = {token: i for i, token in enumerate(idx_to_token)}
예제 23)
# vocabs: 단어 리스트 (단어장)
# use_padding: 패딩 사용 여부 (기본값: True)
# max_padding: 패딩을 적용할 최대 토큰 길이 (기본값: 64)
# pad_token: 패딩을 위한 토큰 (기본값: '[PAD]')
# unk_token: 사전에 없는 단어를 위한 토큰 (기본값: '[UNK]')
class Tokenizer:
def __init__(self, vocabs, use_padding=True, max_padding=64, pad_token='[PAD]', unk_token='[UNK]'):
self.idx_to_token = vocabs # 인덱스를 단어로 변환하는 리스트
self.token_to_idx = {token: i for i, token in enumerate(self.idx_to_token)}
# -> 단어를 인덱스로 변환하는 딕셔너리 생성 {단어: 인덱스}
self.use_padding = use_padding # 패딩 사용 여부 설정
self.max_padding = max_padding # 최대 문장 길이 설정
self.pad_token = pad_token # 패딩 토큰 설정
self.unk_token = unk_token # 미등록 단어 토큰 설정
self.unk_token_idx = self.token_to_idx[self.unk_token] # '[UNK]' 토큰의 인덱스 저장
self.pad_token_idx = self.token_to_idx[self.pad_token] # '[PAD]' 토큰의 인덱스 저장
def __call__(self, x: str):
"""
문자열(문장)을 토큰 ID 리스트로 변환하는 메서드
:param x: 입력 문장 (문자열)
:return: 변환된 토큰 ID 리스트 (패딩 적용 가능)
"""
token_ids = [] # 변환된 토큰 ID를 저장할 리스트
token_list = x.split() # 입력 문장을 공백 기준으로 단어 리스트로 변환
# 각 단어를 토큰 인덱스로 변환
for token in token_list:
if token in self.token_to_idx:
token_idx = self.token_to_idx[token] # 사전에 있는 단어는 해당 인덱스를 사용
else:
token_idx = self.unk_token_idx # 사전에 없는 단어는 '[UNK]'의 인덱스를 사용
token_ids.append(token_idx) # 변환된 토큰 ID를 리스트에 추가
# 패딩 적용
if self.use_padding:
token_ids = token_ids[:self.max_padding] # 최대 길이 초과 시 잘라내기
n_pads = self.max_padding - len(token_ids) # 필요한 패딩 개수 계산
token_ids = token_ids + [self.pad_token_idx] * n_pads # 패딩 토큰을 추가하여 길이를 맞춤
return token_ids
예제 24)
tokenizer = Tokenizer(vocabs, use_padding=False) # Tokenizer 객체를 생성하면서 패딩을 사용하지 않도록 설정
예제 25)
sample = train_dataset['document'].iloc[0] # 훈련 데이터셋에서 첫 번째 문장을 가져옴
print(sample)
-->
아 더빙.. 진짜 짜증나네요 목소리
예제 26)
tokenizer(sample) # sample 문자열(첫 번째 리뷰 문장)을 토큰 ID 리스트로 변환
-->
[51, 42637, 5, 10485, 1064]
예제 27)
token_length_list = [] # 각 문장의 토큰 개수를 저장할 리스트 생성
for sample in train_dataset['document']: # 데이터셋의 모든 문장을 저장
token_length_list.append(len(tokenizer(sample))) # 문장을 토큰화한 후 길이(토큰 개수) 저장
예제 28)
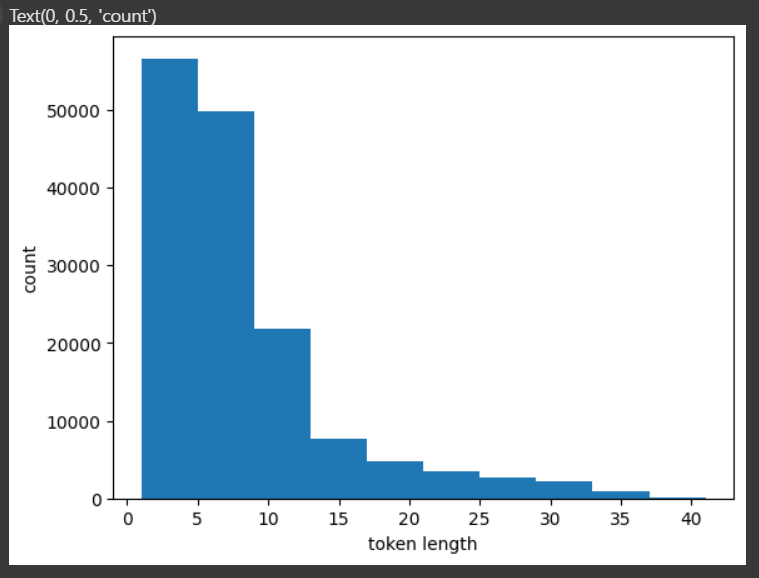
import matplotlib.pyplot as plt
plt.hist(token_length_list) # 히스토그램 생성
plt.xlabel('token length') # x축: 토큰 길이
plt.ylabel('count') # y축: 해당 길이를 가진 문장 개수
plt.show() # 그래프 출력-->
예제 29)
# token_length_list에서 최대값 찾기
max(token_length_list)
-->
41
예제 30)
tokenizer = Tokenizer(vocabs, use_padding=True, max_padding=50) # Tokenizer 객체 생성 (패딩 적용, max_padding=50)
print(tokenizer(sample)) # 토큰화 후 출력
-->
[201, 2, 3635, 1, 121, 1946, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
예제 31)
train_dataset-->
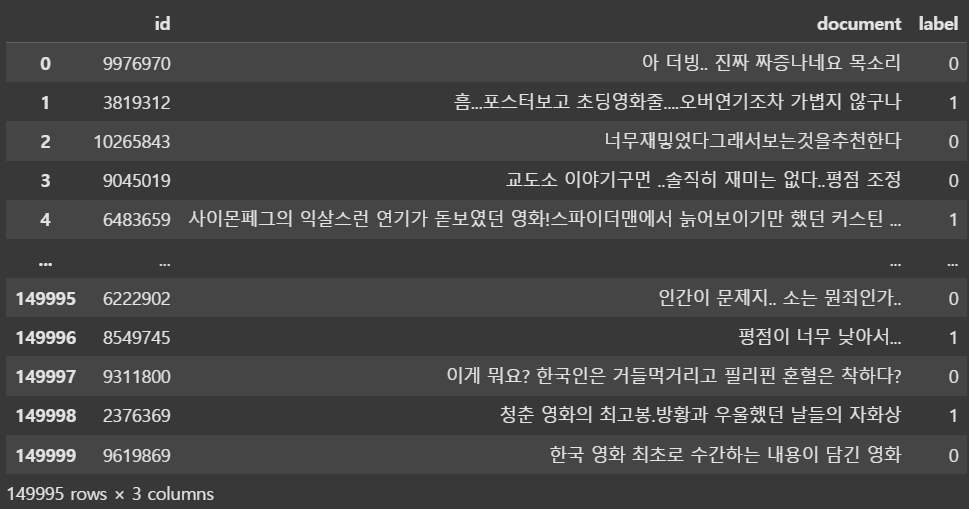
예제 32)
train_valid_dataset = pd.read_table('ratings_train.txt') # 훈련 및 검증 데이터셋 로드
test_dataset = pd.read_table('ratings_test.txt') # 테스트 데이터셋 로드
print(f'train, valid samples: {len(train_valid_dataset)}')
print(f'test samples: {len(test_dataset)}')
-->
train, valid samples: 150000
test samples: 50000
예제 33)
train_valid_dataset.head()--->

예제 34)
import pandas as pd
# ratings_train.txt 파일 train_valid_dataset에 저장
train_valid_dataset = pd.read_table('ratings_train.txt')
# 데이터 전체를 무작위로 섞기
train_valid_dataset = train_valid_dataset.sample(frac=1.)
# 데이터 확인
train_valid_dataset.head()-->

예제 35)
# 훈련 데이터 비율 설정 (80%를 훈련 데이터로 사용)
train_ratio = 0.8
# 훈련 데이터 개수 계산 (전체 데이터셋 크기의 80%)
# len(train_valid_dataset): 전체 데이터 개수
# train_ratio(0.8)를 곱하여 훈련 데이터 개수를 계산
# int()를 사용하여 정수형으로 변환
n_train = int(len(train_valid_dataset) * train_ratio)
# 훈련 데이터 (train_df) 생성: 앞부분 n_train 개 샘플 사용
# 데이터셋의 처음 n_train개를 훈련 데이터로 설정
train_df = train_valid_dataset[:n_train]
# 검증 데이터 (valid_df) 생성: n_train 이후의 나머지 샘플 사용
# 데이터셋의 n_train 번째 이후 샘플을 검증 데이터로 설정
valid_df = train_valid_dataset[n_train:]
# 테스트 데이터 (test_df)는 기존 테스트 데이터셋 그대로 사용
test_df = test_dataset
# 각 데이터셋의 샘플 개수 출력
print(f'train samples: {len(train_df)}') # 훈련 데이터 개수 출력
print(f'valid samples: {len(valid_df)}') # 검증 데이터 개수 출력
print(f'test samples: {len(test_df)}') # 테스트 데이터 개수 출력
-->
train samples: 60000
valid samples: 15000
test samples: 25000
예제 36)
from torch.utils.data import Dataset # PyTorch의 Dataset 클래스 사용
class NSMCDataset(Dataset):
def __init__(self, data_df, tokenizer=None):
"""
NSMC 데이터셋을 PyTorch의 Dataset 형식으로 변환하는 클래스
:param data_df: 데이터셋 (Pandas DataFrame)
:param tokenizer: 토큰화 함수 (기본값: None)
"""
self.data_df = data_df # 데이터셋 저장 (DataFrame 형태)
self.tokenizer = tokenizer # 토크나이저 (문장을 숫자로 변환)
def __len__(self):
"""
데이터셋의 샘플 개수를 반환하는 메서드
:return: 데이터프레임의 길이 (샘플 개수)
"""
return len(self.data_df)
def __getitem__(self, idx):
"""
인덱스(idx)에 해당하는 샘플을 반환하는 메서드
:param idx: 가져올 데이터의 인덱스
:return: 토큰화된 문장과 라벨을 포함한 딕셔너리 (sample)
"""
sample_raw = self.data_df.iloc[idx] # 데이터프레임에서 idx번째 샘플 가져오기
sample = {} # 반환할 샘플을 저장할 딕셔너리 생성
# 'document' 열에서 리뷰 텍스트 가져오기 (문자열로 변환)
sample['doc'] = str(sample_raw['document'])
# 'label' 열에서 라벨(0: 부정, 1: 긍정) 가져오기 (정수형 변환)
sample['label'] = int(sample_raw['label'])
# 토크나이저가 지정된 경우, 문장을 토큰화하여 'doc_ids' 키에 저장
if self.tokenizer is not None:
sample['doc_ids'] = self.tokenizer(sample['doc'])
return sample # 샘플 반환
예제 37)
# NSMCDataset 클래스를 사용하여 PyTorch Dataset 객체 생성 (훈련, 검증, 테스트 데이터셋)
train_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer) # 훈련 데이터셋
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer) # 검증 데이터셋
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer) # 테스트 데이터셋
# 훈련 데이터셋의 첫 번째 샘플 출력
# 첫 번째 샘플(리뷰 텍스트, 라벨, 토큰화된 ID 리스트)을 출력
print(train_dataset[0])
--->
{'doc': '배우들 연기도 잘하고 재미있어요!!!ㅋㅋ만보때가 제일 재미있었구요^^', 'label': 1, 'doc_ids': [157, 104, 1709, 1, 114, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
예제 38)
def collate_fn(batch):
"""
DataLoader에서 배치 데이터를 정리하는 함수 (collate function)
:param batch: DataLoader에서 제공하는 미니배치 (샘플들의 리스트)
:return: 정리된 배치 데이터 (딕셔너리 형태)
"""
# 배치 내 첫 번째 샘플에서 키 목록을 추출 (예: 'doc', 'label', 'doc_ids')
keys = [key for key in batch[0].keys()]
# 각 키별 데이터를 저장할 빈 딕셔너리 생성
data = {key: [] for key in keys}
# 배치 내 모든 샘플을 순회하면서 데이터를 분류하여 저장
for item in batch:
for key in keys:
data[key].append(item[key]) # 해당 키의 데이터를 리스트에 추가
return data
예제 39)
from torch.utils.data import DataLoader
# 훈련 데이터 로더 생성 (데이터를 랜덤하게 섞어 배치 단위로 로드)
train_dataloader = DataLoader(
train_dataset, # 훈련 데이터셋
batch_size=128, # 배치 크기 (한 번에 128개 샘플을 로드)
collate_fn=collate_fn, # 배치 데이터를 정리하는 함수 (문장을 토큰 ID 리스트로 변환)
shuffle=True # 데이터를 랜덤하게 섞음 (훈련 데이터에서는 필수)
)
# 검증 데이터 로더 생성
valid_dataloader = DataLoader(
valid_dataset, # 검증 데이터셋
batch_size=128, # 배치 크기
collate_fn=collate_fn, # 배치 데이터를 정리하는 함수
shuffle=False # 검증 데이터는 섞지 않음
)
# 테스트 데이터 로더 생성
test_dataloader = DataLoader(
test_dataset, # 테스트 데이터셋
batch_size=128, # 배치 크기
collate_fn=collate_fn, # 배치 데이터를 정리하는 함수
shuffle=False # 테스트 데이터도 섞지 않음
)
예제 40)
# test_dataloader에서 첫 번째 배치 가져오기
sample = next(iter(test_dataloader))
# 배치 데이터의 키 확인
sample.keys()
-->
dict_keys(['doc', 'label', 'doc_ids'])
예제 41)
sample['doc'][3]
-->
꼭 보면... 알수있다
예제 42)
# 네 번째 샘플의 'doc_ids' 출력
print(sample['doc_ids'][3])
-->
[53, 37027, 14316, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
예제 43)
class SentenceCNN(nn.Module):
# 여러 개의 윈도우 크기를 사용하면, 짧은 문장기과 긴 문장에서 모두 적절한
# 특징을 추출할 수 있음
# https://arxiv.org/pdf/1408.5882
def __init__(self, vocab_size, embed_dim, word_win_size=[3, 5, 7]):
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.word_win_size = word_win_size
self.conv_list = nn.ModuleList(
[nn.Conv2d(1, 1, kernel_size=(w, embed_dim)) for w in self.word_win_size]
)
# 단어 임베딩 레이어: 단어를 embed_dim 차원의 벡터로 변환
# padding_idx=0 -> 패딩된 단어(인덱스 0)를 임베딩에서 무시
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.output_dim = len(self.word_win_size)
def forward(self, X):
batch_size, seq_len = X.size()
X = self.embeddings(X) # batch_size * seq_len * embed_dim
# 입력 데이터 X의 배치 크기(batch_size)와 문장 길이(seq_len)를 저장 후
# 원래크기: (batch_size, seq_len, embed_dim) -> (batch_size, 1, seq_len, embed_dim)
# 1은 채널(channel) 차원 (텍스트 데이터를 이미지처럼 처리하기 위해 추가)
X = X.view(batch_size, 1, seq_len, self.embed_dim)
# CNN 필터(합성곱 연산)를 적용하고, ReLU 활성화 함수를 사용하여 비선형성을 추가
C = [F.relu(conv(X)) for conv in self.conv_list]
# 맥스 풀링 적용: 전체 필터 크기를 대상으로 맥스 풀링 수행(최대값만 만김)
# squeeze(): 불필요한 차원 제거
# CNN 필터별 특징 벡터를 합쳐서 하나의 텐서로 변환
C_hat = torch.stack([F.max_pool2d(c, c.size()[2:]).squeeze() for c in C], dim=1)
return C_hat
예제 44)
import torch.nn as nn # PyTorch의 신경망 모듈
class Classifier(nn.Module):
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
"""
분류 모델을 정의하는 PyTorch 모듈
:param sr_model: 문장을 벡터로 변환하는 신경망 모델 (Sentence Representation Model)
:param output_dim: 최종 출력 차원 (예: 이진 분류의 경우 2)
:param vocab_size: 단어 사전 크기 (임베딩 레이어에서 사용)
:param embed_dim: 단어 임베딩 차원 (임베딩 벡터 크기)
:param kwargs: sr_model에 전달할 추가 매개변수
"""
super().__init__() # 부모 클래스(nn.Module) 초기화
# 문장을 벡터로 변환하는 기본 모델 (예: LSTM, CNN, Transformer 등)
self.sr_model = sr_model(vocab_size=vocab_size, embed_dim=embed_dim, **kwargs)
# sr_model이 출력하는 차원을 가져옴 (sr_model에서 사전에 정의해야 함)
self.input_dim = self.sr_model.output_dim
# 최종 출력 차원 (분류할 클래스 개수)
self.output_dim = output_dim
# Fully Connected Layer (출력 벡터를 최종 클래스로 변환)
self.fc = nn.Linear(self.input_dim, self.output_dim)
def forward(self, x):
"""
순전파(forward) 과정 정의
:param x: 입력 텐서 (토큰화된 문장의 ID 리스트)
:return: 최종 분류 결과 (출력 차원 = output_dim)
"""
sentence_representation = self.sr_model(x) # 입력을 sr_model에 통과시켜 문장 벡터로 변환
output = self.fc(sentence_representation) # 문장 벡터를 분류 레이어(FC)에 전달하여 클래스 예측
return output
예제 45)
# SentenceCNN 모델을 기반으로 한 분류기(Classifier) 모델 생성
model = Classifier(
sr_model=SentenceCNN, # 문장을 벡터로 변환하는 모델로 CNN 기반 SentenceCNN 사용
output_dim=2, # 최종 출력 차원 (이진 분류: 긍정/부정)
vocab_size=len(vocabs), # 어휘 사전 크기 (단어 개수)
embed_dim=16 # 단어 임베딩 차원 (각 단어를 16차원 벡터로 변환)
)
예제 46)
model.sr_model.embeddings.weight[0] # [PAD] 토큰(또는 0번 단어)의 16차원 벡터를 반환
-->
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
grad_fn=<SelectBackward0>)
예제 47)
import torch
use_cuda = torch.cuda.is_available() # CUDA(=GPU 사용 가능 여부) 확인
if use_cuda:
model.cuda() # 모델을 GPU로 이동
예제 48)
import torch.optim as optim
import torch.nn as nn
# Adam 옵티마이저 설정 (모델의 모든 파라미터 학습, 학습률: 0.01)
optimizer = optim.Adam(params=model.parameters(), lr=0.01)
# -> 모델의 가중치를 최적화하기 위해 Adam(Adaptive Moment Estimation) 옵티마이저 사용
# -> lr (learning rate, 학습률) = 0.01 (매우 높은 값, 일반적으로 0.001 추천)
# 크로스 엔트로피 손실 함수 설정 (분류 문제에서 자주 사용됨)
loss_func = nn.CrossEntropyLoss()
# -> 다중 클래스 분류에서 사용되는 손실 함수
# -> 소프트맥스 확률 분포를 기대값(정답 레이블)과 비교하여 손실 계산
# 학습할 총 에포크(epoch) 수 설정 (데이터 전체를 10번 학습)
n_epoch = 10
# 학습 진행을 추적하는 전역(global) 인덱스 (미니배치 업데이트 횟수)
global_i = 0
# 검증 손실 및 훈련 손실을 저장할 리스트 (학습 추적용)
valid_loss_history = [] # 검증 데이터에서 계산된 손실 저장
train_loss_history = [] # 훈련 데이터에서 계산된 손실 저장
# 가장 성능이 좋은 모델을 저장하기 위한 변수
best_model = None # 가장 낮은 검증 손실을 기록한 모델 저장
# 가장 성능이 좋은 모델이 학습된 에포크 인덱스 저장
best_epoch_i = None
# 최소 검증 손실을 매우 큰 값으로 초기화 (최소값 찾기 위한 변수)
min_valid_loss = 9e+9 # 9 * 10^9 (매우 큰 수)
예제 49)
import torch
import numpy as np
from copy import deepcopy
# 학습 루프 (총 n_epoch 동안 실행)
for epoch_i in range(n_epoch):
model.train() # 모델을 학습 모드로 설정 (Dropout, BatchNorm 등 활성화)
# 훈련 데이터셋을 배치 단위로 반복
for batch in train_dataloader:
optimizer.zero_grad() # 이전 기울기(gradient) 초기화
# 입력(X)과 정답(y) 데이터를 PyTorch 텐서로 변환
X = torch.tensor(batch['doc_ids']) # 입력 데이터 (토큰 ID)
y = torch.tensor(batch['label']) # 정답 레이블
# GPU가 사용 가능한 경우 데이터를 GPU로 이동
if use_cuda:
X = X.cuda()
y = y.cuda()
# 모델 예측 (Forward Propagation)
y_pred = model(X)
# 손실(loss) 계산 (CrossEntropyLoss 사용)
loss = loss_func(y_pred, y)
# 100번째 스텝마다 손실 출력 (훈련 상태 모니터링)
if global_i % 100 == 0:
print(f'i: {global_i}, epoch:{epoch_i}, loss: {loss.item()}')
# 훈련 손실 기록
train_loss_history.append((global_i, loss.item()))
# 역전파 (Backpropagation) 수행하여 기울기 계산
loss.backward()
# 옵티마이저(Adam) 업데이트 (가중치 조정)
optimizer.step()
# 전역(global) 스텝 카운트 증가
global_i += 1
# 모델을 평가 모드로 전환 (Dropout, BatchNorm 등 비활성화)
model.eval()
# 검증 손실 저장 리스트
valid_loss_list = []
# 검증 데이터셋을 배치 단위로 반복
for batch in valid_dataloader:
X = torch.tensor(batch['doc_ids']) # 입력 데이터
y = torch.tensor(batch['label']) # 정답 레이블
# GPU가 사용 가능한 경우 데이터를 GPU로 이동
if use_cuda:
X = X.cuda()
y = y.cuda()
# 모델 예측 (Forward)
y_pred = model(X)
# 손실(loss) 계산
loss = loss_func(y_pred, y)
# 검증 손실 리스트에 추가
valid_loss_list.append(loss.item())
# 검증 데이터의 평균 손실 계산
valid_loss_mean = np.mean(valid_loss_list)
# 검증 손실 기록
valid_loss_history.append((global_i, valid_loss_mean.item()))
# 현재 에포크에서의 검증 손실이 최소 손실보다 작다면, 모델 저장
if valid_loss_mean < min_valid_loss:
min_valid_loss = valid_loss_mean # 최소 검증 손실 업데이트
best_epoch_i = epoch_i # 최적 모델이 저장된 에포크 기록
best_model = deepcopy(model) # 현재 모델을 복사하여 저장
# 2 에포크마다 검증 손실 출력
if epoch_i % 2 == 0:
print("*" * 30)
print(f'valid_loss_mean: {valid_loss_mean}')
print("*" * 30)
print()
# 최적의 검증 손실을 기록한 에포크 출력
print(f'best_epoch: {best_epoch_i}')
-->
i: 0, epoch:0, loss: 0.7164996862411499
i: 100, epoch:0, loss: 0.6770316958427429
i: 200, epoch:0, loss: 0.5999457240104675
i: 300, epoch:0, loss: 0.6141746044158936
i: 400, epoch:0, loss: 0.5077617764472961
******************************
valid_loss_mean: 0.5240354464720871
******************************
i: 500, epoch:1, loss: 0.4681397080421448
i: 600, epoch:1, loss: 0.4514097273349762
i: 700, epoch:1, loss: 0.419582724571228
i: 800, epoch:1, loss: 0.4807898700237274
i: 900, epoch:1, loss: 0.3982866704463959
i: 1000, epoch:2, loss: 0.22625410556793213
i: 1100, epoch:2, loss: 0.2789754271507263
i: 1200, epoch:2, loss: 0.26396089792251587
i: 1300, epoch:2, loss: 0.25320735573768616
i: 1400, epoch:2, loss: 0.3402232229709625
******************************
valid_loss_mean: 0.564072670067771
******************************
i: 1500, epoch:3, loss: 0.1931603103876114
i: 1600, epoch:3, loss: 0.21325650811195374
i: 1700, epoch:3, loss: 0.2861916124820709
i: 1800, epoch:3, loss: 0.20574922859668732
i: 1900, epoch:4, loss: 0.13632620871067047
i: 2000, epoch:4, loss: 0.07923101633787155
i: 2100, epoch:4, loss: 0.13159504532814026
i: 2200, epoch:4, loss: 0.13716548681259155
i: 2300, epoch:4, loss: 0.20806875824928284
******************************
valid_loss_mean: 0.7653353620888823
******************************
i: 2400, epoch:5, loss: 0.15423020720481873
i: 2500, epoch:5, loss: 0.10261551290750504
i: 2600, epoch:5, loss: 0.15399177372455597
i: 2700, epoch:5, loss: 0.18882083892822266
i: 2800, epoch:5, loss: 0.1669202446937561
i: 2900, epoch:6, loss: 0.10831696540117264
i: 3000, epoch:6, loss: 0.1898047775030136
i: 3100, epoch:6, loss: 0.1252729892730713
i: 3200, epoch:6, loss: 0.07418244332075119
******************************
valid_loss_mean: 0.9556086131576764
******************************
i: 3300, epoch:7, loss: 0.10612697154283524
i: 3400, epoch:7, loss: 0.09215044975280762
i: 3500, epoch:7, loss: 0.09496711194515228
i: 3600, epoch:7, loss: 0.0727623775601387
i: 3700, epoch:7, loss: 0.1990361362695694
i: 3800, epoch:8, loss: 0.09618052840232849
i: 3900, epoch:8, loss: 0.11006072908639908
i: 4000, epoch:8, loss: 0.08319652080535889
i: 4100, epoch:8, loss: 0.09219694882631302
i: 4200, epoch:8, loss: 0.10064951330423355
******************************
valid_loss_mean: 1.1760605752973232
******************************
i: 4300, epoch:9, loss: 0.1106734350323677
i: 4400, epoch:9, loss: 0.10765101760625839
i: 4500, epoch:9, loss: 0.11498336493968964
i: 4600, epoch:9, loss: 0.10313834995031357
best_epoch: 1
예제 50)
import numpy as np # NumPy 라이브러리 임포트
def calc_moving_average(arr, win_size=100):
"""
이동 평균(Moving Average)을 계산하는 함수
:param arr: 입력 데이터 리스트 또는 배열 (예: 손실 값 리스트)
:param win_size: 이동 평균을 계산할 윈도우 크기 (기본값: 100)
:return: 이동 평균이 적용된 NumPy 배열
"""
new_arr = [] # 이동 평균 결과를 저장할 리스트
win = [] # 이동 평균을 계산할 윈도우(최근 win_size개 값 저장)
# 입력 데이터 배열을 순회하면서 이동 평균 계산
for i, val in enumerate(arr):
win.append(val) # 현재 값을 윈도우에 추가
if len(win) > win_size:
win.pop(0) # 윈도우 크기를 초과하면 가장 오래된 값 제거
new_arr.append(np.mean(win)) # 현재 윈도우의 평균 값을 추가
return np.array(new_arr) # 최종 결과를 NumPy 배열로 반환
예제 51)
import numpy as np
import matplotlib.pyplot as plt
# 훈련 손실 및 검증 손실 기록을 NumPy 배열로 변환
valid_loss_history = np.array(valid_loss_history) # 검증 손실 기록 배열
train_loss_history = np.array(train_loss_history) # 훈련 손실 기록 배열
# 그래프 크기 설정 (12인치 x 8인치)
plt.figure(figsize=(12, 8))
# 훈련 손실 곡선 (이동 평균 적용)
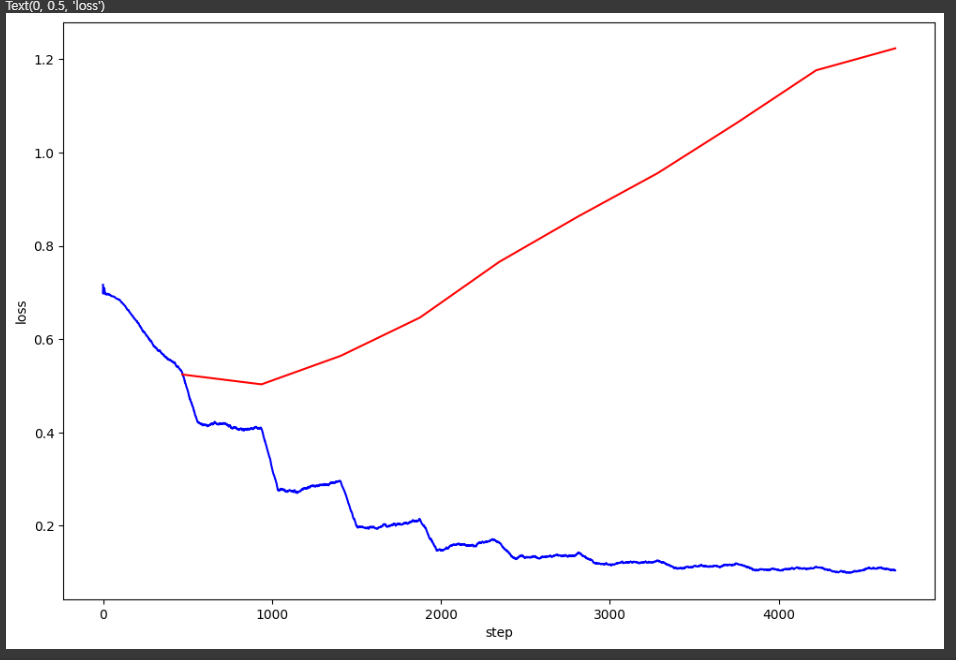
plt.plot(
train_loss_history[:, 0], # x축: 학습 step (iteration)
calc_moving_average(train_loss_history[:, 1]), # y축: 이동 평균이 적용된 훈련 손실
color='blue', # 훈련 손실 곡선을 파란색으로 표시
label='Train Loss (Moving Avg)' # 범례 추가
)
# 검증 손실 곡선 (이동 평균 없이 원본 값 사용)
plt.plot(
valid_loss_history[:, 0], # x축: 학습 step (iteration)
valid_loss_history[:, 1], # y축: 검증 손실 (원본 값)
color='red', # 검증 손실 곡선을 빨간색으로 표시
label='Valid Loss' # 범례 추가
)
# x축, y축 레이블 추가
plt.xlabel("step") # x축: 학습 과정에서의 step (iteration)
plt.ylabel("loss") # y축: 손실 값
# 그래프 범례 추가
plt.legend()
# 그래프 출력
plt.show()--->
예제 52)
# 학습된 모델을 최적(best) 모델로 설정
model = best_model
# 모델을 평가 모드로 전환 (Dropout, BatchNorm 비활성화)
model.eval()
# 총 샘플 개수 및 정답 개수를 저장할 변수 초기화
total = 0 # 총 테스트 데이터 개수
correct = 0 # 올바르게 분류된 샘플 개수
예제 53)
from tqdm import tqdm # 진행 상태 바(Progress Bar) 라이브러리
# 테스트 데이터셋을 평가하면서 정확도를 계산
for batch in tqdm(test_dataloader, total=len(test_dataloader.dataset) // test_dataloader.batch_size):
# 입력 데이터(X)와 정답(y) 텐서 변환
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
# GPU 사용 가능하면 데이터를 GPU로 이동
if use_cuda:
X = X.cuda()
y = y.cuda()
# 모델 예측 수행 (Forward Propagation)
y_pred = model(X)
# 가장 높은 확률을 가진 클래스 선택 (예측값)
curr_correct = y_pred.argmax(dim=1) == y # (예측값 == 실제값) -> True/False 값
# 전체 샘플 개수 및 맞힌 개수 업데이트
total += len(curr_correct) # 현재 배치에서 처리된 샘플 수 추가
correct += sum(curr_correct).item() # 현재 배치에서 맞춘 개수 추가
# 최종 정확도 출력
print(f'test accuracy: {correct / total:.4f}')-->

Overfitting(과적합) 발생 가능성
1. 과적합 특징
* train loss는 점점 감소하는데, valid loss가 증가한다면 모델이 학습 데이터에 너무 맞춰지고, 검증 데이터에 일반화되지 못하는 형상 때문
* CNN 모델이 너무 복잡할 경우, 학습 데이터에서는 잘 맞지만 새로운 데이터에서는 성능이 저하될 수도 있음
2. 해결 방법
* Dropout을 추가: 모델이 특정 뉴런에 과도하게 의존하는 것을 방지
* 학습률이 너무 크거나 너무 작으면 과적합이 발생할 수 있음
* Batch Normalization 사용
* Validation 데이터 불균형: train 데이터와 valid 데이터가 많이 다를 경우
* Early Stopping 적용: 학습을 너무 오래 진행하면 과적합 발생 가능성이 높음
'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 7. LSTM과 GRU (0) | 2025.02.10 |
|---|---|
| 6. RNN(Recurrent Neural Network, RNN) (0) | 2025.02.06 |
| 4. 신경망 기반의 벡터화 (2) | 2025.02.05 |
| 3. 벡터화 (0) | 2025.02.03 |
| 2. IMDB Dataset를 활용한 데이터 전처리 (0) | 2025.01.24 |