1. 워드 임베딩
* 워드 임베딩(Word Embedding)은 단어를 고차원의 희소 벡터로 표현하는 기존 방식(원-핫 인코딩) 대신, 단어의 의미를 저차원의 밀집 벡터(dense vector)로 변환하는 자연어 처리 기법입니다.
* 이를 통해 단어 간 유사성과 관계를 벡터 공간에 효율적으로 나타낼 수 있으며, 벡터 간의 거리 또는 방향을 통해 단어의 문맥적 의미를 학습합니다.
* 대표적인 워드 임베딩 알고리즘으로는 Embedding Layer, Word2Vec, GloVe, FastText 등이 있으며, 이를 사용하면 언어 모델이 문맥을 이해하거나 추론하는 데 필요한 기초적인 언어적 의미를 학습할 수 있습니다.
### 1-1. 랜덤 초기화 임베딩
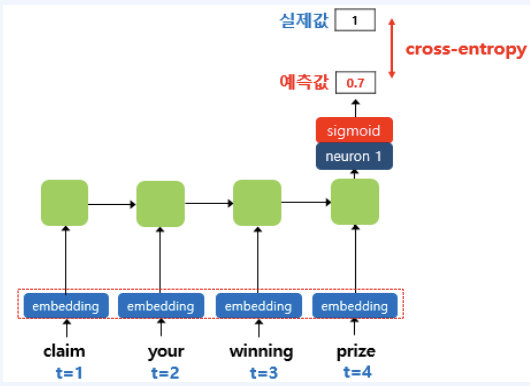
* 랜덤 초기화 임베딩은 모델 학습 초기 단계에서 임베딩 벡터를 무작위 값으로 설정한 후, 학습 데이터를 사용해 임베딩 값을 점진적으로 업데이트하는 방식입니다.
* 초기에는 각 단어의 벡터 표현이 의미를 가지지 않으며, 학습 과정에서 모델이 단어의 문맥적 의미를 학습하며 점차 유의미한 벡터를 형성합니다.
* 이 방식은 특정 도메인이나 언어의 특수성을 반영하기에 적합하며, 사전 훈련된 임베딩이 없는 경우나 사용자 정의 데이터를 기반으로 처음부터 학습해야 할 때 주로 사용됩니다.
### 1-2. 사전 훈련된 임베딩
* 사전 훈련된 임베딩은 대규모 코퍼스에서 미리 학습된 임베딩 벡터를 사용하여 초기 값을 설정하는 방식입니다.
* Word2Vec, GloVe, FastText 등과 같은 모델로 생성된 임베딩은 단어 간의 의미적 유사성을 잘 반영하며, 이를 활용하면 학습 초기에 좋은 성능을 얻을 수 있습니다.
* 사전 훈련된 임베딩은 학습 데이터가 부족하거나 일반적인 언어적 특징을 잘 반영해야 하는 상황에서 특히 유용합니다.
* 필요에 따라 임베딩 벡터를 고정하거나(frozen) 추가로 미세 조정(fine-tuning)하여 사용할 수 있습니다.

2. Embedding Layer
* Embedding Layer는 신경망에서 단어를 밀집 벡터(dense vector)로 표현하기 위해 사용되는 층으로, 워드 임베딩(Word Embedding)을 수행하는 역할을 합니다.
* 이 레이어는 주어진 단어를 정수 인덱스로 매핑한 후, 해당 인덱스에 대응되는 고정 길이의 임베딩 벡터를 학습 가능한 파라미터로 초기화하여 반환합니다.
* 입력 크기가 크고 희소한 원-핫 인코딩 대신, 저차원의 임베딩 공간에서 단어의 의미적 관계를 효율적으로 학습하며, 이는 신경망의 가중치로 함께 학습됩니다.
* Embedding Layer는 주로 텍스트 데이터에서 단어를 벡터화하여 자연어 처리 모델(예: RNN, LSTM, Transformer)에 입력하기 위해 사용됩니다.

3. Word2Vec
* Word2Vec은 단어를 벡터로 표현하기 위해 개발된 자연어 처리 기법으로, 단어 간의 의미적 유사성을 수치적으로 나타낼 수 있는 임베딩 벡터를 생성합니다.
* 주로 CBOW(Continuous Bag of Words)와 Skip-gram이라는 두 가지 모델 구조를 사용하며, CBOW는 주변 단어들을 기반으로 중심 단어를 예측하고, Skip-gram은 중심 단어를 기반으로 주변 단어들을 예측하는 방식입니다.
* 이 과정을 통해 학습된 임베딩 벡터는 단어 간의 문맥적 관계를 반영하며, 벡터 공간에서 유사한 의미를 가진 단어들이 서로 가깝게 위치합니다.
* Word2Vec은 대규모 코퍼스를 활용해 고성능 임베딩을 생성할 수 있으며, 자연어 처리 작업에서 사전 훈련된 임베딩으로 널리 사용됩니다.
* 벡터가 된 단어들은 연산이 가능합니다.
링크 주소 : https://word2vec.kr/search/
Korean Word2Vec
ABOUT 이곳은 단어의 효율적인 의미 추정 기법(Word2Vec 알고리즘)을 우리말에 적용해 본 실험 공간입니다. Word2Vec 알고리즘은 인공 신경망을 생성해 각각의 한국어 형태소를 1,000차원의 벡터 스페이
word2vec.kr
### 3-1. CBOW
* CBOW(Continuous Bag of Words)는 자연어 처리에서 단어 임베딩을 학습하기 위해 사용되는 Word2Vec 알고리즘의 한 방법입니다.
* 이 모델은 주어진 문맥(즉, 중심 단어 주변의 단어들)을 기반으로 중심 단어를 예측하는 방식으로 작동합니다.
* 예를 들어, 문장에서 특정 단어의 좌우 몇 개 단어를 입력으로 받아 해당 중심 단어를 출력으로 예측하는 구조입니다.
* 이를 통해 단어 간의 문맥적 관계를 효과적으로 학습할 수 있으며, 단어를 고차원 공간의 벡터로 표현하여 의미적으로 유사한 단어들이 가까운 위치에 있도록 학습됩니다.
* CBOW는 연산적으로 효율적이며, 대규모 데이터에서 빠르고 안정적으로 임베딩을 생성할 수 있다는 장점이 있습니다.
1. 문맥과 중심 단어 설정
### 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."





### 3-2. Skip-gram
* Skip-gram은 Word2Vec 알고리즘의 한 방법으로, 주어진 중심 단어로부터 주변 문맥 단어들을 예측하는 방식으로 작동합니다.
* 즉, 중심 단어를 입력으로 사용하고, 그 단어를 기준으로 설정된 윈도우 크기 내에 있는 주변 단어들을 출력으로 예측합니다.
* 예를 들어, 문장에서 "고양이"라는 단어가 중심 단어라면, 그 주변 단어들(예: "귀여운", "자는")을 예측하는 식입니다.
* Skip-gram은 희소한 데이터에서도 성능이 우수하며, 특히 드문 단어의 문맥적 의미를 학습하는 데 효과적입니다.
* 이 모델은 단어의 의미적 관계를 더 잘 반영한 고품질의 단어 벡터를 생성할 수 있지만, CBOW에 비해 계산량이 더 많다는 특징이 있습니다.
### 문장 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."







3-3. SGNS
* SGNS(Skip-Gram with Negative Sampling)는 Skip-gram 모델의 변형으로, 단어 임베딩을 효율적으로 학습하기 위해 네거티브 샘플링(Negative Sampling) 기법을 사용합니다.
* 기본 Skip-gram은 중심 단어로 주변의 모든 문맥 단어를 예측해야 하지만, SGNS는 주변 단어와의 관계를 일부 샘플로만 학습하여 계산 비용을 줄입니다.
* 즉, 중심 단어와 실제 문맥 단어 쌍(정답)을 학습하면서, 무작위로 선택된 단어(네거티브 샘플)들과의 관계를 "연관성이 없다"고 학습시킵니다.
* 이를 통해 모델은 중심 단어와 문맥 단어 간의 의미적 관계를 효과적으로 학습하면서도 연산량을 크게 줄일 수 있습니다.
* SGNS는 Word2Vec 알고리즘에서 널리 사용되며, 실제로 가장 보편적인 단어 임베딩 학습 방법으로 자리 잡았습니다.
### 문장 예제
"나는 오늘 공원에서 귀여운 강아지를 산책시키며 행복한 시간을 보냈다."




예시 1)
# 자연어 처리를 위한 파이썬 기반의 오픈소스 라이브러리
import gensim
gensim.__version__ # 버전 확인
-->
4.3.3
### Gensim
* Gensim은 자연어 처리를 위한 파이썬 기반의 오픈소스 라이브러리로, 특히 문서와 단어 임베딩 및 주제 모델링 작업에 적합합니다.
* Gensim은 효율적이고 확장 가능한 방식으로 Word2Vec, Doc2Vec, FastText 등의 임베딩 모델과 LDA(Latent Dirichlet Allocation) 같은 주제 모델링 알고리즘을 지원합니다.
* 이 라이브러리는 대규모 텍스트 데이터에서도 빠르게 학습할 수 있도록 최적화되어 있으며, 스트리밍 방식으로 메모리 효율적으로 데이터를 처리할 수 있습니다.
* Gensim은 간단한 API를 제공해 연구와 실제 프로젝트에서 사용하기 쉽고, 텍스트의 의미적 관계를 학습하거나 토픽 분류, 문서 추천 등 다양한 작업에 활용됩니다.
### TED Talks의 자막 데이터
* ted_en-20160408.xml 데이터는 TED Talks의 자막 데이터를 XML 형식으로 저장한 파일입니다.
* 이 데이터는 주로 자연어 처리(NLP) 및 기계 학습 프로젝트에서 텍스트 데이터로 활용됩니다.
* 이 파일은 다양한 TED 강연의 영어 자막을 포함하고 있으며, 각 강연의 텍스트와 메타데이터가 포함되어 있습니다.
예시 1)
import urllib # URL에서 데이터를 다운로드하기 위한 라이브러리 임포트
# 지정된 URL에서 파일을 다운로드하여 로컬에 저장
urllib.request.urlretrieve(
"https://raw.githubusercontent.com/GaoleMeng/RNN-and-FFNN-textClassification/master/ted_en-20160408.xml",
filename="ted_en-20160408.xml"
)
-->
('ted_en-20160408.xml', <http.client.HTTPMessage at 0x7f96765e2650>)
## xml 파일 요약본 참고 사항
## xml 파일 코드 요악본
<file>
<head>
<url>http://www.ted.com/talks/ken_robinson_says_schools_kill_creativity</url>
<pagesize>12345</pagesize>
<title>Ken Robinson: Do schools kill creativity?</title>
</head>
<content>
<p>Good morning. How are you? It's been great, hasn't it? I've been blown away by the whole thing.</p>
<p>In fact, I'm leaving.</p>
...
</content>
</file>

예시 1)
# from xml.etree.ElementTree import parse
# from xml.etree.ElementTree import tostring
from lxml import etree
예시 2)
# 'ted_en-20160408.xml' 파일을 UTF-8 인코딩으로 읽기 모드('r')
targetXML = open('ted_en-20160408.xml', 'r', encoding='UTF8')
# XML 파일을 파싱하여 ElementTree 객체로 변환
target_text = etree.parse(targetXML)
# XML 문서의 루트(root) 요소를 가져옴
root = target_text.getroot()
예시 3)
# XML 파일의 앞부분(루트 노드 포함)을 일부만 출력
xml_string = etree.tostring(root).decode('utf-8')
print('\n'. join(xml_string.split('\n')[:20]))
--->
<xml language="en"><file id="1">
<head>
<url>http://www.ted.com/talks/knut_haanaes_two_reasons_companies_fail_and_how_to_avoid_them</url>
<pagesize>72832</pagesize>
<dtime>Fri Apr 01 00:57:03 CEST 2016</dtime>
<encoding>UTF-8</encoding>
<content-type>text/html; charset=utf-8</content-type>
<keywords>talks, business, creativity, curiosity, goal-setting, innovation, motivation, potential, success, work</keywords>
<speaker>Knut Haanaes</speaker>
<talkid>2470</talkid>
<videourl>http://download.ted.com/talks/KnutHaanaes_2015S.mp4</videourl>
<videopath>talks/KnutHaanaes_2015S.mp4</videopath>
<date>2015/06/30</date>
<title>Knut Haanaes: Two reasons companies fail -- and how to avoid them</title>
<description>TED Talk Subtitles and Transcript: Is it possible to run a company and reinvent it at the same time? For business strategist Knut Haanaes, the ability to innovate after becoming successful is the mark of a great organization. He shares insights on how to strike a balance between perfecting what we already know and exploring totally new ideas -- and lays out how to avoid two major strategy traps.</description>
<transcription>
<seekvideo id="1596">Here are two reasons companies fail:</seekvideo>
<seekvideo id="5208">they only do more of the same,</seekvideo>
<seekvideo id="8478">or they only do what's new.</seekvideo>
<seekvideo id="11613">To me the real, real solution to quality growth</seekvideo>
예시 4)
# XML 파일로부터 <content> 와 </content> 사이의 내용만 가져옴
parse_text = '\n'.join(target_text.xpath('//content/text( )'))
parse_text
-->--->

예시 5)
# 정규 표현식 sub 모듈을 통해 content 중간에 등장하는 (Audio), ( Laughter) 등 제거
import re
content_text = re.sub(r'\([^)]*\)', '', parse_text)
content_text-->

예시 6)
# 문장의 길이
len(content_text)
-->
24062319
예시 7)
# 토큰화
import nltk
from nltk.tokenize import sent_tokenize
예시 7-1)
# punkt_tab 패키지 설치
nltk.download('punkt_tab')
예시 8)
# content_text를 문장 단위로 나눔
sent_text = sent_tokenize(content_text)
# 문장 목록의 첫 두 개 요소를 출력
sent_text[:2]
--->
["Here are two reasons companies fail: they only do more of the same, or they only do what's new.",
'To me the real, real solution to quality growth is figuring out the balance between two activities: exploration and exploitation.']
예시 9)
# 각 문장에 대해서 구두점을 제거하고, 대문자를 소문자로 변환
normalized_text = [] # 정규화된 문장을 저장할 리스트 생성
for string in sent_text:
# 정규 표현식을 사용하여 알파벳 소문자(a-z)와 숫자(0-9) 이외의 문자(구두점, 특수문자 등)를 공백(" ")으로 변환
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
# 변환된 문장을 리스트에 추가
normalized_text.append(tokens)
# 정규화된 첫 두 개 문장 출력
normalized_text[:2]
-->
['here are two reasons companies fail they only do more of the same or they only do what s new ',
'to me the real real solution to quality growth is figuring out the balance between two activities exploration and exploitation ']
예시 10)
# 문장을 토큰화
result = [nltk.word_tokenize(sentence) for sentence in normalized_text]
print('총 샘플의 개수 : {}'.format(len(result)))
-->
총 샘플의 개수 : 273424
예시 11)
# result 리스트의 첫 3개 요소를 출력
for line in result[:3]:
print(line)
-->
['here', 'are', 'two', 'reasons', 'companies', 'fail', 'they', 'only', 'do', 'more', 'of', 'the', 'same', 'or', 'they', 'only', 'do', 'what', 's', 'new']
['to', 'me', 'the', 'real', 'real', 'solution', 'to', 'quality', 'growth', 'is', 'figuring', 'out', 'the', 'balance', 'between', 'two', 'activities', 'exploration', 'and', 'exploitation']
['both', 'are', 'necessary', 'but', 'it', 'can', 'be', 'too', 'much', 'of', 'a', 'good', 'thing']
예시 12)
from gensim.models import Word2Vec
# vector_size = 워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원.
# window = 컨텍스트 윈도우 크기
# min_count = 단어 최소 빈도 수 제한 (빈도가 적은 단어들은 학습하지 않음)
# workers : 학습을 위한 프로세스 수
# sg : 0->CBOW(중심 단어 학습), 1-> Skip-gram
model = Word2Vec(sentences=result, vector_size=100, window=5, min_count=5, workers=4, sg=0)
예시 13)
# "man"과 가장 유사한 단어들을 찾아 출력
model_result = model.wv.most_similar("man")
print(model_result)
-->
[('woman', 0.8551406264305115), ('guy', 0.813211977481842), ('lady', 0.7696638703346252), ('boy', 0.7585465312004089), ('girl', 0.7354709506034851), ('soldier', 0.7344610691070557), ('gentleman', 0.732011079788208), ('kid', 0.694409966468811), ('rabbi', 0.6887319684028625), ('friend', 0.6641739010810852)]
예시 14)
# "man"이라는 단어의 벡터 표현(임베딩)을 반환
model.wv["man"]
-->
array([ 0.70711213, -3.0656302 , -0.03786955, -0.53291166, 1.610746 ,
0.4325646 , 0.37280777, -0.3823504 , 0.9672379 , -0.03960627,
-1.0338622 , -0.26106957, -0.56583154, 0.02299276, 0.8096229 ,
1.5903952 , 0.21242282, 0.43020007, 0.7092984 , -0.569395 ,
-0.16376378, 1.2447214 , -0.68709785, -0.43976614, 1.3161181 ,
0.44310406, -2.1664813 , -0.3403104 , 0.03237128, -0.7989986 ,
0.3027023 , 0.175262 , 1.5597954 , -0.10356104, -1.3710794 ,
-1.0264354 , -1.0924582 , -0.06081092, -1.2166024 , 0.33448842,
0.71157384, -2.3113868 , -0.28365102, 0.7233219 , 0.63795996,
0.29261348, -0.7817393 , -1.0269821 , -1.5537738 , 0.63793415,
0.19312459, -2.0173266 , -0.6982921 , 1.6465347 , 0.19784413,
-0.71087235, -0.5080577 , 0.24239144, -1.7862254 , 0.43749663,
-1.4379523 , 0.8924807 , 1.6506302 , 0.23143296, -1.7576567 ,
0.58473206, -1.6618357 , 0.59611934, -0.7642342 , 1.1950421 ,
0.50951904, 0.5405965 , 1.3630265 , -1.7718189 , -0.5219222 ,
-1.5455191 , -0.28964567, 0.84063315, -0.4472277 , 1.442106 ,
0.814992 , 0.7029658 , -1.6786414 , 0.8065431 , -0.6937986 ,
-0.24672233, -0.46522966, 0.85966533, -2.0038004 , -1.5008321 ,
0.6527216 , 0.1863872 , 0.27994877, 0.37050998, 1.0230285 ,
0.16083854, 0.02934264, -0.02997349, -2.694541 , 2.5646918 ],
dtype=float32)
예시 15)
# "man" 단어의 임베딩 벡터를 반환
# 해당 벡터의 차원 수(크기)를 확인하는 코드
len(model.wv["man"])
-->
100
예제 16)
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('eng_w2v') # eng_w2v 모델 저장
예제 17)
loaded_model = KeyedVectors.load_word2vec_format('eng_w2v') # 모델 모드
예제 18)
# "man"과 가장 유사한 단어들을 찾기
model_result = loaded_model.most_similar("man")
print(model_result)
# 단어 벡터 행렬의 크기 출력 (단어 개수, 벡터 차원)
print(model.wv.vectors.shape)
--->
[('woman', 0.8551406264305115), ('guy', 0.813211977481842), ('lady', 0.7696638703346252), ('boy', 0.7585465312004089), ('girl', 0.7354709506034851), ('soldier', 0.7344610691070557), ('gentleman', 0.732011079788208), ('kid', 0.694409966468811), ('rabbi', 0.6887319684028625), ('friend', 0.6641739010810852)]
(21613, 100)
### 3-4. NSMC 데이터셋
* NSMC(Naver Sentiment Movie Corpus)는 네이버 영화 리뷰를 기반으로 구축된 한국어 감성 분석 데이터셋으로, 총 200,000개의 리뷰가 포함되어 있습니다.
* 각 리뷰는 긍정(1) 또는 부정(0) 레이블이 지정되어 있어 감성 분석(Sentiment Analysis) 모델을 학습하는 데 활용됩니다.
* NSMC는 한국어 자연어 처리(NLP) 연구 및 머신러닝 모델 훈련에 널리 사용되며, 데이터의 균형이 잘 맞춰져 있어 높은 성능의 감성 분석 모델을 구축하는 데 유용합니다.
* 이 데이터셋은 공개되어 있어, ratings.txt 등의 파일 형식으로 쉽게 다운로드하여 활용할 수 있습니다.
예제 1)
# konlpy 설치
!pip install konlpy
예제 1-1)
# mecab 설치
!pip install mecab-python
예제 1-2)
# KoNLPy의 OKT 등은 형태소 분석 속도가 너무 느립니다. 그래서 Mecab을 설치하여 사용합니다.
# 단, Mecab은 형태소 분석 속도는 빠르지만 설치하는데 시간이 많이 걸립니다.
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
예제 2)
import urllib.request
# 지정된 URL에서 파일 다운로드하여 "ratings.txt"라는 이름으로 저장
urllib.request.urlretrieve(
"https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt",
filename="ratings.txt")
예제 3)
import pandas as pd
# 'ratings.txt' 파일을 읽어와 데이터프레임으로 변환
train_data = pd.read_table('ratings.txt')
# 상위 5개 출력
train_data[:5]--->

예제 4)
# train_data의 문장 길이수
len(train_data)
-->
200000
예제 5)
# 데이터프레임에서 결측값(null) 여부 확인
train_data.isnull().values.any()
-->
True
예제 6)
# 결측값이 포함된 모든 행 제거
train_data = train_data.dropna(how='any')
# 데이터프레임 내 결측값이 남아있는지 확인
# False가 출력되면 정상적으로 제거됨
print(train_data.isnull().values.any())
-->
False
예제 7)
len(train_data)
-->
199992
예제 8)
# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣]", " ", regex=True)
train_data[:5] # 상위 5개 출력--->

예제 9)
# 불용어 제거
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
예제 10)
from konlpy.tag import Mecab
# Mecab 형태소 분석기 초기화
mecab = Mecab()
# 토큰화된 데이터를 저장할 리스트
tokenized_data = []
# 각 문장에 대해 토큰화 및 불용어 제거 수행
for sentence in train_data['document']:
temp_X = mecab.morphs(sentence) # 문장을 형태소 단위로 토큰화
temp_X = [word for word in temp_X if word not in stopwords] # 불용어 제거
tokenized_data.append(temp_X)
# 첫 3개 문장 토큰화 결과 출력
print(tokenized_data[:3])
--->
[['어릴', '때', '보', '지금', '다시', '봐도', '재밌', '어요', 'ㅋㅋ'], ['디자인', '배우', '학생', '으로', '외국', '디자이너', '그', '일군', '전통', '통해', '발전', '해', '문화', '산업', '부러웠', '는데', '사실', '우리', '나라', '에서', '그', '어려운', '시절', '끝', '까지', '열정', '지킨', '노라노', '같', '전통', '있', '어', '저', '같', '사람', '꿈', '꾸', '이뤄나갈', '수', '있', '다는', '것', '감사', '합니다'], ['폴리스', '스토리', '시리즈', '부터', '뉴', '까지', '버릴', '께', '하나', '없', '음', '최고']]
예제 11)
from gensim.models import Word2Vec
# Word2Vec 모델 학습
model = Word2Vec(
sentences=tokenized_data, # 토큰화된 문장 데이터
vector_size=100, # 단어 벡터의 차원 (100차원 벡터)
window=5, # 컨텍스트 윈도우 크기 (앞뒤 5단어 참조)
min_count=5, # 최소 등장 횟수가 5 미만인 단어는 무시
workers=4, # 병렬 처리에 사용할 CPU 코어 수
sg=0 #CBOW 사용
)
예제 12)
# 완성된 임베딩 매트릭스의 크기 확인
model.wv.vectors.shape
-->
(18057, 100)
예제 13)
# 블록버스터의 가장 유사한 단어 10개를 반환
print(model.wv.most_similar('블록버스터'))
-->
[('느와르', 0.8736543655395508), ('무협', 0.8578016757965088), ('스릴러물', 0.8347816467285156), ('액션물', 0.82541424036026), ('헐리우드', 0.8155285120010376), ('슬래셔', 0.8073161840438843), ('공포물', 0.798835039138794), ('첩보', 0.7954245805740356), ('호러', 0.7929490804672241), ('무비', 0.7776992917060852)]
예제 14)
# 벡터(임베딩 값)을 출력하는 코드
model.wv['블록버스터']
-->
array([-0.17943549, 0.3942046 , 0.00261828, -0.19719768, 0.18898825,
-0.67817545, 0.41707784, 0.5119456 , -0.8193383 , -0.2528204 ,
0.33432192, -0.5958742 , -0.09657659, 0.01357029, -0.3343809 ,
0.0164992 , 0.01799522, -0.4048903 , 0.16747278, -0.66768473,
0.3706925 , 0.82681143, -0.32074735, 0.66838646, -0.4220256 ,
0.21034011, 0.17783023, -0.2202476 , -0.31913558, -0.13843092,
-0.5689082 , 0.18111862, 0.23704232, 0.2531697 , 0.2204047 ,
0.47916806, 0.23557925, -0.07890794, -0.14793336, -0.82810324,
0.16082694, -0.44757238, 0.02415501, 0.33585808, 0.40522766,
-0.25235912, 0.40185958, -0.09720332, 0.07100966, 0.21144623,
-0.6152749 , 0.34545717, -0.23572582, 0.34385732, 0.27102223,
-0.5187497 , 0.41155076, -0.70852536, -0.68573624, -0.1002894 ,
0.47879934, -0.18001269, -0.30037197, 0.272582 , -0.0399031 ,
0.11152035, -0.11182719, -0.05736618, -0.71940356, 0.562752 ,
0.50588924, -0.25837246, 0.39108834, -0.7170969 , -0.26347697,
0.50566757, 0.30398783, 0.5104036 , -0.2363494 , 0.13362455,
-0.42766607, 0.27039707, -0.01145587, 0.33756983, -0.30008018,
0.12936103, -0.22846577, 0.45188805, -0.34513453, 0.3423585 ,
-0.37302485, 0.18464011, 0.00234444, -0.04914795, 0.9259163 ,
0.06352068, 0.00418127, -0.41215524, 0.20017141, 0.2770335 ],
dtype=float32)
예제 15)
model.wv.save_word2vec_format('kor_w2v') # 모델 저장
4. FastText
* FastText는 Facebook AI Research(FAIR)에서 개발한 단어 임베딩 및 텍스트 분류 모델로, Word2Vec과 유사하지만 서브워드(subword) 정보를 활용하여 더 강력한 성능을 제공합니다.
* 기존의 단어 임베딩 기법들은 단어 단위로 벡터를 학습하지만, FastText는 단어를 여러 개의 n-그램 문자 조각(character n-grams)으로 분해하여 학습하기 때문에 희귀 단어(OOV, Out-of-Vocabulary) 처리와 형태소 기반 언어(예: 한국어)에서 뛰어난 성능을 보입니다.
* 또한, FastText는 텍스트 분류에도 활용 가능하며, 빠른 속도와 높은 성능 덕분에 감성 분석, 문서 분류, 검색 시스템 등 다양한 자연어 처리(NLP) 작업에서 널리 사용됩니다.

예시 1)
from gensim.models import KeyedVectors
loaded_model = KeyedVectors.load_word2vec_format('eng_w2v') # Word2Vec 모델 로드
예시 2)
# "memory"와 가장 유사한 단어들을 찾기
model_result = loaded_model.most_similar("memory")
print(model_result)
--->
[('brain', 0.6850239038467407), ('vision', 0.6673073172569275), ('perception', 0.6636877059936523), ('body', 0.6588510870933533), ('imagination', 0.6578559279441833), ('consciousness', 0.6576308012008667), ('capability', 0.6350706815719604), ('gut', 0.6297175884246826), ('character', 0.6280694007873535), ('sensory', 0.6273596882820129)]
예시 3)
from gensim.models import FastText
# gensim.models.FastText를 사용하여 FastText 모델을 학습
# vector_size: 생성할 단어 벡터의 차원 수
# window: 컨텍스트 윈도우 크기를 설정. 현재 단어를 기준으로 좌우 몇 개의 단어를 고려할지 정하는 값
# min_count: 코퍼스에서 등장 횟수가 min_count 미만인 단어를 무시
# workers: 병렬 처리를 위한 CPU 코어 개수를 설정
# sg: 학습 알고리즘을 결정하는 Skip-gram(1) / CBOW(0) 선택 옵션
fasttext_model = FastText(result, vector_size=100, window=5, min_count=5, workers=4, sg=1)
예시 4)
# fasttext 모델로 유사한 단어 추출
# 없는 단어여도 유사한 단어 나옴
fasttext_model.wv.most_similar("ryuzy")
-->
[('luggage', 0.7304343581199646),
('bossy', 0.7244004607200623),
('lazy', 0.7135348916053772),
('crappy', 0.7131414413452148),
('lofty', 0.7096861004829407),
('faulty', 0.6999691724777222),
('chatroom', 0.6959043145179749),
('custody', 0.695846438407898),
('ajax', 0.6954141855239868),
('homeopathy', 0.6941580176353455)]
예시 5)
# FastText 모델을 사용하여 "memory"와 가장 유사한 단어 찾기
fasttext_model.wv.most_similar("memory")
-->
[('emory', 0.8943745493888855),
('memo', 0.8319418430328369),
('compulsory', 0.7394804358482361),
('memories', 0.7341772317886353),
('memoir', 0.7250248789787292),
('sensory', 0.7240869402885437),
('brain', 0.7133307456970215),
('memoirs', 0.7056476473808289),
('memorial', 0.7012932896614075),
('receptacle', 0.7007929682731628)]
### 네이버 쇼핑 리뷰 데이터셋
* 네이버 쇼핑 리뷰 데이터를 포함하는 텍스트 파일로, 주로 감성 분석(Sentiment Analysis) 연구에 활용됩니다.
* 이 데이터셋에는 각 리뷰의 내용과 해당 리뷰의 긍정(1) 또는 부정(0) 여부가 라벨로 포함되어 있습니다.
* 텍스트 데이터와 감성 레이블이 짝을 이루고 있어 자연어 처리(NLP) 모델을 훈련하는 데 적합하며, 특히 딥러닝 기반 감성 분석 모델 개발 및 성능 평가에 유용합니다.
* 데이터의 구조는 일반적으로 탭(\t)으로 구분된 두 개의 열(리뷰 텍스트, 감성 라벨)로 구성되어 있으며, 한국어 텍스트 분석 실험에서 널리 사용됩니다.
예제 1)
# ratings_total.txt 파일을 가져옴
urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt", filename="ratings_total.txt")
예제 2)
total_data = pd.read_table('ratings_total.txt', names=['ratings', 'reviews'])
print('전체 리뷰의 개수 : ', len(total_data))
--->
전체 리뷰의 개수 : 200000
예제 3)
total_data[:5] #5개의 데이터 추출
-->--->

예제 4)
# 한글 자음 모음 단위 처리 패키지 설치
!pip install hgtk
예제 5)
import hgtk
# 한글인지 체크
hgtk.checker.is_hangul('ㄱ')
-->
True
예제 6)
import hgtk
# 한글인지 체크
hgtk.checker.is_hangul('10')
-->
False
예제 7)
# 음절을 초성, 중성, 종성으로 분해
hgtk.letter.decompose( '남' )
-->
('ㄴ', 'ㅏ', 'ㅁ')
예제 8)
# 초성, 중성을 결합
hgtk.letter.compose('ㄴ', 'ㅏ', 'ㅁ')
-->
남
예제 9)
# 한글이 아닌 입력에 대해서는 에러 발생
# hgtk.letter.decompose( '1' )
예제 10)
# 결합할 수 없는 상황에서는 에러 발생
# hgtk.letter.compose('ㄴ', 'ㅁ', 'ㅁ')
예제 11)
# # char(음절)을 초성, 중성, 종성으로 분리
def word_to_jamo(token):
def to_special_token(jamo):
if not jamo:
return '-'
else:
return jamo
decomposed_token = ' '
for char in token:
try:
# char(음절)을 초성, 중성, 종성으로 분리
cho, jung, jong = hgtk.letter.decompose(char)
# 자모가 빈 문자일 경우 특수문자 -로 대체
cho = to_special_token(cho)
jung = to_special_token(jung)
jong = to_special_token(jong)
decomposed_token = decomposed_token + cho + jung + jong
# 만약 char(음절)이 한글이 아닐 경우 자모를 나누지 않고 추가
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
decomposed_token += char
# 단어 토큰의 자모 단위 분리 결과를 추가
return decomposed_token
예제 12)
word_to_jamo('남동생')
-->
ㄴㅏㅁㄷㅗㅇㅅㅐㅇ
예제 13)
# '여동생'의 경우 여에 종성이 없으므로 종성의 위치에 특수문자 '-'가 대신 들어감
word_to_jamo('여동생')
--->
ㅇㅕ-ㄷㅗㅇㅅㅐㅇ
예제 14)
# mecab 정의
mecab = Mecab()
# 형태소가 나눠짐
print(mecab.morphs('선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다.'))
--->
['선물', '용', '으로', '빨리', '받', '아서', '전달', '했어야', '하', '는', '상품', '이', '었', '는데', '머그', '컵', '만', '와서', '당황', '했', '습니다', '.']
예제 15)
# mecab이용해 형태소 분석을 나눔
def tokenize_by_jamo(s):
return [word_to_jamo(token) for token in mecab.morphs(s)]
예제 16)
print(tokenize_by_jamo('선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다.'))
-->
[' ㅅㅓㄴㅁㅜㄹ', ' ㅇㅛㅇ', ' ㅇㅡ-ㄹㅗ-', ' ㅃㅏㄹㄹㅣ-', ' ㅂㅏㄷ', ' ㅇㅏ-ㅅㅓ-', ' ㅈㅓㄴㄷㅏㄹ', ' ㅎㅐㅆㅇㅓ-ㅇㅑ-', ' ㅎㅏ-', ' ㄴㅡㄴ', ' ㅅㅏㅇㅍㅜㅁ', ' ㅇㅣ-', ' ㅇㅓㅆ', ' ㄴㅡㄴㄷㅔ-', ' ㅁㅓ-ㄱㅡ-', ' ㅋㅓㅂ', ' ㅁㅏㄴ', ' ㅇㅘ-ㅅㅓ-', ' ㄷㅏㅇㅎㅘㅇ', ' ㅎㅐㅆ', ' ㅅㅡㅂㄴㅣ-ㄷㅏ-', ' .']
예제 17)
from tqdm import tqdm # 진행 상황을 표시하는 tqdm 라이브러리
tokenized_data = [] # 토큰화된 데이터를 저장할 tokenized_data 리스트
# total_data의 'reviews' 열에 있는 모든 리뷰를 리스트로 변환한 후 반복문 실행
for sample in tqdm(total_data['reviews'].to_list()):
tokenzied_sample = tokenize_by_jamo(sample) # 각 리뷰를 자소(한글의 초성, 중성, 종성) 단위로 토큰화
tokenized_data.append(tokenzied_sample)tokenized_data[:2] # 토큰화된 리뷰를 리스트에 추가
-->
100%|██████████| 200000/200000 [00:56<00:00, 3550.53it/s]
[' ㅂㅐ-ㄱㅗㅇ', ' ㅃㅏ-ㄹㅡ-', ' ㄱㅗ-', ' ㄱㅜㅅ']
예제 18)
tokenized_data[:2] # 자소 단위로 토큰화된 리뷰 데이터 중 첫 두 개의 샘플을 확인
--->
[[' ㅂㅐ-ㄱㅗㅇ', ' ㅃㅏ-ㄹㅡ-', ' ㄱㅗ-', ' ㄱㅜㅅ'],
[' ㅌㅐㄱㅂㅐ-',
' ㄱㅏ-',
' ㅇㅓㅇㅁㅏㅇ',
' ㅇㅣ-',
' ㄴㅔ-',
' ㅇㅛㅇ',
' ㅈㅓ-ㅎㅢ-',
' ㅈㅣㅂ',
' ㅁㅣㅌ',
' ㅇㅔ-',
' ㅊㅡㅇ',
' ㅇㅔ-',
' ㅁㅏㄹ',
' ㄷㅗ-',
' ㅇㅓㅄㅇㅣ-',
' ㄴㅘ-ㄷㅜ-',
' ㄱㅗ-',
' ㄱㅏ-',
' ㄱㅗ-']]
예제 19)
# 초성, 중성, 종성을 하나의 단어 원복
def jamo_to_word(jamo_sequence):
tokenized_jamo = []
index = 0
# 1. 초기 입력
# jamo_sequence = 'ㄴㅏㅁㄷㅗㅇㅅㅐㅇ'
while index < len(jamo_sequence):
# 문자가 한글(정상적인 자모)이 아닐 경우
if not hgtk.checker.is_hangul(jamo_sequence[index]):
tokenized_jamo.append(jamo_sequence[index])
index = index + 1
# 문자가 정상적인 자모라면 초성, 중성, 종성을 하나의 토큰으로 간주.
else:
tokenized_jamo.append(jamo_sequence[index:index + 3])
index = index + 3
# 2. 자모 단위 토큰화 완료
# tokenized_jamo : ['ㄴㅏㅁ', 'ㄷㅗㅇ', 'ㅅㅐㅇ']
word = ' '
try:
for jamo in tokenized_jamo:
# 초성, 중성, 종성의 묶음으로 추정되는 경우
if len(jamo) == 3:
if jamo[2] == "-":
# 종성이 존재하지 않는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1])
else:
# 종성이 존재하는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1], jamo[2])
# 한글이 아닌 경우
else:
word = word + jamo
# 복원 중(hgtk.letter.compose) 에러 발생 시 초기 입력 리턴.
# 복원이 불가능한 경우 예시) 'ㄴ!ㅁㄷㅗㅇㅅㅐㅇ'
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
return jamo_sequence
# 3. 단어로 복원 완료
# word : '남동생'
return word
예제 20)
jamo_to_word('ㄴㅏㅁㄷㅗㅇㅅㅐㅇ')
-->
남동생
jamo_to_word('ㅇㅕㄷㅗㅇㅅㅐㅇ')
--->
여동생
예제 21)
with open('tokenized_data.txt', 'w') as out: # 'tokenized_data.txt' 파일을 쓰기 모드('w')로 열기
for line in tqdm(tokenized_data, unit=' line'): # tokenized_data 리스트를 tqdm을 이용해 진행 상황을 표시하며 반복
out.write(' '.join(line) + '\n') # 리스트의 요소를 공백(' ')으로 결합한 후 한 줄씩 파일에 저장
-->
100%|██████████| 200000/200000 [00:00<00:00, 219451.09 line/s]
예제 22)
# fasttext 설치
# 링크 참고 주소: https://fasttext.cc/
!pip install fasttext
예제 23)
import fasttext
model = fasttext.train_unsupervised('tokenized_data.txt', model='cbow') #cbow 모델 사용
# fasttext 모델 저장
model.save_model("fasttext.bin")
예제 24)
model = fasttext.load_model("fasttext.bin") # FastText 모델을 로드
예제 25)
model[word_to_jamo('남동생')] # 'ㄴㅏㅁㄷㅗㅇㅅㅐㅇ'=
-->
array([ 0.06881193, 0.46409658, 0.6201144 , -0.53205323, -0.7990429 ,
-0.43609542, 0.04508325, 0.37639132, -0.20250046, -0.27571827,
0.49753788, 0.22276217, -0.07992327, 0.29399773, -0.20415968,
0.44907668, -0.04511647, 0.38043717, -0.5729385 , 0.3929882 ,
0.3401508 , -0.23465014, 0.44995263, 0.08280965, -0.24787846,
-0.2364622 , 0.3514328 , 0.86882794, 0.59662676, -0.44243222,
0.39046204, -0.50936735, -0.05598381, -0.42085114, 0.989837 ,
-0.07849521, -0.36060423, -0.23123227, -0.11956828, 0.05702078,
0.3134898 , -0.05014214, 0.08784023, 0.1519918 , -0.1497325 ,
-0.48227534, 0.24827231, 0.03652729, 0.31146353, -0.13264701,
-0.13857359, 0.10309521, 0.4143464 , 0.08803598, -1.150035 ,
0.21282524, 0.46230862, 0.28479695, -0.5982305 , -0.08765033,
0.05279728, -0.7535788 , 0.03621546, 0.57393533, 0.18058532,
-0.12626365, -0.28072837, 0.01715335, -0.06468349, 0.04962476,
-0.18334049, -0.52223384, 0.49405518, 0.14645305, -0.11062121,
-0.32860908, 0.04056694, 0.11791224, 0.6430529 , 0.25325587,
0.843013 , 0.5833066 , -0.34248713, 0.3211564 , 0.41314322,
0.39392355, -0.29418227, -0.42102844, 0.13860649, -0.18966654,
0.5177464 , -0.27351454, -0.03542611, -0.8310001 , 0.01631775,
0.7136345 , 0.0969404 , 0.64753175, -0.4567953 , 0.02376243],
dtype=float32)
예제 26)
# 남동생이랑 비슷한 단어 10개 추출
model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)
-->
[(0.9439091682434082, 'ㄷㅗㅇㅅㅐㅇ'),
(0.9435627460479736, 'ㄴㅏㅁㄷㅗㅇㅅㅐㅇ'),
(0.8103119134902954, 'ㅊㅣㄴㄱㅜ-'),
(0.7887588739395142, 'ㅅㅐㅇㅇㅣㄹ'),
(0.7567143440246582, 'ㅈㅗ-ㅋㅏ-'),
(0.7481465339660645, 'ㅇㅓㄴㄴㅣ-'),
(0.7309936285018921, 'ㅅㅓㄴㅁㅜㄹ'),
(0.6996868252754211, 'ㅎㅏㄱㅅㅐㅇ'),
(0.6975082755088806, 'ㅅㅓㄴㅅㅐㅇ'),
(0.6918007731437683, 'ㅈㅜㅇㅎㅏㄱㅅㅐㅇ')]
예제 27)
# FastText에서 검색한 유사 단어 리스트를 변환하는 역할
def transform(word_sequence):
return [(jamo_to_word(word), similarity) for (similarity, word) in word_sequence]
예제 28)
# 변환된 자모를 사용하여 모델에서 가장 가까운 10개의 이웃을 찾음
# model.get_nearest_neighbors 함수는 주어진 자모에 대해 k개의 가장 유사한 이웃을 반환
# 찾은 이웃들을 transform 함수를 통해 변환
# transform 함수는 이웃의 결과를 원하는 형식으로 가공
# 그 결과를 변환하여 출력하는 역할
print(transform(model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)))
--->
[('동생', 0.9439091682434082), ('남동생', 0.9435627460479736), ('친구', 0.8103119134902954), ('생일', 0.7887588739395142), ('조카', 0.7567143440246582), ('언니', 0.7481465339660645), ('선물', 0.7309936285018921), ('학생', 0.6996868252754211), ('선생', 0.6975082755088806), ('중학생', 0.6918007731437683)]
예제 29)
# 변환된 자모를 사용하여 모델에서 가장 가까운 10개의 이웃을 찾음
# model.get_nearest_neighbors 함수는 주어진 자모에 대해 k개의 가장 유사한 이웃을 반환
# 찾은 이웃들을 transform 함수를 통해 변환
# transform 함수는 이웃의 결과를 원하는 형식으로 가공
# 그 결과를 변환하여 출력하는 역할
print(transform(model.get_nearest_neighbors(word_to_jamo('남동쉥'), k=10)))
--->
[('남동생', 0.8029886484146118), ('동생', 0.7408527731895447), ('생일', 0.7085868716239929), ('친구', 0.6699411869049072), ('담사', 0.6550007462501526), ('선물', 0.6484431624412537), ('언니', 0.6375815272331238), ('어머님께', 0.6213593482971191), ('어버이날', 0.6177435517311096), ('친정집', 0.6108354330062866)]
예제 30)
print(transform(model.get_nearest_neighbors(word_to_jamo('제품^^'), k=10)))
-->
[('제품', 0.9144989252090454), ('타제품', 0.8391847610473633), ('반제품', 0.8226320147514343), ('완제품', 0.8074551820755005), ('화학제품', 0.7550960183143616), ('상품', 0.7543852925300598), ('재품', 0.7495331764221191), ('최상품', 0.7241946458816528), ('제풍', 0.6867669224739075), ('중품', 0.6769265532493591)]
5. GloVe
* GloVe(Global Vectors for Word Representation)는 Stanford University에서 개발한 단어 임베딩 기법으로, 단어의 의미를 벡터 형태로 표현하는 방법입니다.
* GloVe는 단순한 윈도우 기반의 주변 단어 관계를 학습하는 Word2Vec과 달리, 전체 코퍼스에서 동시 발생 행렬(Co-occurrence Matrix)을 기반으로 단어 간의 통계적 관계를 학습합니다.
* 즉, 단어와 단어가 함께 등장하는 빈도를 분석하여 의미적으로 유사한 단어들이 가까운 벡터 공간에서 배치되도록 합니다.
* 이러한 방식은 단어 간의 유사성을 효과적으로 캡처할 뿐만 아니라, 선형 관계(예: "king - man + woman ≈ queen")도 잘 반영합니다.
* GloVe는 사전 학습된 벡터를 제공하여 NLP 태스크에서 전이 학습이 가능하며, 감성 분석, 기계 번역 등 다양한 자연어 처리 작업에 활용됩니다
논문은 대략 12개의 페이지로 구성
논문 링크 : https://nlp.stanford.edu/pubs/glove.pdf
현재 GloVe는 많이 쓰이지 않아 중단되어 간단히 설명 붙혀놓았습니다.
### 동시 발생 행렬 만들기
```
I like deep learning.
I like NLP.
I enjoy learning NLP.
```




'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 6. RNN(Recurrent Neural Network, RNN) (0) | 2025.02.06 |
|---|---|
| 5. CNN Text Classification (0) | 2025.02.06 |
| 3. 벡터화 (0) | 2025.02.03 |
| 2. IMDB Dataset를 활용한 데이터 전처리 (0) | 2025.01.24 |
| 1. 자연어 처리 (2) | 2025.01.23 |