##**1.Multi-class Weather Dataset**
* Multi-class Weather Dataset은 다양한 기상 조건을 포함하는 이미지 데이터셋으로, 주로 기계 학습 및 딥러닝 모델을 학습하거나 평가하는 데 사용됩니다.
* 이 데이터셋은 맑음, 비, 눈, 흐림과 같은 여러 날씨 유형으로 라벨이 지정된 다중 클래스 분류 문제를 다룹니다.
* 각 클래스는 다양한 시간대, 계절, 지역에서 촬영된 이미지를 포함하여 현실 세계의 다양성을 반영하도록 설계되었습니다.
* 이를 통해 모델은 날씨 조건을 정확히 분류하고, 기상 관측, 자동화된 날씨 보고, 혹은 자율주행 차량의 환경 인식 시스템과 같은 다양한 응용 분야에서 활용될 수 있습니다.
링크 주소 : https://www.kaggle.com/datasets/pratik2901/multiclass-weather-dataset
Multi-class Weather Dataset
Image Dataset provides a platform for recognizing different weather conditions.
www.kaggle.com
1.Collab 으로 돌릴시, GPU로 돌려야합니다.

예시 1)
#zip파일을 임시로 받아온다
!kaggle datasets download pratik2901/multiclass-weather-dataset
예시 2)
import os
import zipfile
import random
from shutil import copyfile, rmtree
zip_file = 'multiclass-weather-dataset.zip'
base_dir = 'Multi-class Weather Dataset'
train_dir = './train'
test_dir = './test'
extract_path = '.' # 폴더 생성 없이 현재 디렉터리에 압축 해제
예제 3)
import zipfile
# zip_file은 압축 파일의 경로입니다.
# extract_path는 압축을 풀어낸 파일들이 저장될 경로입니다.
with zipfile.ZipFile(zip_file, 'r') as zip_ref: # 'r' 모드는 읽기 전용으로 zip 파일을 엽니다.
zip_ref.extractall(extract_path) # 압축 파일의 모든 내용을 extract_path 경로로 추출합니다.
예제 4)
import os
from shutil import rmtree
# 분류 디렉토리 목록: 이미지 분류를 위해 사용할 카테고리(클래스) 이름을 정의
categories = ['Cloudy', 'Rain', 'Shine', 'Sunrise']
# train_dir: 학습 데이터가 저장될 디렉토리 경로
# test_dir: 테스트 데이터가 저장될 디렉토리 경로
# 학습 데이터 디렉토리가 존재하는 경우, 삭제
if os.path.exists(train_dir): # train_dir 경로가 실제로 존재하는지 확인
rmtree(train_dir) # 디렉토리 및 내부 파일을 모두 삭제
# 테스트 데이터 디렉토리가 존재하는 경우, 삭제
if os.path.exists(test_dir): # test_dir 경로가 실제로 존재하는지 확인
rmtree(test_dir) # 디렉토리 및 내부 파일을 모두 삭제
예제 5)
# train, test 폴더 및 하위 카테고리 폴더 생성
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
예제 6)
import os
# categories: 분류 작업에 사용될 카테고리 목록
# train_dir: 학습 데이터가 저장될 디렉토리 경로
# test_dir: 테스트 데이터가 저장될 디렉토리 경로
for category in categories: # 각 카테고리별로 디렉토리를 생성
# 학습 데이터 디렉토리 내부에 해당 카테고리 디렉토리 생성
os.makedirs(os.path.join(train_dir, category), exist_ok=True)
# 테스트 데이터 디렉토리 내부에 해당 카테고리 디렉토리 생성
os.makedirs(os.path.join(test_dir, category), exist_ok=True)
예제 7)
import os
import random
from shutil import copyfile
# 각 카테고리별 데이터 파일 나누기
for category in categories: # 각 카테고리에 대해 반복
category_path = os.path.join(base_dir, category) # 원본 데이터가 저장된 경로
files = os.listdir(category_path) # 해당 카테고리 디렉토리 내 모든 파일 목록
# 데이터를 섞기
random.shuffle(files) # 파일 순서를 랜덤하게 섞음
# 데이터를 8:2로 나누기
split_idx = int(len(files) * 0.8) # 전체 파일 중 80%를 학습 데이터로 설정
train_files = files[:split_idx] # 학습 데이터 파일 목록
test_files = files[split_idx:] # 테스트 데이터 파일 목록
# 학습 데이터 파일 복사
for file in train_files: # 학습 데이터 파일 목록을 순회
src = os.path.join(category_path, file) # 원본 파일 경로
dst = os.path.join(train_dir, category, file) # 학습 데이터 저장 경로
copyfile(src, dst) # 파일 복사
# 테스트 데이터 파일 복사
for file in test_files: # 테스트 데이터 파일 목록을 순회
src = os.path.join(category_path, file) # 원본 파일 경로
dst = os.path.join(test_dir, category, file) # 테스트 데이터 저장 경로
copyfile(src, dst) # 파일 복사
print('데이터 분리가 완료되었습니다.') # 데이터 분리 완료 메시지 출력
예제 8)
# PyTorch 라이브러리 임포트
import torch # PyTorch의 핵심 라이브러리
import torchvision # PyTorch에서 컴퓨터 비전을 위한 라이브러리
import torchvision.transforms as transforms # 데이터 변환(전처리)을 위한 모듈
import torchvision.models as models # 사전 학습된 모델을 제공하는 모듈
import torchvision.datasets as datasets # 데이터셋 관련 모듈
# PyTorch에서 학습과 최적화를 위한 모듈
import torch.optim as optim # 최적화 알고리즘 (e.g., SGD, Adam 등)
import torch.nn as nn # 신경망 구조 정의를 위한 모듈
import torch.nn.functional as F # 신경망에서 사용할 함수(예: 활성화 함수)
# 데이터 로딩 및 분할을 위한 모듈
from torch.utils.data import random_split # 데이터셋을 랜덤하게 분리하는 함수
from torch.utils.data import DataLoader # 데이터를 배치 단위로 로드하는 유틸리티
# 데이터 시각화를 위한 유틸리티
from torchvision.utils import make_grid # 여러 이미지를 격자로 정렬하여 시각화
# Matplotlib 라이브러리 임포트 (시각화를 위해 사용)
import matplotlib.pyplot as plt # 그래프 및 이미지 시각화
import matplotlib.image as image # 이미지를 다루기 위한 유틸리티
# Numpy 라이브러리 임포트 (수치 연산을 위해 사용)
import numpy as np # 다차원 배열 및 수치 계산
# 시간 측정을 위한 모듈
import time # 코드 실행 시간을 측정하기 위한 유틸리티
예제 9)
from torchvision import transforms
# 학습 데이터 변환을 위한 전처리 설정
transform_train = transforms.Compose([ # 여러 변환 작업을 순차적으로 적용
transforms.Resize((256, 256)), # 이미지를 256x256 크기로 리사이즈
transforms.RandomHorizontalFlip(), # 랜덤으로 이미지를 좌우반전 (50% 확률)
transforms.ToTensor(), # 이미지를 Tensor 형식으로 변환 (픽셀 값 [0, 255] → [0, 1])
transforms.Normalize( # 이미지를 정규화 (픽셀 값을 평균과 표준편차로 정규화)
mean=[0.5, 0.5, 0.5], # R, G, B 채널별 평균값
std=[0.5, 0.5, 0.5] # R, G, B 채널별 표준편차
)
])
# 테스트 데이터 변환을 위한 전처리 설정
transform_test = transforms.Compose([ # 테스트 데이터에 적용할 변환
transforms.Resize((256, 256)), # 이미지를 256x256 크기로 리사이즈
transforms.ToTensor(), # 이미지를 Tensor 형식으로 변환 (픽셀 값 [0, 255] → [0, 1])
transforms.Normalize( # 이미지를 정규화
mean=[0.5, 0.5, 0.5], # R, G, B 채널별 평균값
std=[0.5, 0.5, 0.5] # R, G, B 채널별 표준편차
)
])
### transforms.ToTensor()
* 이미지를 PyTorch 텐서(tensor)로 변환합니다.
* 이미지의 픽셀 값을 [0, 255] 범위에서 [0.0, 1.0] 범위로 정규화합니다.
* 이미지의 차원을 (H, W, C) 형식에서 PyTorch에서 사용하는 (C, H, W) 형식으로 바꿉니다.
* H: 이미지의 높이 (Height)
* W: 이미지의 너비 (Width)
* C: 채널(Channel; 예: RGB 이미지의 경우 3)
### transforms.Normalize(mean, std)
* 텐서로 변환된 이미지의 픽셀 값을 정규화(normalization)합니다.
* mean: 각 채널(R, G, B)의 평균값.
* std: 각 채널의 표준편차.
* mean=[0.5, 0.5, 0.5]: R, G, B 채널 각각의 평균을 0.5로 설정.
* std=[0.5, 0.5, 0.5]: R, G, B 채널 각각의 표준편차를 0.5로 설정.
* 이 정규화는 일반적으로 픽셀 값의 범위를 [−1,1][-1, 1][−1,1]로 조정하기 위해 사용됩니다. (픽셀 값이 [0,1][0, 1][0,1]로 변환된 상태에서)
예시 1)
from torchvision import datasets
# 학습 데이터셋 생성
train_dataset = datasets.ImageFolder(
root='train/', # 학습 데이터가 저장된 디렉토리 경로
transform=transform_train # 학습 데이터에 적용할 전처리(transform_train)
)
# 학습 데이터셋의 전체 크기 확인
dataset_size = len(train_dataset) # 전체 데이터셋의 이미지 개수
# 학습 데이터와 검증 데이터를 8:2로 분리
train_size = int(dataset_size * 0.8) # 학습 데이터의 크기 (전체 데이터의 80%)
val_size = dataset_size - train_size # 검증 데이터의 크기 (전체 데이터의 나머지 20%)
### ImageFolder
* datasets.ImageFolder는 이미지 데이터를 특정 디렉터리 구조에서 로드하는 클래스입니다.
* 디렉터리 이름을 레이블(class label)로 간주하며, 각 디렉터리 내의 이미지 파일들을 해당 레이블에 할당합니다.
* 이 클래스는 이미지 데이터를 PyTorch 데이터셋(Dataset) 형식으로 변환하므로, DataLoader와 함께 사용하여 배치 처리 및 데이터 증강(data augmentation)을 쉽게 적용할 수 있습니다.
예시 1)
from torch.utils.data import random_split
from torchvision import datasets
# 학습 데이터셋(train_dataset)을 학습 데이터와 검증 데이터로 분리
train_dataset, val_dataset = random_split(
train_dataset, # 전체 데이터셋
[train_size, val_size] # 학습 데이터와 검증 데이터의 크기 비율 (8:2)
)
# 테스트 데이터셋 생성
test_dataset = datasets.ImageFolder(
root='test/', # 테스트 데이터가 저장된 디렉토리 경로
transform=transform_test # 테스트 데이터에 적용할 전처리(transform_test)
)
예시 2)
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 학습 데이터 로더 생성
train_dataloader = DataLoader(
train_dataset, # 학습 데이터셋
batch_size=64, # 한 번에 처리할 데이터 배치 크기
shuffle=True # 데이터를 매 에포크마다 랜덤하게 섞음 (학습 성능 향상)
)
# 검증 데이터 로더 생성
val_dataloader = DataLoader(
val_dataset, # 검증 데이터셋
batch_size=64, # 한 번에 처리할 데이터 배치 크기
shuffle=True # 데이터를 랜덤하게 섞음 (검증 데이터의 다양성 확보)
)
# 테스트 데이터 로더 생성
test_dataloader = DataLoader(
test_dataset, # 테스트 데이터셋
batch_size=64, # 한 번에 처리할 데이터 배치 크기
shuffle=False # 테스트 데이터는 섞지 않음 (결과의 일관성 유지)
)
# Matplotlib 시각화 설정
plt.rcParams['figure.figsize'] = [12, 8] # 그래프의 기본 크기 (가로 12인치, 세로 8인치)
plt.rcParams['figure.dpi'] = 60 # 그래프의 해상도 설정 (DPI: Dot Per Inch)
plt.rcParams.update({'font.size': 20}) # 그래프에서 사용할 폰트 크기 설정
예시 3)
import numpy as np
import matplotlib.pyplot as plt
def imshow(input):
# torch.Tensor를 numpy 배열로 변환
input = input.numpy().transpose((1, 2, 0))
# PyTorch 텐서의 차원 순서를 (C, H, W)에서 (H, W, C)로 변경
# C: 채널, H: 높이, W: 너비
# 정규화 해제를 위한 평균(mean)과 표준편차(std) 값
mean = np.array([0.5, 0.5, 0.5]) # R, G, B 채널별 평균
std = np.array([0.5, 0.5, 0.5]) # R, G, B 채널별 표준편차
# 정규화 해제 (역정규화)
input = std * input + mean # 정규화된 데이터를 원래 범위로 되돌림
input = np.clip(input, 0, 1) # 값이 0보다 작으면 0, 1보다 크면 1로 제한
# 이미지를 출력
plt.imshow(input) # 이미지 데이터를 Matplotlib를 사용해 화면에 출력
plt.show() # 그래프 또는 이미지를 화면에 표시
예시 4)
from torchvision.utils import make_grid
# 클래스 이름 정의 (레이블에 해당하는 클래스 이름 매핑)
class_names = {
0: "Cloudy", # 레이블 0은 "Cloudy"
1: "Rain", # 레이블 1은 "Rain"
2: "Shine", # 레이블 2는 "Shine"
3: "Sunrise" # 레이블 3은 "Sunrise"
}
# 학습 데이터 로더의 반복자를 생성
iterator = iter(train_dataloader) # `train_dataloader`에서 데이터를 순차적으로 가져올 반복자 생성
imgs, labels = next(iterator) # 데이터의 첫 번째 배치를 가져옴 (이미지와 레이블 반환)
# 여러 이미지를 하나의 격자 형태로 합침
out = make_grid(imgs[:4]) # 배치의 첫 4개 이미지를 격자로 합침
# 이미지 출력
imshow(out) # 합쳐진 이미지를 화면에 출력--->

2. 다양한 모델 만들기
예시 1)
# 단일 선형 계층
# 활성화 함수나 추가 게층이 없으므로 모델이 표현할 수 있는 함수는 단순 선형 변환에 제한
# (256*256*3+1)*4 = 786.436
# 표현력 부족으로 복잡한 데이터(비선형)를 학습하지 못할 가능성이 높음
import torch.nn as nn
class Model1(nn.Module):
def __init__(self):
super(Model1, self).__init__()
# 단일 선형 계층을 정의합니다.
# 입력 크기: 256 * 256 * 3 (이미지의 크기: 256x256, 채널: 3)
# 출력 크기: 4 (모델이 출력하는 클래스 또는 값의 개수)
# 총 파라미터 수: (256 * 256 * 3 + 1) * 4 = 786,436
# 여기서 +1은 각 출력 뉴런에 대해 추가되는 바이어스(bias) 항입니다.
self.linear1 = nn.Linear(256 * 256 * 3, 4)
# 입력 이미지를 1차원 벡터로 평탄화(flatten)하기 위한 모듈입니다.
self.flatten = nn.Flatten()
def forward(self, x):
# 입력 이미지를 평탄화하여 선형 계층에 전달합니다.
x = self.flatten(x)
# 단일 선형 변환 수행 (활성화 함수 없음)
x = self.linear1(x)
return x
예시 2)
# 두 개의 선형 계층을 사용하여 입력 데이터를 단계적으로 압축
# 활성화 함수가 없으므로 각 계층 간 변환은 선형적
# (256*256*3+1)*64 + (64+1)*4 = 12,583,236
import torch.nn as nn
class Model2(nn.Module):
def __init__(self):
super(Model2, self).__init__()
# 첫 번째 선형 계층
# 입력 크기: 256 * 256 * 3 (이미지의 크기: 256x256, 채널: 3)
# 출력 크기: 64 (중간 계층의 출력 차원)
# 파라미터 수: (256 * 256 * 3 + 1) * 64 = 12,583,104 (가중치: 12,583,040, 바이어스: 64)
self.linear1 = nn.Linear(256 * 256 * 3, 64)
# 두 번째 선형 계층
# 입력 크기: 64 (이전 계층의 출력 차원)
# 출력 크기: 4 (모델의 최종 출력 클래스 또는 값의 개수)
# 파라미터 수: (64 + 1) * 4 = 260 (가중치: 256, 바이어스: 4)
self.linear2 = nn.Linear(64, 4)
# 입력 이미지를 1차원 벡터로 평탄화(flatten)하기 위한 모듈입니다.
self.flatten = nn.Flatten()
def forward(self, x):
# 입력 이미지를 평탄화하여 1차원 벡터로 변환
x = self.flatten(x)
# 첫 번째 선형 변환 (256*256*3 -> 64)
x = self.linear1(x)
# 두 번째 선형 변환 (64 -> 4)
x = self.linear2(x)
return x
예시 3)
# 다중 구조와 ReLu 활성화 함수를 사용하여 비선형적 특징을 학습할 수 있음
# Dropout을 통해 과적합을 방지
# (256*256*3+1)*128 + (128+1)*64 + (64+1)*32 + (32+1)*4 = 25176420
import torch.nn as nn
import torch.nn.functional as F
class Model3(nn.Module):
def __init__(self):
super(Model3, self).__init__()
# 첫 번째 선형 계층
# 입력 크기: 256 * 256 * 3 (이미지 크기: 256x256, 채널: 3)
# 출력 크기: 128
# 파라미터 수: (256*256*3 + 1) * 128 = 25,165,056 (가중치: 25,165,024, 바이어스: 128)
self.linear1 = nn.Linear(256 * 256 * 3, 128)
# Dropout: 50%의 뉴런을 무작위로 비활성화하여 과적합 방지
self.dropout1 = nn.Dropout(0.5)
# 두 번째 선형 계층
# 입력 크기: 128
# 출력 크기: 64
# 파라미터 수: (128 + 1) * 64 = 8,256 (가중치: 8,192, 바이어스: 64)
self.linear2 = nn.Linear(128, 64)
self.dropout2 = nn.Dropout(0.5)
# 세 번째 선형 계층
# 입력 크기: 64
# 출력 크기: 32
# 파라미터 수: (64 + 1) * 32 = 2,080 (가중치: 2,048, 바이어스: 32)
self.linear3 = nn.Linear(64, 32)
self.dropout3 = nn.Dropout(0.5)
# 네 번째 선형 계층
# 입력 크기: 32
# 출력 크기: 4 (모델의 최종 출력 클래스 또는 값의 개수)
# 파라미터 수: (32 + 1) * 4 = 132 (가중치: 128, 바이어스: 4)
self.linear4 = nn.Linear(32, 4)
# 입력 이미지를 1차원 벡터로 평탄화(flatten)하기 위한 모듈
self.flatten = nn.Flatten()
def forward(self, x):
# 입력 이미지를 평탄화하여 1차원 벡터로 변환
x = self.flatten(x)
# 첫 번째 계층: 256*256*3 -> 128 차원
x = F.relu(self.linear1(x)) # ReLU 활성화 함수로 비선형 변환
x = self.dropout1(x) # 과적합 방지를 위한 Dropout(50%)
# 두 번째 계층: 128 -> 64 차원
x = F.relu(self.linear2(x)) # ReLU 활성화 함수로 비선형 변환
x = self.dropout2(x) # 과적합 방지를 위한 Dropout(50%)
# 세 번째 계층: 64 -> 32 차원
x = F.relu(self.linear3(x)) # ReLU 활성화 함수로 비선형 변환
x = self.dropout3(x) # 과적합 방지를 위한 Dropout(50%)
# 네 번째 계층
Dropout
* nn.Dropout()은 PyTorch에서 제공하는 과적합(overfitting)을 방지하기 위한 레이어입니다.
* 드롭아웃은 학습 과정 중 일부 뉴런을 무작위로 "비활성화(drop)"함으로써, 모델이 특정 뉴런에 지나치게 의존하지 않도록 도와줍니다.
* 이를 통해 모델의 일반화 성능이 향상됩니다.
예시 1)
import time
import torch
def train():
# 학습 시작 시간을 기록합니다.
start_time = time.time()
# 현재 epoch의 학습을 시작한다고 출력합니다.
print(f'[Epoch: {epoch + 1} - Training]')
# 모델을 학습 모드로 전환
# 드롭아웃, 배치 정규화와 같은 학습 중에만 활성화되는 동작을 활성화
model.train()
# 학습 과정에서 사용할 변수 초기화
total = 0 # 총 학습 데이터의 개수
running_loss = 0.0 # 배치 단위로 누적된 손실 값
running_corrects = 0 # 배치 단위로 누적된 정확히 맞춘 예측 개수
# 학습 데이터로부터 배치(batch) 단위로 데이터를 가져옴
for i, batch in enumerate(train_dataloader):
imgs, labels = batch # 배치에서 이미지와 레이블(정답)을 분리
imgs, labels = imgs.cuda(), labels.cuda() # GPU에서 학습하도록 데이터를 전송
# 모델에 입력 이미지를 전달하여 예측값(outputs)을 얻음
outputs = model(imgs)
# 이전 단계에서 계산된 기울기를 초기화 (이전의 학습 정보를 제거)
optimizer.zero_grad()
# 로짓 값에서 최댓값의 인덱스를 사용하여 예측 클래스(preds)를 얻음
_, preds = torch.max(outputs, 1)
# 예측값(outputs)과 실제값(labels)을 사용하여 손실(loss)을 계산
loss = criterion(outputs, labels)
# 역전파(Backpropagation)를 수행하여 모델의 기울기(gradient)를 계산
loss.backward()
# 옵티마이저를 사용하여 모델의 가중치를 업데이트
optimizer.step()
# 배치 데이터 크기를 total에 더함 (전체 학습 데이터의 개수를 누적)
total += labels.shape[0]
# 현재 배치의 손실 값을 누적
running_loss += loss.item()
# 현재 배치에서 정확히 예측한 데이터 개수를 누적
running_corrects += torch.sum(preds == labels.data)
# 로그 출력: 일정한 간격(log_step)마다 현재 배치까지의 손실과 정확도를 출력
if (i == 0) or (i % log_step == log_step - 1):
print(f'[Batch: {i + 1}] running train loss: {running_loss / total}, running train accuracy: {running_corrects / total}')
# 전체 학습 데이터에 대한 평균 손실과 정확도를 출력
print(f'train loss: {running_loss / total}, accuracy: {running_corrects / total}')
# 학습에 걸린 시간 출력
print("elapsed time:", time.time() - start_time)
# 평균 손실과 정확도를 반환 (정확도는 tensor를 item()을 통해 숫자로 변환하여 반환)
return running_loss / total, (running_corrects / total).item()
예시 2)
import time
import torch
def validate():
# 검증 시작 시간을 기록합니다.
start_time = time.time()
# 현재 epoch의 검증을 시작한다고 출력합니다.
print(f'[Epoch: {epoch + 1} - Validation]')
# 모델을 평가 모드로 전환
# 드롭아웃과 배치 정규화가 비활성화되어 검증 데이터에 대해 일관된 결과를 제공
model.eval()
# 검증 과정에서 사용할 변수 초기화
total = 0 # 총 검증 데이터의 개수
running_loss = 0.0 # 배치 단위로 누적된 손실 값
running_corrects = 0 # 배치 단위로 누적된 정확히 맞춘 예측 개수
# 검증 데이터로부터 배치(batch) 단위로 데이터를 가져옴
for i, batch in enumerate(val_dataloader):
imgs, labels = batch # 배치에서 이미지와 레이블(정답)을 분리
imgs, labels = imgs.cuda(), labels.cuda() # GPU에서 검증하도록 데이터를 전송
# 검증 단계에서는 기울기를 계산하지 않도록 no_grad()로 감쌈
with torch.no_grad():
# 모델에 입력 이미지를 전달하여 예측값(outputs)을 얻음
outputs = model(imgs)
# 로짓 값에서 최댓값의 인덱스를 사용하여 예측 클래스(preds)를 얻음
_, preds = torch.max(outputs, 1)
# 예측값(outputs)과 실제값(labels)을 사용하여 손실(loss)을 계산
loss = criterion(outputs, labels)
# 배치 데이터 크기를 total에 더함 (전체 검증 데이터의 개수를 누적)
total += labels.shape[0]
# 현재 배치의 손실 값을 누적
running_loss += loss.item()
# 현재 배치에서 정확히 예측한 데이터 개수를 누적
running_corrects += torch.sum(preds == labels.data)
# 로그 출력: 일정한 간격(log_step)마다 현재 배치까지의 손실과 정확도를 출력
if (i == 0) or (i % log_step == log_step - 1):
print(f'[Batch: {i + 1}] running val loss: {running_loss / total}, running val accuracy: {running_corrects / total}')
# 전체 검증 데이터에 대한 평균 손실과 정확도를 출력
print(f'val loss: {running_loss / total}, accuracy: {running_corrects / total}')
# 검증에 걸린 시간 출력
print("elapsed time:", time.time() - start_time)
# 평균 손실과 정확도를 반환 (정확도는 tensor를 item()을 통해 숫자로 변환하여 반환)
return running_loss / total, (running_corrects / total).item()
예시 3)
import time
import torch
def test():
# 테스트 시작 시간을 기록합니다.
start_time = time.time()
# 테스트 과정을 시작한다고 출력합니다.
print(f'[Test]')
# 모델을 평가 모드로 전환
# 드롭아웃과 배치 정규화와 같은 학습 전용 동작이 비활성화됩니다.
model.eval()
# 테스트 과정에서 사용할 변수 초기화
total = 0 # 총 테스트 데이터의 개수
running_loss = 0.0 # 배치 단위로 누적된 손실 값
running_corrects = 0 # 배치 단위로 누적된 정확히 맞춘 예측 개수
# 테스트 데이터로부터 배치(batch) 단위로 데이터를 가져옴
for i, batch in enumerate(test_dataloader):
imgs, labels = batch # 배치에서 이미지와 레이블(정답)을 분리
imgs, labels = imgs.cuda(), labels.cuda() # GPU에서 테스트하도록 데이터를 전송
# 테스트 단계에서는 기울기를 계산하지 않도록 no_grad()로 감쌈
with torch.no_grad():
# 모델에 입력 이미지를 전달하여 예측값(outputs)을 얻음
outputs = model(imgs)
# 로짓 값에서 최댓값의 인덱스를 사용하여 예측 클래스(preds)를 얻음
_, preds = torch.max(outputs, 1)
# 예측값(outputs)과 실제값(labels)을 사용하여 손실(loss)을 계산
loss = criterion(outputs, labels)
# 배치 데이터 크기를 total에 더함 (전체 테스트 데이터의 개수를 누적)
total += labels.shape[0]
# 현재 배치의 손실 값을 누적
running_loss += loss.item()
# 현재 배치에서 정확히 예측한 데이터 개수를 누적
running_corrects += torch.sum(preds == labels.data)
# 로그 출력: 일정한 간격(log_step)마다 현재 배치까지의 손실과 정확도를 출력
if (i == 0) or (i % log_step == log_step - 1):
print(f'[Batch: {i + 1}] running test loss: {running_loss / total}, running test accuracy: {running_corrects / total}')
# 전체 테스트 데이터에 대한 평균 손실과 정확도를 출력
print(f'test loss: {running_loss / total}, accuracy: {running_corrects / total}')
# 테스트에 걸린 시간 출력
print("elapsed time:", time.time() - start_time)
# 평균 손실과 정확도를 반환 (정확도는 tensor를 item()을 통해 숫자로 변환하여 반환)
return running_loss / total, (running_corrects / total).item()
예시 4)
# 초기 학습률 설정
learning_rate = 0.01 # 모델 학습에 사용할 초기 학습률
# 로그 출력 주기
log_step = 11 # 학습 및 검증 과정에서 로그를 출력할 배치 간격
# 모델 초기화
model = Model1() # Model1 클래스의 인스턴스를 생성
model = model.cuda() # 모델을 GPU로 이동하여 연산 속도를 높임
# 손실 함수 정의
criterion = nn.CrossEntropyLoss()
# 다중 클래스 분류를 위한 손실 함수로, 모델 출력값(로짓)과 실제 레이블 간의 크로스 엔트로피 손실을 계산
# 옵티마이저 정의
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# Stochastic Gradient Descent(SGD)를 사용하여 모델의 가중치를 업데이트
# - 학습률(learning_rate): 0.01
# - 모멘텀(momentum): 0.9로 설정하여 경사 하강 시 관성을 부여하여 최적화 속도를 향상
# 학습 반복 수
num_epochs = 20 # 전체 데이터셋을 몇 번 반복할지 설정 (20번 학습)
# 최적의 성능 추적 변수
best_val_acc = 0 # 검증 정확도의 최고 값
best_epoch = 0 # 최고 정확도를 기록한 에포크 번호
# 학습 과정 기록
history = [] # 각 에포크별 손실 및 기타 메트릭 기록
accuracy = [] # 각 에포크별 정확도 기록
예시 5)
# 모델 가중치를 저장할 디렉토리 생성
os.makedirs("weights", exist_ok=True)
# "weights"라는 디렉토리를 생성. 이미 디렉토리가 존재하면 오류를 발생시키지 않음.
# 학습 반복
for epoch in range(num_epochs): # 지정된 에포크 수(num_epochs)만큼 반복
# 학습률 조정
adjust_learning_rate(optimizer, epoch)
# 현재 에포크 번호를 기준으로 학습률을 조정 (학습률 감소 전략 적용)
# 학습 단계 수행
train_loss, train_acc = train()
# train() 함수 호출: 현재 에포크에서 학습 데이터를 사용해 모델 학습
# train_loss: 학습 손실
# train_acc: 학습 정확도
# 검증 단계 수행
val_loss, val_acc = validate()
# validate() 함수 호출: 검증 데이터를 사용해 모델 평가
# val_loss: 검증 손실
# val_acc: 검증 정확도
# 손실과 정확도 기록
history.append((train_loss, val_loss))
# 학습 손실과 검증 손실을 history 리스트에 저장
accuracy.append((train_acc, val_acc))
# 학습 정확도와 검증 정확도를 accuracy 리스트에 저장
# 최상의 검증 정확도 갱신 및 모델 저장
if val_acc > best_val_acc:
# 현재 에포크의 검증 정확도가 최고 기록을 갱신했는지 확인
print('[Info] best validation accuracy!')
best_val_acc = val_acc # 최고 검증 정확도 갱신
best_epoch = epoch # 최고 검증 정확도를 기록한 에포크 갱신
# 최고 성능을 기록한 모델의 가중치를 저장
torch.save(model.state_dict(), f'weights/best_checkpoint_epoch_{epoch + 1}.pth')
# 마지막 에포크 모델 가중치 저장
torch.save(model.state_dict(), f'weights/last_checkpoint_epoch_{epoch + 1}.pth')
# 학습이 완료된 마지막 에포크의 모델 가중치를 저장
---->
val loss: 0.1489418003294203, accuracy: 0.7722222208976746
elapsed time: 0.9567720890045166
예시 6)
import matplotlib.pyplot as plt
# 학습 정확도와 검증 정확도를 시각화
plt.plot([x[0] for x in accuracy], 'b', label='train')
# 학습 정확도 데이터를 꺼내와 파란 실선으로 플롯
# x[0]: `accuracy` 리스트의 각 항목에서 학습 정확도(train accuracy) 추출
plt.plot([x[1] for x in accuracy], 'r--', label='validation')
# 검증 정확도 데이터를 꺼내와 빨간 점선으로 플롯
# x[1]: `accuracy` 리스트의 각 항목에서 검증 정확도(validation accuracy) 추출
plt.xlabel("Epochs")
# x축 레이블 설정: "Epochs" (에포크)
plt.ylabel("Accuracy")
# y축 레이블 설정: "Accuracy" (정확도)
plt.legend()
# 그래프에 범례 추가: 학습(train)과 검증(validation)의 플롯을 구분
--->
<matplotlib.legend.Legend at 0x7c6e41968730>---->
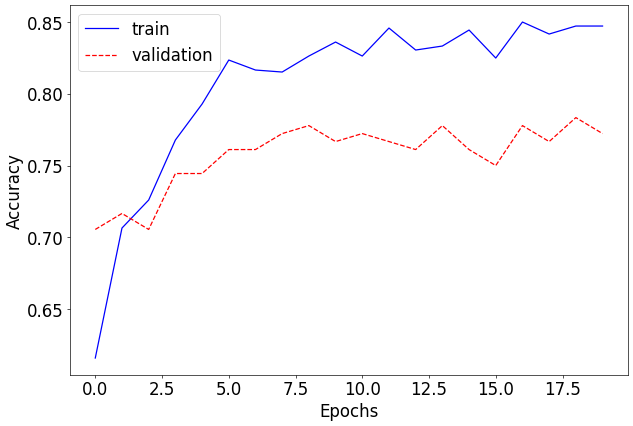
예제 7)
# 테스트 단계 실행
test_loss, test_accuracy = test()
# test() 함수 호출: 테스트 데이터를 사용하여 모델 평가
# - test_loss: 테스트 데이터에서의 평균 손실 값
# - test_accuracy: 테스트 데이터에서의 정확도 (0~1 범위의 값)
# 테스트 손실 출력
print(f"Test loss: {test_loss:.8f}")
# 테스트 손실 값을 소수점 이하 8자리까지 출력
# f-string 사용: `:.8f`는 실수를 소수점 이하 8자리까지 포맷
# 테스트 정확도 출력
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
# 테스트 정확도를 백분율로 변환하여 소수점 이하 2자리까지 출력
# `test_accuracy * 100.`: 정확도를 퍼센트 값으로 변환
# `:.2f`는 실수를 소수점 이하 2자리까지 포맷
--->
[Test]
[Batch: 1] running test loss: 0.24750888347625732, running test accuracy: 0.53125
test loss: 0.16398832017341547, accuracy: 0.7256637215614319
elapsed time: 2.115994691848755
Test loss: 0.16398832
Test accuracy: 72.57%
예제 8)
import os
import torch
import matplotlib.pyplot as plt
# 모델 가중치를 저장할 디렉토리 생성
os.makedirs("weights", exist_ok=True)
# "weights"라는 디렉토리를 생성. 디렉토리가 이미 존재하면 오류 없이 진행.
# 하이퍼파라미터 초기화
learning_rate = 0.01 # 초기 학습률
log_step = 20 # 로그 출력 주기
# 모델 정의 및 GPU로 이동
model = Model2() # Model2 클래스의 인스턴스를 생성
model = model.cuda() # 모델을 GPU로 이동하여 연산 속도를 높임
# 손실 함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
# 다중 클래스 분류를 위한 손실 함수 (크로스 엔트로피 손실)
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# SGD 옵티마이저 사용, 모멘텀 0.9로 경사 하강 속도 향상
# 학습 설정
num_epochs = 20 # 학습 반복 횟수
best_val_acc = 0 # 최고 검증 정확도
best_epoch = 0 # 최고 검증 정확도를 기록한 에포크
# 학습 기록 변수
history = [] # 손실 기록 (학습 및 검증)
accuracy = [] # 정확도 기록 (학습 및 검증)
# 학습 루프
for epoch in range(num_epochs): # 지정된 에포크 수만큼 반복
# 학습률 조정
adjust_learning_rate(optimizer, epoch)
# 학습 단계
train_loss, train_acc = train() # train() 함수 호출, 학습 손실과 정확도 반환
# 검증 단계
val_loss, val_acc = validate() # validate() 함수 호출, 검증 손실과 정확도 반환
# 손실 및 정확도 기록
history.append((train_loss, val_loss)) # (학습 손실, 검증 손실) 기록
accuracy.append((train_acc, val_acc)) # (학습 정확도, 검증 정확도) 기록
# 최고 검증 정확도 갱신 및 모델 저장
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc # 최고 검증 정확도 갱신
best_epoch = epoch # 최고 정확도를 기록한 에포크 저장
# 최고 성능 모델의 가중치를 저장
torch.save(model.state_dict(), f"weights/best_checkpoint_epoch_{epoch + 1}.pth")
# 마지막 에포크의 모델 가중치를 저장
torch.save(model.state_dict(), f"weights/last_checkpoint_epoch_{num_epochs}.pth")
# 정확도 그래프 그리기
plt.plot([x[0] for x in accuracy], 'b', label='train')
# 학습 정확도를 파란 실선으로 플롯
plt.plot([x[1] for x in accuracy], 'r--', label='validation')
# 검증 정확도를 빨간 점선으로 플롯
plt.xlabel("Epochs") # x축 레이블 설정: "Epochs"
plt.ylabel("Accuracy") # y축 레이블 설정: "Accuracy"
plt.legend() # 그래프에 범례 추가
# 테스트 단계
test_loss, test_accuracy = test() # test() 함수 호출, 테스트 손실과 정확도 반환
# 테스트 결과 출력
print(f"Test loss: {test_loss:.8f}")
# 테스트 손실 값을 소수점 8자리까지 출력
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
# 테스트 정확도를 백분율로 변환하여 소수점 2자리까지 출력
--->
test loss: 0.03125365553176509, accuracy: 0.7743362784385681
elapsed time: 1.3924012184143066
Test loss: 0.03125366
Test accuracy: 77.43%---->
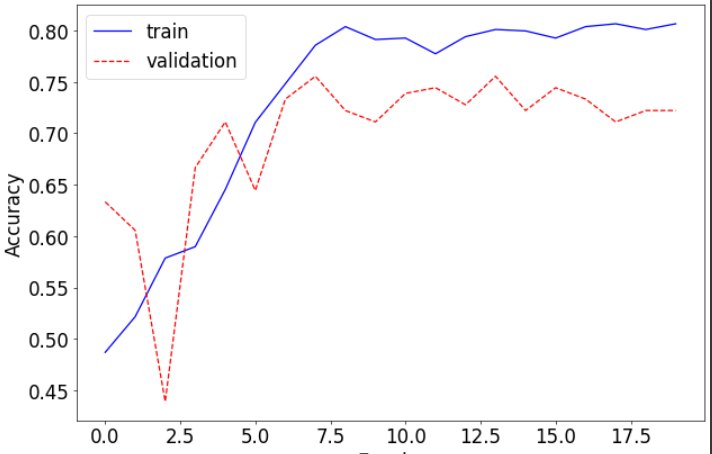
예제 9)
import os
import torch
import matplotlib.pyplot as plt
# 모델 가중치를 저장할 디렉토리 생성
os.makedirs("weights", exist_ok=True)
# "weights" 디렉토리를 생성. 이미 존재하면 오류 없이 진행됩니다.
# 학습 관련 하이퍼파라미터 초기화
learning_rate = 0.01 # 초기 학습률
log_step = 20 # 로그 출력 주기 (몇 배치마다 출력할지 설정)
# 모델 정의 및 GPU로 이동
model = Model3() # Model3 클래스의 인스턴스를 생성
model = model.cuda() # 모델을 GPU로 이동하여 연산 속도를 높임
# 손실 함수 및 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
# 크로스 엔트로피 손실: 다중 클래스 분류에 사용
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# SGD 옵티마이저: 학습률 0.01과 모멘텀 0.9로 설정
# 학습 설정
num_epochs = 20 # 학습 반복 횟수
best_val_acc = 0 # 최고 검증 정확도 초기값
best_epoch = 0 # 최고 검증 정확도를 기록한 에포크 초기값
# 학습 기록 저장 리스트
history = [] # 각 에포크에서의 손실 기록 (학습 손실, 검증 손실)
accuracy = [] # 각 에포크에서의 정확도 기록 (학습 정확도, 검증 정확도)
# 학습 루프
for epoch in range(num_epochs): # 총 num_epochs(20) 번 반복
# 학습률 조정
adjust_learning_rate(optimizer, epoch)
# 학습 단계
train_loss, train_acc = train() # train 함수 호출: 학습 손실 및 정확도 반환
# 검증 단계
val_loss, val_acc = validate() # validate 함수 호출: 검증 손실 및 정확도 반환
# 손실 및 정확도 기록
history.append((train_loss, val_loss)) # 학습 손실 및 검증 손실 저장
accuracy.append((train_acc, val_acc)) # 학습 정확도 및 검증 정확도 저장
# 최고 검증 정확도 갱신 시 체크포인트 저장
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc # 최고 검증 정확도 갱신
best_epoch = epoch # 최고 검증 정확도를 기록한 에포크 갱신
# 최고 성능 모델 가중치 저장
torch.save(model.state_dict(), f"weights/best_checkpoint_epoch_{epoch + 1}.pth")
# 마지막 에포크 모델 가중치 저장
torch.save(model.state_dict(), f"weights/last_checkpoint_epoch_{num_epochs}.pth")
# 정확도 그래프 시각화
plt.plot([x[0] for x in accuracy], 'b', label='train')
# 학습 정확도를 파란 실선으로 플롯
plt.plot([x[1] for x in accuracy], 'r--', label='validation')
# 검증 정확도를 빨간 점선으로 플롯
plt.xlabel("Epochs") # x축 레이블 설정
plt.ylabel("Accuracy") # y축 레이블 설정
plt.legend() # 그래프 범례 추가
# 테스트 단계
test_loss, test_accuracy = test() # 테스트 함수 호출: 손실 및 정확도 반환
# 테스트 결과 출력
print(f"Test loss: {test_loss:.8f}")
# 테스트 손실을 소수점 이하 8자리로 출력
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")
# 테스트 정확도를 백분율로 변환하여 소수점 2자리까지 출력
--->
test loss: 0.011558398999999055, accuracy: 0.7433628439903259
elapsed time: 1.422058343887329
Test loss: 0.01155840
Test accuracy: 74.34%---->
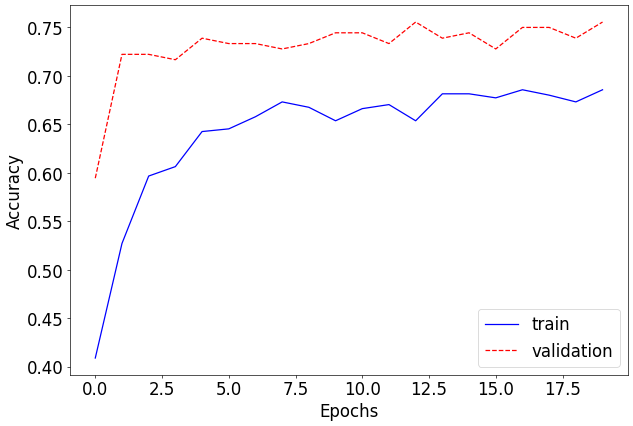
'LLM(Large Language Model)의 기초 > 딥러닝' 카테고리의 다른 글
| 5. 손글씨 도형 분류 FastAPI로 서빙 (2) | 2025.01.20 |
|---|---|
| 4. Alexnet 구현하기 (6) | 2025.01.20 |
| 4. 손글씨 도형 분류하기 (2) | 2025.01.16 |
| 3. CNN(Convolutional Neural Network, 합성곱 신경망) (2) | 2025.01.15 |
| 1. 딥러닝: 퍼셉트론과 다층 퍼셉트론 (2) | 2025.01.13 |