1. LSTM
* LSTM(Long Short-Term Memory)은 RNN의 장기 의존성 문제를 해결하기 위해 고안된 모델입니다.
* LSTM은 셀 상태(cell state)와 3개의 게이트(입력 게이트, 출력 게이트, 망각 게이트)를 사용하여 중요한 정보를 오랫동안 저장하고 불필요한 정보를 제거하는 구조를 갖추고 있습니다.
* 망각 게이트는 이전 셀 상태에서 필요 없는 정보를 삭제하고, 입력 게이트는 새로운 정보를 저장하며, 출력 게이트는 최종 출력을 결정합니다.
* 이러한 구조 덕분에 LSTM은 장기 시퀀스를 다루는 자연어 처리, 음성 인식, 시계열 예측 등의 다양한 분야에서 효과적으로 사용됩니다.
* 하지만 구조가 복잡하여 계산량이 많고, 학습 시간이 오래 걸린다는 단점이 있습니다.

LSTM 예시 1)
# 필요한 패키지 설치
!pip install konlpy
!pip install mecab-python
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
예시 2)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import numpy as np
import re
from konlpy.tag import Mecab
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
예시 3)
# 데이터 로드
url = 'https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt'
data = pd.read_table(url, names=['rating', 'review'])
data--->

예시 4)
# 3점 리뷰 제거 후 긍정(1), 부정(0) 라벨링
data = data[data['rating'] != 3]
data['label'] = np.where(data['rating'] > 3, 1, 0)
# 한글 텍스트만 남기기
def preprocess_text(text):
text = re.sub(r'[^가-힣\s]', '', text)
return text
data['review'] = data['review'].apply(preprocess_text)
data--->

예시 5)
from konlpy.tag import Mecab
import pandas as pd
# Mecab 형태소 분석기 초기화
mecab = Mecab()
# 불용어(stopwords) 리스트 정의
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를']
# 텍스트를 형태소 단위로 토큰화하는 함수 정의
def tokenize(text):
tokens = mecab.morphs(text) # 입력된 텍스트를 형태소 단위로 분리
return [token for token in tokens if token not in stopwords] # 불용어를 제외한 형태소 리스트 반환
# 'review' 컬럼에 대해 형태소 분석 적용 후 새로운 'tokenized' 컬럼에 저장
data['tokenized'] = data['review'].apply(tokenize)
# 결과 출력
data--->
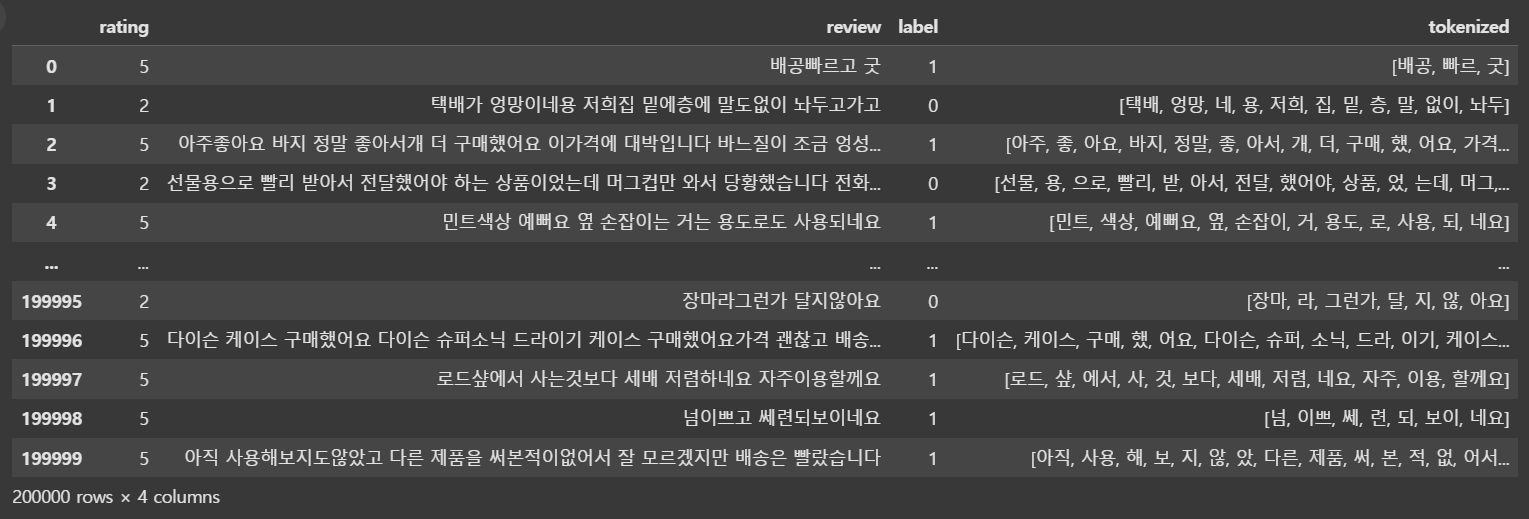
예제 6)
# 단어 사전 생성
all_tokens = [token for tokens in data['tokenized'] for token in tokens]
vocab = Counter(all_tokens)
vocab_size = len(vocab) + 2 # 패딩(0), OOV(1) 고려
word_to_index = {word: idx + 2 for idx, (word, _) in enumerate(vocab.most_common())}
word_to_index['<PAD>'] = 0
word_to_index['<OOV>'] = 1
예제 7)
# 정수 인코딩 함수 정의
def encode_tokens(tokens):
# word_to_index 딕셔너리를 사용하여 토큰을 정수로 변환
# 만약 word_to_index에 없는 단어라면 기본값 1을 반환 (OOV 토큰 처리)
return [word_to_index.get(token, 1) for token in tokens]
# 데이터프레임 'data'의 'tokenized' 열에 대해 정수 인코딩 적용
# 'tokenized' 열에는 토큰화된 단어 리스트가 저장되어 있음
# 각 토큰 리스트를 encode_tokens 함수를 이용하여 정수 리스트로 변환
data['encoded'] = data['tokenized'].apply(encode_tokens)--->
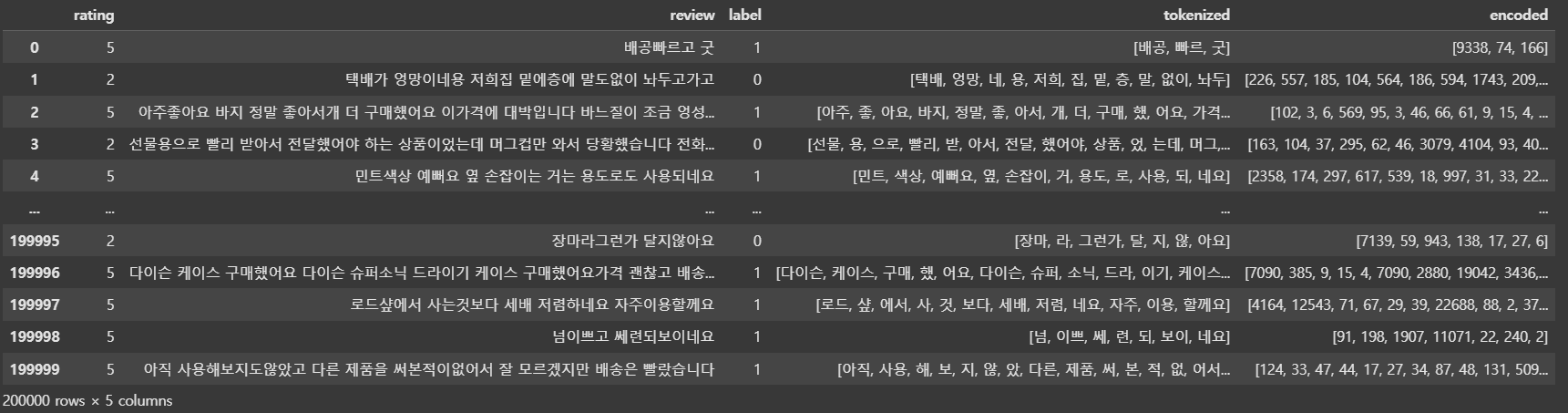
예제 8)
# 패딩 적용
max_len = 100
def pad_sequence(seq, max_len):
return seq[:max_len] + [0] * (max_len - len(seq))
data['padded'] = data['encoded'].apply(lambda x: pad_sequence(x, max_len))
data--->
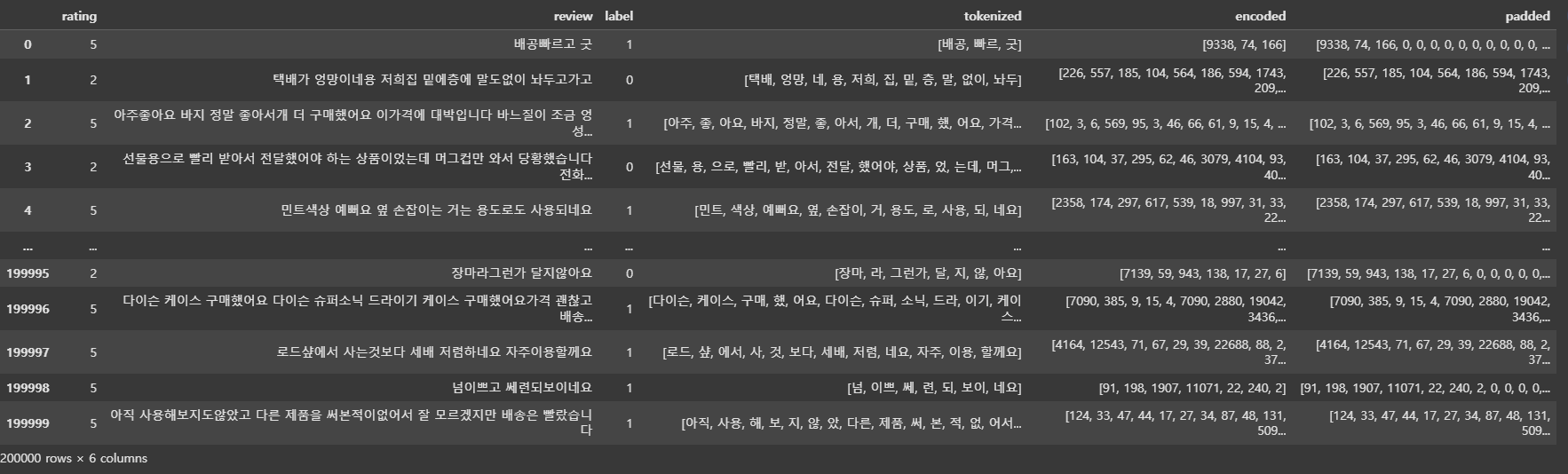
예제 9)
from torch.utils.data import Dataset
import torch
# 리뷰 데이터와 해당 레이블을 PyTorch 데이터셋으로 변환하는 클래스 정의
class ReviewDataset(Dataset):
def __init__(self, reviews, labels):
"""
생성자 (Constructor)
:param reviews: 리뷰 데이터 (정수 인코딩된 형태)
:param labels: 감성 분석을 위한 레이블 (예: 긍정/부정)
"""
# 리뷰 데이터를 PyTorch의 Tensor 형태로 변환 (정수형 long 타입)
self.reviews = torch.tensor(reviews, dtype=torch.long)
# 레이블 데이터를 PyTorch의 Tensor 형태로 변환 (실수형 float 타입)
self.labels = torch.tensor(labels, dtype=torch.float)
def __len__(self):
"""
데이터셋의 전체 길이를 반환하는 메서드
:return: 데이터 개수 (len(self.reviews)와 동일)
"""
return len(self.reviews)
# 데이터셋에서 특정 인덱스의 데이터를 반환하는 메서드
def __getitem__(self, idx):
return self.reviews[idx], self.labels[idx]
예제 10)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(data['padded'].tolist(), data['label'].tolist(), test_size=0.2, random_state=2025)
예제 11)
from torch.utils.data import DataLoader
# 배치 크기 설정
batch_size = 64
# 훈련 및 테스트 데이터셋 생성 (ReviewDataset 클래스를 이용)
train_dataset = ReviewDataset(X_train, y_train) # 훈련 데이터셋
test_dataset = ReviewDataset(X_test, y_test) # 테스트 데이터셋
# DataLoader를 이용하여 데이터셋을 배치 단위로 로드
# shuffle=True: 훈련 데이터는 매 epoch마다 섞어서 학습
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트 데이터는 순서를 유지하면서 배치 단위로 로드 (shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
예제 12)
import torch
import torch.nn as nn
# 감성 분석을 위한 LSTM 모델 정의
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout):
"""
LSTM 기반 감성 분석 모델 초기화
:param vocab_size: 단어 사전 크기 (어휘 개수)
:param embedding_dim: 단어 임베딩 차원
:param hidden_dim: LSTM 은닉 상태 차원
:param output_dim: 출력 차원 (이진 분류: 1, 다중 분류: 클래스 수)
:param n_layers: LSTM 레이어 수 (스택된 LSTM)
:param dropout: 드롭아웃 비율 (과적합 방지)
"""
super(SentimentLSTM, self).__init__()
# 임베딩 층: 입력된 정수 인덱스를 밀집 벡터로 변환
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM 층: 순차 데이터의 패턴을 학습
self.lstm = nn.LSTM(
input_size=embedding_dim, # 입력 크기 (임베딩 차원)
hidden_size=hidden_dim, # 은닉 상태 차원
num_layers=n_layers, # LSTM 레이어 개수
batch_first=True, # 입력 데이터의 첫 번째 차원을 배치 크기로 설정
dropout=dropout # 드롭아웃 적용 (과적합 방지)
)
# 배치 정규화 층: LSTM의 마지막 타임스텝 출력을 정규화하여 안정성 향상
self.batch_norm = nn.BatchNorm1d(hidden_dim)
# 출력층: LSTM의 최종 출력을 원하는 출력 차원으로 변환
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
"""
순전파 (Forward) 연산 정의
:param x: 입력 텐서 (배치 크기, 시퀀스 길이)
:return: 모델 출력 (배치 크기, output_dim)
"""
# 1. 입력 시퀀스를 임베딩 벡터로 변환
embedded = self.embedding(x) # (배치 크기, 시퀀스 길이, 임베딩 차원)
# 2. LSTM 층을 통과하여 은닉 상태 출력
lstm_out, _ = self.lstm(embedded) # lstm_out: (배치 크기, 시퀀스 길이, hidden_dim)
# 3. LSTM의 마지막 타임스텝 출력을 선택하고 배치 정규화 적용
out = self.batch_norm(lstm_out[:, -1, :]) # (배치 크기, hidden_dim)
# 4. 최종 출력층을 통과하여 감성 예측
out = self.fc(out) # (배치 크기, output_dim)
# 5. 최종 출력 반환 (BCEWithLogitsLoss 사용 시, sigmoid 적용 필요 없음)
return out
예시 12)
import torch
# 모델 하이퍼파라미터 설정
embedding_dim = 128 # 단어 임베딩 차원 (각 단어를 128차원 벡터로 표현)
hidden_dim = 512 # LSTM 은닉 상태 차원 (512로 증가하여 더 복잡한 패턴 학습 가능)
output_dim = 1 # 출력 차원 (이진 분류의 경우 1, 다중 분류의 경우 클래스 개수)
n_layers = 2 # LSTM 레이어 수 (2개로 스택된 LSTM 구조)
dropout = 0.2 # 드롭아웃 비율 (과적합 방지)
# GPU 사용 가능 여부 확인 및 장치 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# SentimentLSTM 모델 초기화
model = SentimentLSTM(vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout)
# 모델을 설정된 장치(GPU 또는 CPU)로 이동
model.to(device)
--->
SentimentLSTM(
(embedding): Embedding(41130, 128)
(lstm): LSTM(128, 512, num_layers=2, batch_first=True, dropout=0.2)
(batch_norm): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc): Linear(in_features=512, out_features=1, bias=True)
)
예제 13)
import torch.nn as nn
import torch.optim as optim
# 손실 함수 정의 (Binary Cross Entropy with Logits)
criterion = nn.BCEWithLogitsLoss()
# BCEWithLogitsLoss는 내부적으로 sigmoid 활성화 함수를 포함하므로 모델의 최종 출력층에서 sigmoid를 적용할 필요 없음
# 옵티마이저 정의 (Adam 사용, 학습률 0.005)
optimizer = optim.Adam(model.parameters(), lr=0.005)
# Adam 옵티마이저는 적응형 학습률을 사용하여 효과적인 학습을 수행함
예제 14)
import torch
def train_model(model, train_loader, criterion, optimizer, n_epochs):
"""
모델을 훈련시키는 함수
:param model: 학습할 모델 (SentimentLSTM)
:param train_loader: 훈련 데이터 로더 (DataLoader 객체)
:param criterion: 손실 함수 (BCEWithLogitsLoss)
:param optimizer: 옵티마이저 (Adam 등)
:param n_epochs: 총 학습 epoch 수
"""
# 모델을 훈련 모드로 설정
model.train()
# 전체 epoch에 대해 반복
for epoch in range(n_epochs):
epoch_loss = 0 # 현재 epoch의 총 손실
correct = 0 # 정확하게 예측한 샘플 수
total = 0 # 전체 샘플 수
# 미니배치 단위로 학습 진행
for reviews, labels in train_loader:
# 데이터를 GPU 또는 CPU로 이동
reviews, labels = reviews.to(device), labels.to(device)
# 1. 옵티마이저의 그래디언트 초기화
optimizer.zero_grad()
# 2. 모델의 예측값 계산
predictions = model(reviews).squeeze() # (batch_size,) 형태로 변환
# 3. 손실 함수 계산 (실제 값과 예측 값 비교)
loss = criterion(predictions, labels)
# 4. 역전파 (Backpropagation)
loss.backward()
# 5. 옵티마이저를 사용하여 가중치 업데이트
optimizer.step()
# 현재 epoch의 총 손실 누적
epoch_loss += loss.item()
# 6. 정확도 계산
preds = (torch.sigmoid(predictions) >= 0.5).float() # 0.5 이상이면 긍정(1), 아니면 부정(0)
correct += (preds == labels).sum().item() # 정확하게 예측한 개수 합산
total += labels.size(0) # 전체 샘플 개수 증가
# epoch 단위로 평균 손실 및 정확도 계산
epoch_loss /= len(train_loader)
epoch_acc = correct / total
# 현재 epoch의 학습 결과 출력
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.4f}')
예제 15)
# 학습 실행
train_model(model, train_loader, criterion, optimizer, 5)
-->
Epoch 1/5, Loss: 0.3669, Accuracy: 0.8487
Epoch 2/5, Loss: 0.2583, Accuracy: 0.9089
Epoch 3/5, Loss: 0.2359, Accuracy: 0.9177
Epoch 4/5, Loss: 0.2983, Accuracy: 0.8850
Epoch 5/5, Loss: 0.2739, Accuracy: 0.8962
예제 16)
import torch
from sklearn.metrics import accuracy_score
def evaluate_model(model, test_loader):
"""
모델을 평가하는 함수
:param model: 학습된 모델 (SentimentLSTM)
:param test_loader: 평가 데이터 로더 (DataLoader 객체)
"""
# 모델을 평가 모드로 설정 (Dropout, BatchNorm 비활성화)
model.eval()
correct = 0 # 정확히 예측한 개수
total = 0 # 전체 샘플 개수
predictions_list = [] # 예측값 저장 리스트
labels_list = [] # 실제 레이블 저장 리스트
# 평가에서는 기울기 계산을 하지 않도록 설정 (메모리 절약 및 속도 향상)
with torch.no_grad():
for reviews, labels in test_loader:
# 데이터를 GPU 또는 CPU로 이동
reviews, labels = reviews.to(device), labels.to(device)
# 모델 예측 수행
predictions = model(reviews).squeeze() # (batch_size,) 형태로 변환
# 0.5를 기준으로 긍정(1), 부정(0) 클래스로 변환
preds = (torch.sigmoid(predictions) >= 0.5).float()
# 정확히 예측한 개수 누적
correct += (preds == labels).sum().item()
total += labels.size(0)
# 예측값 및 실제값을 리스트에 저장 (CPU로 이동 후 numpy 변환)
predictions_list.extend(preds.cpu().numpy())
labels_list.extend(labels.cpu().numpy())
# 정확도 계산 (Scikit-learn의 accuracy_score 함수 사용)
accuracy = accuracy_score(labels_list, predictions_list)
# 최종 정확도 출력
print(f'Test Accuracy: {accuracy:.4f}')
예제 17)
import torch
def predict_sentiment(model, sentence):
"""
주어진 문장의 감성을 예측하는 함수
:param model: 학습된 SentimentLSTM 모델
:param sentence: 감성 분석을 수행할 입력 문장 (문자열)
"""
# 모델을 평가 모드로 설정
model.eval()
# 1. 문장 토큰화 (단어 단위로 나누기)
tokens = tokenize(sentence)
# 2. 정수 인코딩 (단어를 숫자로 변환)
encoded = encode_tokens(tokens)
# 3. 패딩 적용 (최대 길이 max_len에 맞춰 패딩 추가)
padded = pad_sequence(encoded, max_len)
# 4. 입력 데이터를 PyTorch 텐서로 변환하고 GPU/CPU로 이동
input_tensor = torch.tensor([padded], dtype=torch.long).to(device)
# 5. 모델을 사용하여 예측 수행 (기울기 계산 X)
with torch.no_grad():
prediction = model(input_tensor).item() # 모델 출력값 (로짓 값)
# 6. 시그모이드 함수를 적용하여 확률 값 변환 (긍정 확률)
probability = torch.sigmoid(torch.tensor(prediction)).item()
# 7. 임계값(0.5) 기준으로 긍정/부정 판별
sentiment = "긍정" if probability >= 0.5 else "부정"
# 8. 결과 출력
print(f"입력 문장: {sentence}")
print(f"예측 확률: {probability:.4f} ({sentiment})")
예제 18)
# 테스트
test_sentences = [
"이 제품 정말 좋아요! 추천합니다.",
"완전 별로예요. 사지 마세요.",
"기대 이하입니다. 실망했어요."
]
예제 19)
# 테스트할 문장 리스트를 순회하며 감성 예측 수행
for sentence in test_sentences:
predict_sentiment(model, sentence)
-->
입력 문장: 이 제품 정말 좋아요! 추천합니다.
예측 확률: 0.9545 (긍정)
입력 문장: 완전 별로예요. 사지 마세요.
예측 확률: 0.0371 (부정)
입력 문장: 기대 이하입니다. 실망했어요.
예측 확률: 0.0156 (부정)
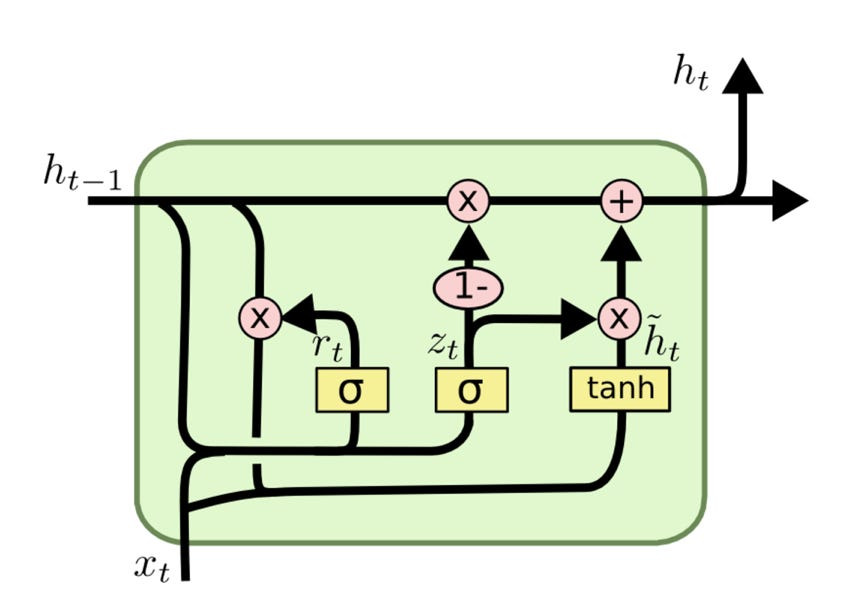
2. GRU
* GRU(Gated Recurrent Unit)는 2014년 뉴욕대학교(NYU) 조경현(Kyunghyun Cho) 교수 연구팀이 제안한 RNN의 장기 의존성 문제를 해결하기 위해 개발한 신경망 구조입니다.
* LSTM과 유사한 성능을 가지면서도 더 간단한 구조를 갖고 있어 연산량이 적고 학습 속도가 빠릅니다.
* GRU는 업데이트 게이트(Update Gate)와 리셋 게이트(Reset Gate)라는 두 개의 게이트만을 사용하여 정보를 조절하며, LSTM보다 파라미터 수가 적어 적은 데이터셋에서도 효과적으로 학습할 수 있습니다.
* 업데이트 게이트는 이전 정보를 얼마나 유지할지 결정하고, 리셋 게이트는 새로운 정보를 반영하기 위해 기존 정보를 얼마나 잊을지 조정합니다.
* 이러한 특성 덕분에 GRU는 텍스트 처리, 음성 인식, 시계열 예측 등에서 LSTM보다 더 빠르고 효율적으로 사용할 수 있지만, 장기 의존성이 중요한 경우 LSTM이 더 나은 성능을 보일 수도 있습니다.

GRU 예시 1)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import numpy as np
import re
from konlpy.tag import Mecab
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
예시 2)
url = 'https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt'
data = pd.read_table(url, names=['rating', 'review'])
# 3점 리뷰 제거 후 긍정(1), 부정(0) 라벨링
data = data[data['rating'] != 3]
data['label'] = np.where(data['rating'] > 3, 1, 0)
# 한글 텍스트만 남기기
def preprocess_text(text):
text = re.sub(r'[^가-힣\s]', '', text)
return text
data['review'] = data['review'].apply(preprocess_text)
# 형태소 분석기 적용
mecab = Mecab()
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를']
def tokenize(text):
tokens = mecab.morphs(text)
return [token for token in tokens if token not in stopwords]
data['tokenized'] = data['review'].apply(tokenize)
# 단어 사전 생성
all_tokens = [token for tokens in data['tokenized'] for token in tokens]
vocab = Counter(all_tokens)
vocab_size = len(vocab) + 2 # 패딩(0), OOV(1) 고려
word_to_index = {word: idx + 2 for idx, (word, _) in enumerate(vocab.most_common())}
word_to_index['<PAD>'] = 0
word_to_index['<OOV>'] = 1
# 정수 인코딩
def encode_tokens(tokens):
return [word_to_index.get(token, 1) for token in tokens]
data['encoded'] = data['tokenized'].apply(encode_tokens)
# 패딩 적용
max_len = 100
def pad_sequence(seq, max_len):
return seq[:max_len] + [0] * (max_len - len(seq))
data['padded'] = data['encoded'].apply(lambda x: pad_sequence(x, max_len))
class ReviewDataset(Dataset):
def __init__(self, reviews, labels):
self.reviews = torch.tensor(reviews, dtype=torch.long)
self.labels = torch.tensor(labels, dtype=torch.float)
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
return self.reviews[idx], self.labels[idx]
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(data['padded'].tolist(), data['label'].tolist(), test_size=0.2, random_state=2025)
# DataLoader
batch_size = 64
train_dataset = ReviewDataset(X_train, y_train)
test_dataset = ReviewDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
class SentimentGRU(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout):
super(SentimentGRU, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM -> GRU 변경
self.gru = nn.GRU(embedding_dim, hidden_dim, num_layers=n_layers, batch_first=True, dropout=dropout)
self.batch_norm = nn.BatchNorm1d(hidden_dim) # 배치 정규화 추가
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
embedded = self.embedding(x)
gru_out, _ = self.gru(embedded) # GRU 실행
out = self.batch_norm(gru_out[:, -1, :]) # 마지막 타임스텝의 출력 사용
out = self.fc(out)
return out # BCEWithLogitsLoss 내부에서 sigmoid 적용됨
# 모델 초기화
embedding_dim = 128
hidden_dim = 512
output_dim = 1
n_layers = 2
dropout = 0.2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SentimentGRU(vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout)
model.to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.AdamW(model.parameters(), lr=0.0005)
def train_model(model, train_loader, criterion, optimizer, n_epochs):
model.train()
for epoch in range(n_epochs):
epoch_loss = 0
correct = 0
total = 0
for reviews, labels in train_loader:
reviews, labels = reviews.to(device), labels.to(device)
optimizer.zero_grad()
predictions = model(reviews).squeeze()
loss = criterion(predictions, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
preds = (torch.sigmoid(predictions) >= 0.5).float()
correct += (preds == labels).sum().item()
total += labels.size(0)
epoch_acc = correct / total
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {epoch_loss/len(train_loader):.4f}, Accuracy: {epoch_acc:.4f}')
train_model(model, train_loader, criterion, optimizer, 5)
--->
Epoch 1/5, Loss: 0.3174, Accuracy: 0.8699
Epoch 2/5, Loss: 0.2264, Accuracy: 0.9176
Epoch 3/5, Loss: 0.1888, Accuracy: 0.9335
Epoch 4/5, Loss: 0.1513, Accuracy: 0.9486
Epoch 5/5, Loss: 0.1154, Accuracy: 0.9623
예시 3)
def evaluate_model(model, test_loader):
model.eval()
correct = 0
total = 0
predictions_list = []
labels_list = []
with torch.no_grad():
for reviews, labels in test_loader:
reviews, labels = reviews.to(device), labels.to(device)
predictions = model(reviews).squeeze()
preds = (predictions >= 0.5).float()
correct += (preds == labels).sum().item()
total += labels.size(0)
predictions_list.extend(preds.cpu().numpy())
labels_list.extend(labels.cpu().numpy())
accuracy = accuracy_score(labels_list, predictions_list)
print(f'Test Accuracy: {accuracy:.4f}')
# 평가 실행
evaluate_model(model, test_loader)
-->
Test Accuracy: 0.9143
예시 4)
import torch
def predict_sentiment(model, sentence):
model.eval()
tokens = tokenize(sentence)
encoded = encode_tokens(tokens)
padded = pad_sequence(encoded, max_len)
input_tensor = torch.tensor([padded], dtype=torch.long).to(device)
with torch.no_grad():
prediction = model(input_tensor).item()
probability = torch.sigmoid(torch.tensor(prediction)).item() # 확률로 변환
sentiment = "긍정" if probability >= 0.5 else "부정"
print(f"입력 문장: {sentence}")
print(f"예측 확률: {probability:.4f} ({sentiment})")
예시 5)
# 테스트
test_sentences = [
"이 제품 정말 좋아요! 추천합니다.",
"완전 별로예요. 사지 마세요.",
"기대 이하입니다. 실망했어요.",
"한번 쓰고 버렸네요"
]
예제 6)
for sentence in test_sentences:
predict_sentiment(model, sentence)
--->
입력 문장: 이 제품 정말 좋아요! 추천합니다.
예측 확률: 0.9795 (긍정)
입력 문장: 완전 별로예요. 사지 마세요.
예측 확률: 0.0002 (부정)
입력 문장: 기대 이하입니다. 실망했어요.
예측 확률: 0.0008 (부정)
입력 문장: 한번 쓰고 버렸네요
예측 확률: 0.0003 (부정)
Bidirectional
* Bidirectional(양방향) RNN은 순방향(forward)과 역방향(backward)으로 정보를 처리하여 입력 시퀀스의 과거와 미래 정보를 모두 활용하는 방식으로, 일반적인 단방향 RNN이 과거에서 현재로만 정보를 전달하는 것과 달리, Bidirectional RNN은 역방향으로도 학습하여 보다 풍부한 문맥 정보를 학습할 수 있어 자연어 처리(NLP)와 시계열 분석에서 유용하게 사용됩니다.
* (bidirectional=True 옵션만 추가하면 Bidirectional RNN, LSTM/GRU를 사용할 수 있습니다.)
교사 강요(Teacher Forcing)
* 교사 강요(Teacher Forcing)는 RNN이나 LSTM과 같은 순환 신경망을 훈련할 때 사용되는 기법으로, 이전 타임스텝에서 예측한 출력을 다음 입력으로 사용하는 대신, 정답 레이블(실제 값, Ground Truth)을 다음 입력으로 강제로 제공하여 모델이 빠르게 학습하도록 돕는 방법입니다.
* 이 방식은 수렴 속도를 높이고 학습을 안정적으로 만들지만, 실제 추론 시에는 정답을 제공할 수 없기 때문에 모델이 학습 시점과 다르게 동작하는 노출 편향(Exposure Bias) 문제가 발생할 수 있습니다.
'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 10. 어텐션 메커니즘 (1) | 2025.02.12 |
|---|---|
| 8. Seq2Seq (0) | 2025.02.11 |
| 6-2. RNN 활용 (0) | 2025.02.10 |
| 6. RNN(Recurrent Neural Network, RNN) (0) | 2025.02.06 |
| 5. CNN Text Classification (0) | 2025.02.06 |