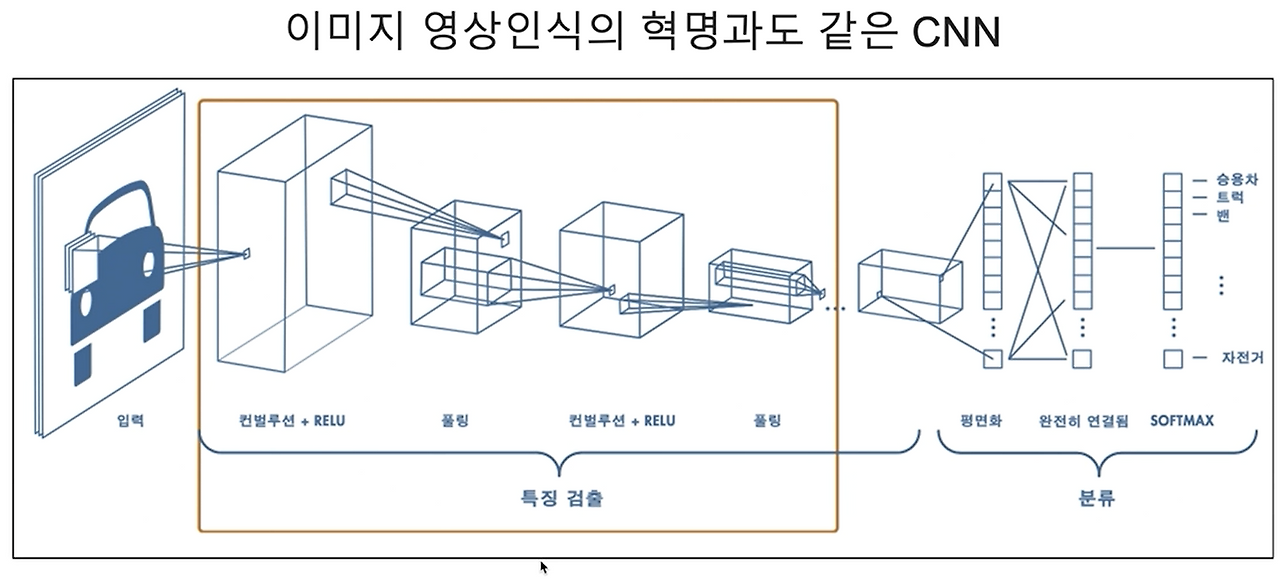
1.CNN* CNN(Convolutional Neural Network, 합성곱 신경망)은 주로 이미지나 비정형 데이터의 패턴을 학습하고 분석하는 데 사용되는 딥러닝 모델입니다. * CNN은 이미지의 공간적 구조를 효율적으로 처리하기 위해 합성곱 계층(convolutional layer)을 사용하며, 이 계층은 필터(커널)를 통해 입력 데이터에서 중요한 특징(에지, 모양 등)을 추출합니다. * 이어서 풀링 계층(pooling layer)을 통해 차원을 축소하고 계산 효율을 높이며, 마지막으로 완전 연결 계층(fully connected layer)을 사용해 특정 클래스나 값을 예측합니다. * CNN은 이미지 분류, 객체 탐지, 영상 처리 등 다양한 분야에서 높은 성능을 발휘하며, 이미지의 공간적 관계를 ..