1. 네이버 쇼핑의 긍정, 부정 RNN 활용
네이버 쇼핑의 후기 RNN 활용에 대해서 알아보겠습니다.
* https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt 데이터 로드
* 긍정, 부정 라벨링 (3점을 제거, 1, 2점(부정), 4, 5(긍정))
* 임베딩
* 데이터셋 만들기
* 데이터로더 만들기
* 간단한 RNN 모델 만들기
* 학습 후 테스트
* "이 제품 정말 좋아요! 추천합니다." (긍정)
예시 1)
* https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt
# 필요한 프로그램들 설치
!pip install konlpy
!pip install mecab-python
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
예시 2)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import numpy as np
import re
from konlpy.tag import Mecab
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
예시 3)
# url을 불러와 rating, review로 data 만듦
url = 'https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt'
data = pd.read_table(url, names=['rating', 'review'])
data--->

예시 4)
# 3 점 리뷰 제거 긍정(1), 부정(0) 라벨링
data = data[data['rating'] != 3] # 3 점 리뷰 제거
# 평점이 4 또는 5인 경우 긍정 리뷰(1)로, 평점이 1 또는 2인 경우 부정 리뷰(0)로 라벨링
data['label'] = np.where(data['rating'] > 3, 1, 0)
예시 5)
import re # 정규 표현식 사용을 위한 re import
def preprocess_text(text):
# 한글(가-힣)과 공백(\s)을 제외한 모든 문자를 공백(' ')으로 변환
text = re.sub(r'[^가-힣\s]', ' ', text)
return text
예시 6)
# 데이터프레임 'review' 열에 preprocess_text 함수를 적용하여 전처리 수행
data['review'] = data['review'].apply(preprocess_text)
예시 7)
from konlpy.tag import Mecab # 한국어 형태소 분석기 Mecab을 불러옴
# Mecab 객체 생성 (형태소 분석기 초기화)
mecab = Mecab()
# 불용어(Stopwords) 설정: 분석에서 삭제할 조사 및 단어들
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를']
# 텍스트를 형태소 단위로 토큰화하는 함수
def tokenize(text):
# Mecab을 이용해 입력된 텍스트를 형태소 단위로 분리
tokens = mecab.morphs(text)
# 불용어(stopwords)에 해당하지 않는 단어들만 필터링하여 반환
return [token for token in tokens if token not in stopwords]
예시 8)
# 'review' 열의 각 텍스트에 대해 tokenize 함수를 적용하여 토큰화된 결과를 'tokenized' 열에 저장
data['tokenized'] = data['review'].apply(tokenize)
예시 9)
from collections import Counter # 단어 빈도수를 세기 위한 Counter 모듈 임포트
# 'tokenized' 열에서 모든 리뷰의 토큰을 하나의 리스트로 합침
all_tokens = [token for tokens in data['tokenized'] for token in tokens]
# 단어별 등장 횟수를 세어 사전(vocab) 생성
vocab = Counter(all_tokens)
# 전체 고유 단어 개수 출력
len(vocab)
-->
40334
예시 10)
# 전체 고유 단어 개수(vocab) + 패딩(PAD)과 OOV(Out-Of-Vocabulary) 토큰을 추가
vocab_size = len(vocab) + 2 # PAD(0), OOV(1) 토큰 포함
예시 11)
# 단어 사전을 정수 인덱스로 매핑
word_to_index = {word: idx + 2 for idx, (word, _) in enumerate(vocab.most_common())}
# 패딩(PAD)과 OOV(Out-Of-Vocabulary) 토큰 추가
word_to_index['<PAD>'] = 0 # 패딩(PAD) 토큰은 0번 인덱스
word_to_index['<OOV>'] = 1 # 미등록 단어(OOV) 토큰은 1번 인덱스
예시 12)
# 입력된 토큰 리스트를 정수 인덱스 리스트로 변환하는 함수
# 단어가 word_to_index 사전에 존재하면 해당 인덱스를 반환
def encode_tokens(tokens):
return [word_to_index.get(token, 1) for token in tokens] # 존재하지 않는 단어는 <OOV>(1)로 처리
예시 13)
# 'tokenized' 열에 대해 encode_tokens 함수를 적용하여 정수 인코딩된 결과를 'encoded' 열에 저장
data['encoded'] = data['tokenized'].apply(encode_tokens)
예시 14)
data[:3] # 첫 3개 data 출력--->

예시 15)
# 최대 길이 설정
max_len = 100
# 패딩 적용 함수 정의
# 입력된 정수 인코딩된 시퀀스를 max_len 길이로 패딩하는 함수
# max_len보다 길면 자름 (truncation)
# # max_len보다 짧으면 0으로 채움
def pad_sequence(seq, max_len):
return seq[:max_len] + [0] * (max_len - len(seq))
예시 16)
# 'encoded' 열의 각 리스트(정수 인코딩된 리뷰)에 대해 pad_sequence 함수를 적용하여 패딩된 결과를 'padded' 열에 저장
data['padded'] = data['encoded'].apply(lambda x: pad_sequence(x, max_len))
예시 17)
import torch
from torch.utils.data import Dataset
# PyTorch Dataset 클래스: 리뷰 데이터를 텐서로 변환하여 데이터 로더에서 사용 가능하도록 함
class ReviewDataset(Dataset):
def __init__(self, reviews, labels):
# 리뷰 데이터를 PyTorch Tensor로 변환 (정수형 long 타입)
self.reviews = torch.tensor(reviews, dtype=torch.long)
# 라벨 데이터를 PyTorch Tensor로 변환 (실수형 float 타입, Binary Classification 대비)
self.labels = torch.tensor(labels, dtype=torch.float)
def __len__(self):
# 데이터셋의 총 샘플 수 반환
return len(self.reviews)
def __getitem__(self, idx):
# 주어진 인덱스 idx에 해당하는 샘플(리뷰, 라벨) 반환
return self.reviews[idx], self.labels[idx]
예시 18)
from sklearn.model_selection import train_test_split
# 데이터셋을 훈련(Train)과 테스트(Test) 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(
data['padded'].tolist(), # 패딩된 정수 인코딩 리뷰 데이터
data['label'].tolist(), # 감성 라벨 (긍정=1, 부정=0)
test_size=0.2, # 전체 데이터 중 20%를 테스트 세트로 분리
random_state=2025 # 재현 가능성을 위해 랜덤 시드 설정
)
# 훈련 및 테스트 데이터 개수 출력
print(len(X_train), len(X_test)) # 훈련 데이터 개수, 테스트 데이터 개수
print(len(y_train), len(y_test)) # 훈련 라벨 개수, 테스트 라벨 개수
--->
160000 40000
160000 40000
예시 19)
from torch.utils.data import DataLoader
# 배치 크기 설정
batch_size = 64
# PyTorch Dataset 객체 생성 (훈련 데이터 & 테스트 데이터)
train_dataset = ReviewDataset(X_train, y_train)
test_dataset = ReviewDataset(X_test, y_test)
# DataLoader 생성 (배치 단위로 데이터를 제공)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 훈련 데이터는 랜덤 셔플 적용
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 테스트 데이터는 랜덤 셔플 없음
예시 20)
import torch
import torch.nn as nn
# RNN 기반 감성 분석 모델
# output_dim: 최종 출력 차원 (이진 분류라면 1)
class SetimentRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(SetimentRNN, self).__init__()
# 임베딩 레이어: 입력 정수 인덱스를 밀집 벡터로 변환
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
# RNN 레이어: 순환 신경망 (Recurrent Neural Network)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
# 출력층 (fully connected layer): 최종 예측값 출력
self.fc = nn.Linear(hidden_dim, output_dim)
# 순전파(FORWARD) 연산 수행
def forward(self, text):
# 입력 정수 인덱스를 밀집 벡터로 변환
embedded = self.embedding(text)
# RNN 레이어를 통해 은닉 상태 계산
rnn_out, _ = self.rnn(embedded) # (batch_size, seq_len, hidden_dim)
# 타임스텝의 출력을 선택하여 fully connected layer에 전달
out = self.fc(rnn_out[:, -1, :]) # (batch_size, hidden_dim) -> (batch_size, output_dim)
return out
예제 21)
embedding_dim = 128 # 임베딩 차원
hidden_dim = 256 # RNN 은닉 상태 크기
output_dim = 1 # 이진 분류
예제 22)
import torch
# GPU 사용 가능 여부 확인 후, 사용 가능한 디바이스 선택
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 모델 초기화 (RNN 기반 감성 분석 모델)
model = SetimentRNN(vocab_size, embedding_dim, hidden_dim, output_dim)
# 모델을 선택한 디바이스(GPU 또는 CPU)로 이동
model.to(device)
--->
SetimentRNN(
(embedding): Embedding(40336, 128, padding_idx=0)
(rnn): RNN(128, 256, batch_first=True)
(fc): Linear(in_features=256, out_features=1, bias=True)
)
예제 23)
# Weight Decay(가중치 감쇠): 과적합을 방지하기 위해 가중치 값을 줄이는 기법, 모델이 큰 가중치를
#학습하지 않도록 제한하여 일반화 성능을 높임
# Adam : Weight Decay가 L2 정규화 방식으로 적용, 손실 함수에 추가적인 term으로 더해지는 방식(DNN, CNN)
# AdamW : Weight Decay가 손실 함수에 영향을 주지 않도록 적용(BERT, GPT, Transfer)
import torch.nn as nn
import torch.optim as optim
# 손실 함수: 이진 분류(Binary Classification)에서 사용되는 BCEWithLogitsLoss
criterion = nn.BCEWithLogitsLoss()
# 옵티마이저: Adam 사용 (기본적으로 L2 정규화 방식으로 Weight Decay 적용)
optimizer = optim.Adam(model.parameters(), lr=0.001)
예제 24)
import torch
# criterion: 손실 함수
# n_epochs: 총 학습 epoch 수
# 모델 학습을 수행하는 함수
def train_model(model, train_loader, criterion, optimizer, n_epochs):
model.train() # 모델을 학습 모드로 설정 (Dropout, BatchNorm 활성화)
for epoch in range(n_epochs):
epoch_loss = 0 # 한 epoch 동안의 총 손실 초기화
correct = 0 # 정확하게 예측한 샘플 수
total = 0 # 전체 샘플 수
for reviews, labels in train_loader:
# 데이터를 GPU 또는 CPU로 이동
reviews, labels = reviews.to(device), labels.to(device)
# 1. 기존 기울기(gradient) 초기화
optimizer.zero_grad()
# 2. 모델 예측 (logits 반환)
predictions = model(reviews).squeeze() # (batch_size, 1) → (batch_size,)
# 3. 손실 함수 계산
loss = criterion(predictions, labels)
# 4. 역전파 (Backpropagation)
loss.backward()
# 5. 가중치 업데이트 (Optimizer Step)
optimizer.step()
# 6. 손실 및 정확도 계산
epoch_loss += loss.item() # 배치 손실을 누적
preds = (torch.sigmoid(predictions) >= 0.5).float() # 0.5 기준으로 이진 분류
correct += (preds == labels).sum().item() # 올바르게 분류된 샘플 개수
total += labels.size(0) # 전체 샘플 개수
# 한 epoch 동안의 평균 손실 및 정확도 계산
epoch_acc = correct / total
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {epoch_loss/len(train_loader):.4f}, Accuracy: {epoch_acc:.4f}')
예시 25)
# 모델 학습 실행
n_epochs = 5
train_model(model, train_dataloader, criterion, optimizer, n_epochs)
예시 26)
import torch
# 입력된 문장의 감성을 예측하는 함수(긍정 / 부정)
def predict_sentiment(model, sentence):
model.eval() # 모델을 평가 모드로 설정 (Dropout, BatchNorm 비활성화)
# 문장을 형태소 단위로 토큰화
tokens = tokenize(sentence)
# 토큰을 정수 인코딩
encoded = encode_tokens(tokens)
# 패딩 적용 (max_len 길이로 맞춤)
padded = pad_sequence(encoded, max_len)
# PyTorch Tensor로 변환 후, GPU 또는 CPU로 이동
input_tensor = torch.tensor([padded], dtype=torch.long).to(device) # (1, max_len)
# 모델 예측 (with torch.no_grad() 사용하여 그래디언트 계산 방지)
with torch.no_grad():
prediction = model(input_tensor).item() # 모델 예측값 (logits)
probability = torch.sigmoid(torch.tensor(prediction)).item() # 시그모이드 적용 (0~1 확률 변환)
# 감성 분석 결과 해석 (0.5 이상이면 긍정, 아니면 부정)
sentiment = '긍정' if probability >= 0.5 else '부정'
# 결과 출력
print(f'입력 문장: {sentence}')
print(f'예측 확률: {probability:.4f} ({sentiment})')
예시 27)
test_sentences = [
"이 제품 정말 좋아요! 추천합니다.",
"완전 별로예요. 사지 마세요.",
"기대 이하입니다. 실망했어요."
]
# 감성 분석 실행
for sentence in test_sentences:
predict_sentiment(model, sentence)
--->
입력 문장: 이 제품 정말 좋아요! 추천합니다.
예측 확률: 0.5127 (긍정)
입력 문장: 완전 별로예요. 사지 마세요.
예측 확률: 0.5127 (긍정)
입력 문장: 기대 이하입니다. 실망했어요.
예측 확률: 0.5127 (긍정)
2.RNN을 이용한 KOSPI 예측
# 자료 다운
https://blog.kakaocdn.net/dn/WYCIu/btsMbaCSViG/7HR8IAdVkWJRk3X0Gb4u9K/kospi.csv?attach=1&knm=tfile.csv-->
예시 1)
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import TensorDataset, DataLoader
예시 2)
import pandas as pd
# utf-8 처리
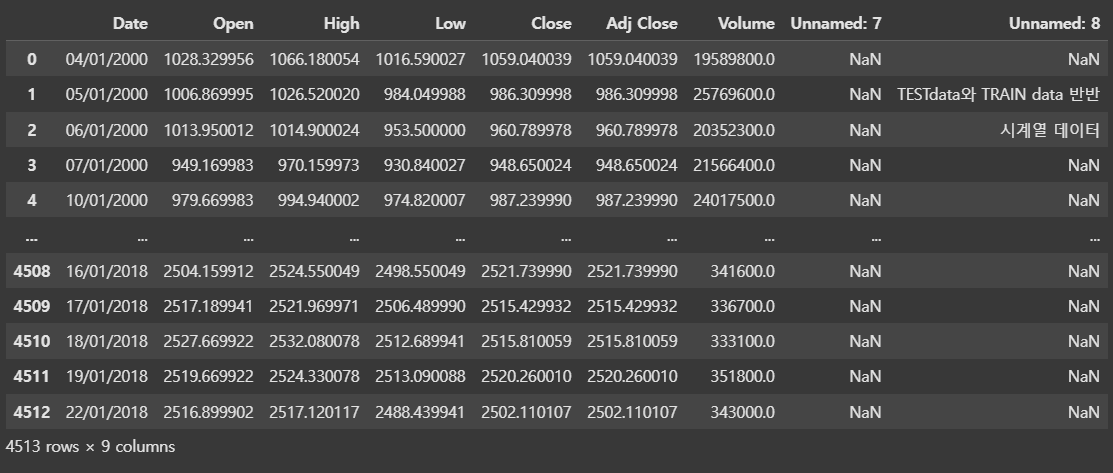
df_kospi = pd.read_csv('/content/drive/MyDrive/data/kospi.csv', encoding='cp949')
df_kospi--->
예시 3)
# 결측값 확인
print(df_kospi.isnull().sum())
--->
Date 0
Open 0
High 0
Low 0
Close 0
Adj Close 0
Volume 0
Unnamed: 7 4513
Unnamed: 8 4510
dtype: int64
예시 4)
# 결측값을 이전 값으로 채우기
df_kospi = df_kospi.bfill()
print(df_kospi.isnull().sum())
-->
Date 0
Open 0
High 0
Low 0
Close 0
Adj Close 0
Volume 0
Unnamed: 7 4513
Unnamed: 8 4510
dtype: int64
예시 5)
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
scaler = MinMaxScaler()
# 숫자형 데이터만 선택
numeric_cols = df_kospi.select_dtypes(include=['number']).columns
# MinMaxScaler 적용
df_kospi[numeric_cols] = scaler.fit_transform(df_kospi[numeric_cols])
df_kospi.head(5)--->

예시 6)
# 특징(feature) 데이터 설정 (Open, High, Low, Close)
X = df_kospi[['Open', 'High', 'Low', 'Close']].values # (샘플 개수, 4)
# 타겟(target) 데이터 설정 (종가)
y = df_kospi['Close'].values # (샘플 개수,)
# X와 y의 데이터 길이 출력
len(X), len(y)
-->
(4513, 4513)
예시 7)
import torch
# 시계열 데이터를 학습할 수 있도록 sequence(시퀀스) 형태로 변환하는 함수
# X: 독립 변수 (특징 데이터) - numpy 배열 또는 리스트
# y: 종속 변수 (타겟 데이터) - numpy 배열 또는 리스트
# sequence_size: 시퀀스 길이 (이전 데이터 몇 개를 사용할지)
def sequence_data(X, y, sequence_size):
X_seq = [] # 입력 데이터 시퀀스
y_seq = [] # 출력 데이터 (타겟 값)
# 전체 데이터에서 sequence_size 만큼의 구간을 만들면서 데이터 생성
for idx in range(len(X) - sequence_size):
X_seq.append(X[idx:idx + sequence_size]) # sequence_size 길이만큼 입력 데이터 생성
y_seq.append(y[idx + sequence_size]) # 해당 구간 다음 값(타겟) 저장
# PyTorch 텐서로 변환
return torch.tensor(X_seq, dtype=torch.float32), torch.tensor(y_seq, dtype=torch.float32).view(-1, 1)
예시 8)
# 데이터 분할을 위한 설정
split = 2257 # 전체 데이터의 절반을 훈련 데이터로 사용
sequence_length = 5 # 하나의 입력 시퀀스 길이 설정
# 시퀀스 데이터 생성
X_seq, y_seq = sequence_data(X, y, sequence_length)
# 훈련 데이터 (Training Set)
X_train_seq = X_seq[:split] # 처음부터 split 인덱스까지를 훈련 데이터로 사용
y_train_seq = y_seq[:split] # 타겟 데이터도 동일하게 분할
# 테스트 데이터 (Test Set)
X_test_seq = X_seq[split:] # split 이후의 데이터를 테스트 데이터로 사용
y_test_seq = y_seq[split:] # 타겟 데이터도 동일하게 분할
예시 9)
len(X_train_seq), len(y_train_seq)
--->
(2257, 2257)
예시 10)
len(X_test_seq), len(y_test_seq)
-->
(2251, 2251)
예시 11)
from torch.utils.data import TensorDataset, DataLoader
# PyTorch TensorDataset을 사용하여 훈련 및 테스트 데이터셋 생성
train_set = TensorDataset(X_train_seq, y_train_seq)
test_set = TensorDataset(X_test_seq, y_test_seq)
# DataLoader 생성 (배치 크기: 16)
train_loader = DataLoader(train_set, batch_size=16, shuffle=True) # 훈련 데이터는 섞음
test_loader = DataLoader(test_set, batch_size=16, shuffle=False) # 테스트 데이터는 섞지 않음
예시 12)
# X_seq.size(): [batch_size, sequence_length, feature_size]
# size(2): feature_size
input_size = X_seq.size(2)
num_layers = 2
hidden_size = 8
print(input_size)
-->
4
예시 13)
import torch
import torch.nn as nn
# 기본 순환 신경망(RNN) 모델을 사용한 감성 분석 또는 시계열 예측 모델.
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(RNN, self).__init__()
self.input_size = input_size # 입력 특징 개수(입력 크기)
self.hidden_size = hidden_size # 은닉 상태 차원(RNN 은닉 상태 크기)
self.num_layers = num_layers # RNN 레이어 개수
self.sequence_length = sequence_length # 시퀀스 길이
self.device = device # 연산을 수행할 장치
# RNN 레이어 정의
self.rnn = nn.RNN(
input_size, hidden_size, num_layers, batch_first=True
).to(self.device)
# 완전 연결층(FC) 정의
self.fc = nn.Sequential(
nn.Linear(self.hidden_size * self.sequence_length, 1), # 최종 출력 차원 1 (회귀 또는 이진 분류)
nn.Sigmoid() # 이진 분류를 위한 활성화 함수 (회귀 모델일 경우 제거 가능)
)
# 순전파 (Forward) 연산
# x: 입력 데이터 (배치 크기, 시퀀스 길이, 특징 개수)
def forward(self, x):
# 초기 은닉 상태 h0 생성 (num_layers, batch_size, hidden_size) → 0으로 초기화
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)
# RNN 실행 (입력 x와 초기 은닉 상태 h0)
out, _ = self.rnn(x, h0)
# 출력을 평탄화 (batch_size, sequence_length * hidden_size)
out = out.reshape(out.shape[0], -1)
# 완전 연결층 적용
out = self.fc(out)
return out
예시 14)
import torch
# GPU 또는 CPU 자동 선택
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# RNN 모델 초기화 및 GPU/CPU로 이동
model = RNN(input_size, hidden_size, 5, num_layers, device).to(device)
예시 15)
import torch.nn as nn
import torch.optim as optim
# 손실 함수 (Mean Squared Error, MSE)
criterion = nn.MSELoss()
# 옵티마이저 (Adam + 학습률 설정)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
예시 16)
import matplotlib.pyplot as plt
# 손실 값 저장 리스트
loss_graph = []
# 데이터 로더 크기 확인
n = len(train_loader) # 배치 개수
epochs = 500 # 학습 반복 횟수
예시 17)
for epoch in range(epochs): # 500번의 학습 반복
running_loss = 0. # 한 epoch 동안의 손실 초기화
# 배치 단위 학습
for data in train_loader:
seq, target = data[0].to(device), data[1].to(device) # 데이터를 GPU로 이동
out = model(seq) # 모델 예측
loss = criterion(out, target) # 손실 함수 계산
optimizer.zero_grad() # 기존 기울기 초기화
loss.backward() # 역전파 수행
optimizer.step() # 가중치 업데이트
running_loss += loss.item() # 배치 손실 누적
# 한 epoch의 평균 손실 값을 저장
loss_graph.append(running_loss / n)
# 100 epoch마다 현재 손실 값 출력
if epoch % 100 == 0:
print("[Epoch: %d] loss : %.6f" % (epoch, running_loss / n))
-->
[Epoch: 0] loss : 0.036128
[Epoch: 100] loss : 0.000114
[Epoch: 200] loss : 0.000099
[Epoch: 300] loss : 0.000098
[Epoch: 400] loss : 0.000088
예제 18)
import matplotlib.pyplot as plt
# 그래프 크기 설정 (20x10)
plt.figure(figsize=(20, 10))
# 손실 값(loss_graph) 플로팅
plt.plot(loss_graph, label="Training Loss", color='blue', linewidth=2)
# 그래프 제목 및 축 레이블 설정
plt.xlabel("Epochs", fontsize=16)
plt.ylabel("Loss", fontsize=16)
plt.title("Training Loss Over Epochs", fontsize=20)
# 범례 표시
plt.legend()
# 그래프 출력
plt.show()--->

예제 19)
import torch
from torch.utils.data import ConcatDataset, DataLoader
# 훈련 데이터셋 + 테스트 데이터셋 결합
concatdata = ConcatDataset([train_set, test_set])
# 배치 크기 16으로 데이터 로더 생성
data_loader = DataLoader(dataset=concatdata, batch_size=16)
# 모델 평가 모드 설정 (Dropout, BatchNorm 비활성화)
model.eval()
# 예측 결과 저장 리스트
with torch.no_grad(): # 그래디언트 계산 방지
pred = []
for data in data_loader:
seq, target = data[0].to(device), data[1].to(device) # 데이터 GPU로 이동
out = model(seq) # 모델 예측
pred += out.cpu().tolist() # 예측 결과를 리스트에 저장
예제 20)
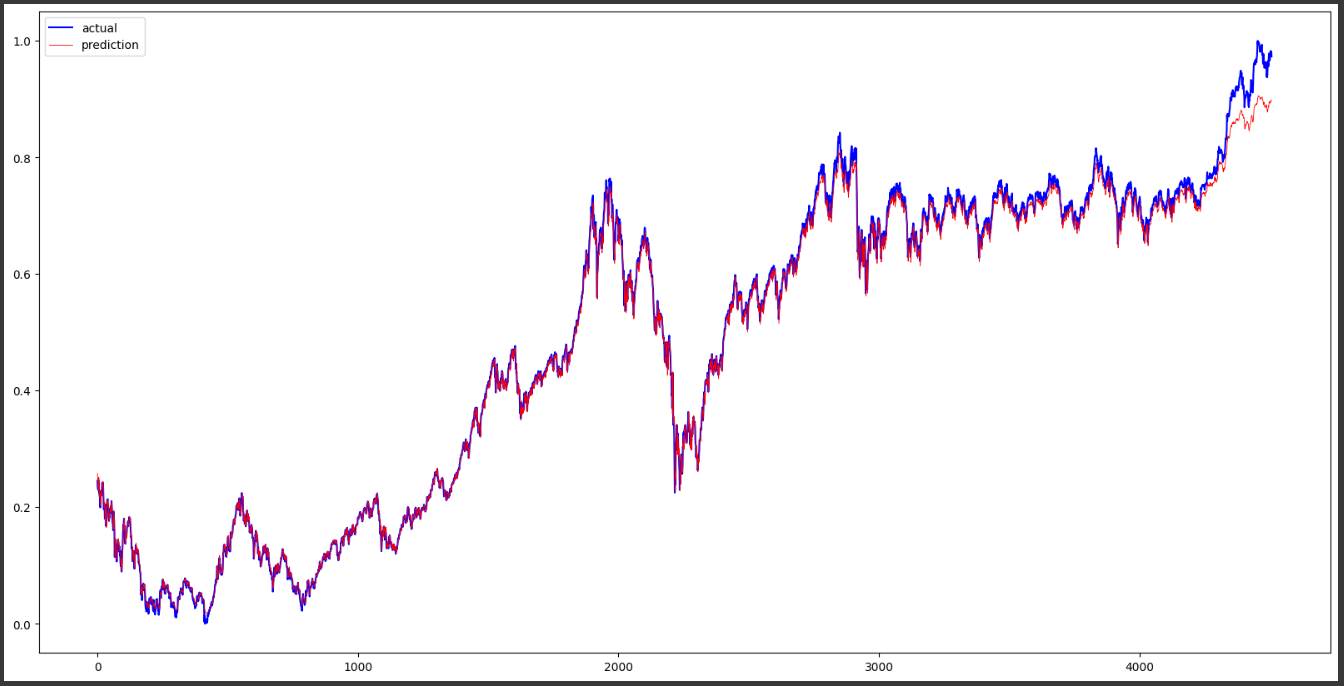
import matplotlib.pyplot as plt
# 그래프 크기 설정 (20x10 인치)
plt.figure(figsize=(20, 10))
# 실제 KOSPI 종가 (sequence_length 이후 데이터만 시각화)
plt.plot(df_kospi['Close'][sequence_length:].values, 'b')
# 모델 예측값 (빨간색, 선 굵기 0.6)
plt.plot(pred, 'r', linewidth=0.6)
# 범례 추가 (파란색: 실제값, 빨간색: 예측값)
plt.legend(['actual', 'prediction'])
# 그래프 출력
plt.show()---->
728x90
LIST
'자연어 처리 > 자연어 처리' 카테고리의 다른 글
| 8. Seq2Seq (0) | 2025.02.11 |
|---|---|
| 7. LSTM과 GRU (0) | 2025.02.10 |
| 6. RNN(Recurrent Neural Network, RNN) (0) | 2025.02.06 |
| 5. CNN Text Classification (0) | 2025.02.06 |
| 4. 신경망 기반의 벡터화 (4) | 2025.02.05 |