1. RNN
* 순환 신경망(Recurrent Neural Network, RNN)은 시퀀스 데이터(Sequence Data)를 처리하는 데 특화된 신경망 구조로, 이전 상태(hidden state)를 다음 시점(time step)으로 전달하여 시계열 데이터, 자연어 처리(NLP), 음성 인식 등에 활용됩니다.
* 일반적인 인공 신경망(ANN)과 달리 RNN은 가변 길이의 입력을 다룰 수 있으며, 시퀀스 간의 의존성을 학습할 수 있습니다.
* 그러나 일반적인 RNN은 장기 의존성(Long-Term Dependency) 문제로 인해 학습이 어려울 수 있으며, 이를 해결하기 위해 장단기 메모리(Long Short-Term Memory, LSTM)나 게이트 순환 유닛(Gated Recurrent Unit, GRU)과 같은 변형 모델이 개발되었습니다.
* RNN은 기계 번역, 감성 분석, 음성 합성 등 다양한 분야에서 활용되며, 현재는 트랜스포머(Transformer) 모델이 등장하면서 점점 대체되고 있는 추세입니다.
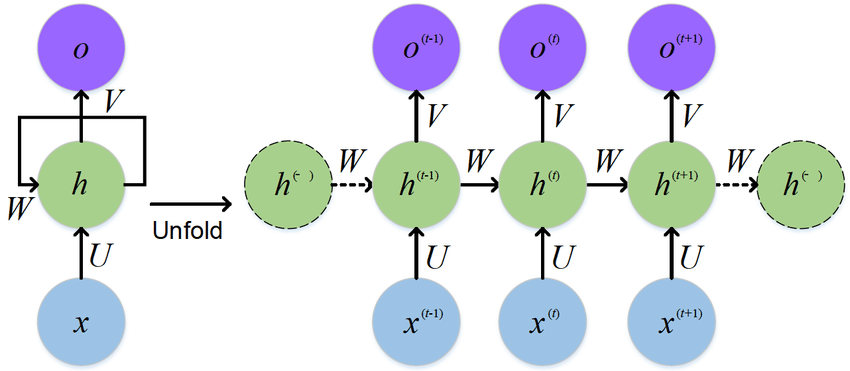



2. 간단한 RNN 모델 직접 구현하기
예시 1)
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import requests
# GPU 사용 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
예시 2)
# 외부 데이터 가져오기
url = "https://raw.githubusercontent.com/dscape/spell/master/test/resources/big.txt"
response = requests.get(url)
data = response.text.lower().split(".\n")[:50] # 상위 50개 문장 사용으로 수정 사이즈 때문에 수정
예시 3)
# 문자 집합 생성
char_set = list(set("".join(data))) # 리스트로 저장해서 char_set 에 저장
char_dic = {c: i for i, c in enumerate(char_set)} # char_dic 생성
input_size = len(char_set) # 입력 차원
hidden_size = 128 # 은닉 상태 크기 증가
output_size = len(char_set) # 출력 차원
sequence_length = 20 # 입력 시퀀스 길이 증가
learning_rate = 0.01
예시 4)
# 학습 데이터 준비
train_X, train_Y = [], [] # 입력(X)과 출력(Y) 데이터를 저장할 리스트 초기화
for sentence in data: # 주어진 데이터(문장 리스트)에서 각 문장을 순회
for i in range(len(sentence) - sequence_length): # 문장의 길이에서 시퀀스 길이만큼 빼고 반복
seq_in = sentence[i:i+sequence_length] # 입력 시퀀스: 현재 위치에서 sequence_length 길이만큼 추출
seq_out = sentence[i+1:i+sequence_length+1] # 출력 시퀀스: 입력 시퀀스를 한 글자씩 뒤로 이동한 형태
# 문자(char)를 숫자(index)로 변환하여 저장
train_X.append([char_dic[c] for c in seq_in])
train_Y.append([char_dic[c] for c in seq_out])
# 최종적으로 생성된 입력(X)과 출력(Y) 데이터의 크기 출력
print(len(train_X))
print(len(train_Y))
-->
35658
35658
예시 5)
print(train_X[:10])
-->
[[12, 30, 25, 2, 47, 41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41], [30, 25, 2, 47, 41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0], [25, 2, 47, 41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2], [2, 47, 41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25], [47, 41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51], [41, 9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51, 9], [9, 34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51, 9, 9], [34, 25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51, 9, 9, 38], [25, 27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51, 9, 9, 38, 2], [27, 12, 2, 0, 44, 12, 25, 11, 51, 25, 41, 0, 2, 25, 51, 9, 9, 38, 2, 9]]
예시 6)
import torch # PyTorch 라이브러리 임포트
# 입력 데이터(train_X)를 PyTorch 텐서로 변환
# - dtype=torch.float32: 부동소수점(float) 형식으로 변환 (신경망의 입력 데이터는 일반적으로 float)
# - .to(device): 데이터가 GPU 또는 CPU에서 처리될 수 있도록 지정된 장치(device)로 이동
train_X = torch.tensor(train_X, dtype=torch.float32).to(device)
# 출력 데이터(train_Y)를 PyTorch 텐서로 변환
# - dtype=torch.int64: 정수(int) 형식으로 변환 (CrossEntropyLoss 같은 PyTorch의 손실 함수는 정수 라벨을 필요로 함)
# - .to(device): 지정된 장치(GPU 또는 CPU)로 이동
train_Y = torch.tensor(train_Y, dtype=torch.int64).to(device)
예시 7)
import torch
import torch.nn as nn
# 간단한 RNN 모델 정의
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__() # nn.Module의 생성자 호출
# RNN 레이어 정의
# - input_size: 입력 벡터의 크기 (특징 차원 수)
# - hidden_size: 은닉 상태(hidden state) 크기
# - batch_first=True: 입력 데이터의 차원 순서를 (batch_size, sequence_length, input_size)로 설정
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# 출력층 (fully connected layer)
# - hidden_size 크기의 RNN 출력을 output_size 크기의 벡터로 변환
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 초기 은닉 상태 정의
# - h0: (num_layers=1, batch_size, hidden_size) 크기의 텐서
# - .to(device): GPU 또는 CPU로 이동
h0 = torch.zeros(1, x.size(0), hidden_size).to(device)
# RNN 레이어 순전파 수행
# - out: 모든 시퀀스 타임스텝에 대한 출력 (batch_size, sequence_length, hidden_size)
# - _: 마지막 타임스텝의 은닉 상태 (batch_size, hidden_size) → 사용하지 않으므로 `_`로 처리
out, _ = self.rnn(x, h0)
# RNN 출력을 fully connected layer에 전달하여 최종 예측값 계산
# - (batch_size, sequence_length, hidden_size) → (batch_size, sequence_length, output_size)
out = self.fc(out)
return out # 최종 출력 반환
예시 8)
# 초기 은닉 상태(h0)를 0으로 설정
# torch.zeros(1, len(char_set), hidden_size)
# - 1: RNN의 레이어 수 (num_layers=1)
# - len(char_set): 배치 크기 (보통 batch_size가 들어가야 하는데, 여기서는 문자 집합 크기)
# - hidden_size: RNN의 은닉 상태(hidden state) 크기
# - .to(device): GPU 또는 CPU에서 실행되도록 장치로 이동
h0 = torch.zeros(1, len(char_set), hidden_size).to(device)
--->
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
예시 9)
# 모델 생성 및 GPU로 이동
model = SimpleRNN(input_size, hidden_size, output_size).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
예시 10)
# 입력 데이터를 원-핫 인코딩
# - one_hot_x: (batch_size, sequence_length, input_size) 크기의 0으로 초기화된 텐서
# - len(train_X): batch_size (입력 데이터 개수)
# - sequence_length: 시퀀스 길이
# - input_size: 입력 특성(원-핫 벡터 크기, 즉 문자 집합 크기)
one_hot_x = torch.zeros(len(train_X), sequence_length, input_size).to(device)
# 각 문장을 원-핫 벡터로 변환
for i, seq in enumerate(train_X.int()): # train_X의 각 시퀀스에 대해 반복
for j, idx in enumerate(seq): # 각 시퀀스의 문자 인덱스에 대해 반복
one_hot_x[i, j, idx] = 1 # 해당 위치(idx)에 1을 설정 (원-핫 인코딩)
예시 11)
num_epochs = 2000 # 전체 학습 반복 횟수 설정
for epoch in range(num_epochs): # 0부터 num_epochs-1까지 학습 반복
optimizer.zero_grad() # 이전 epoch의 기울기(gradient) 초기화
output = model(one_hot_x) # 모델의 순전파(forward) 수행
# output.shape: (batch_size, sequence_length, output_size)
# 손실(loss) 계산
# - output.view(-1, output_size): (batch_size * sequence_length, output_size)로 변환
# - train_Y.view(-1): (batch_size * sequence_length)로 변환 (정답 라벨)
loss = criterion(output.view(-1, output_size), train_Y.view(-1))
loss.backward() # 역전파 수행 (기울기 계산)
optimizer.step() # 최적화(가중치 업데이트)
# 100 에포크마다 손실 출력
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
-->
Epoch [100/2000], Loss: 2.0786
Epoch [200/2000], Loss: 1.7719
Epoch [300/2000], Loss: 1.6031
Epoch [400/2000], Loss: 1.4588
Epoch [500/2000], Loss: 1.3748
Epoch [600/2000], Loss: 1.3089
Epoch [700/2000], Loss: 1.2941
Epoch [800/2000], Loss: 1.2394
Epoch [900/2000], Loss: 1.2184
Epoch [1000/2000], Loss: 1.2002
Epoch [1100/2000], Loss: 1.1891
Epoch [1200/2000], Loss: 1.1923
Epoch [1300/2000], Loss: 1.1679
Epoch [1400/2000], Loss: 1.1614
Epoch [1500/2000], Loss: 1.1559
Epoch [1600/2000], Loss: 1.1508
Epoch [1700/2000], Loss: 1.1466
Epoch [1800/2000], Loss: 1.1335
Epoch [1900/2000], Loss: 1.1438
Epoch [2000/2000], Loss: 1.1246
예시 12)
# 예측 테스트 (추론 단계)
with torch.no_grad(): # 그래디언트 계산 비활성화 (메모리 절약 및 속도 향상)
test_input = one_hot_x[0].unsqueeze(0).to(device) # 첫 번째 입력 샘플 선택 및 배치 차원 추가
# test_input.shape: (1, sequence_length, input_size) (batch_size=1)
test_output = model(test_input) # 모델을 통해 예측 수행
# test_output.shape: (1, sequence_length, output_size)
# 예측 결과에서 가장 높은 확률을 가진 인덱스 선택
predicted_indices = torch.argmax(test_output, dim=2)
# predicted_indices.shape: (1, sequence_length)
# 인덱스를 실제 문자로 변환
predicted_chars = [char_set[idx] for idx in predicted_indices.squeeze().cpu()]
# 최종 예측된 문자 시퀀스 출력
print("Predicted sequence:", ''.join(predicted_chars))
-->
# 성능은 좋지 않지만 비슷하게 나왔음
# the project gutenberg ebook 원본 문장
Predicted sequence: he caoject gutenberg
* 현재 모델은 입력된 문자 패턴을 보고 가장 확률이 높은 다음 문자들을 예측함.
* 학습 데이터에서 자주 등장한 문장을 우선적으로 예측하는 경향이 있음.
* 데이터가 적거나 RNN을 사용하면 짧은 패턴을 반복하는 문제가 발생할 수 있음.
* 데이터 증가, LSTM 사용, Temperature Sampling 적용을 통해 예측 다양성을 높일 수 있음.
예시 1)
data[0]
-->
the project gutenberg ebook of the adventures of sherlock holmes
by sir arthur conan doyle
(#15 in our series by sir arthur conan doyle)
copyright laws are changing all over the world. be sure to check the
copyright laws for your country before downloading or redistributing
this or any other project gutenberg ebook
예시 2)
train_X[0]
-->
tensor([12., 30., 25., 2., 47., 41., 9., 34., 25., 27., 12., 2., 0., 44.,
12., 25., 11., 51., 25., 41.], device='cuda:0')
예시 3)
one_hot_x[0]
-->
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 1., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0')'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 7. LSTM과 GRU (0) | 2025.02.10 |
|---|---|
| 6-2. RNN 활용 (0) | 2025.02.10 |
| 5. CNN Text Classification (0) | 2025.02.06 |
| 4. 신경망 기반의 벡터화 (4) | 2025.02.05 |
| 3. 벡터화 (0) | 2025.02.03 |