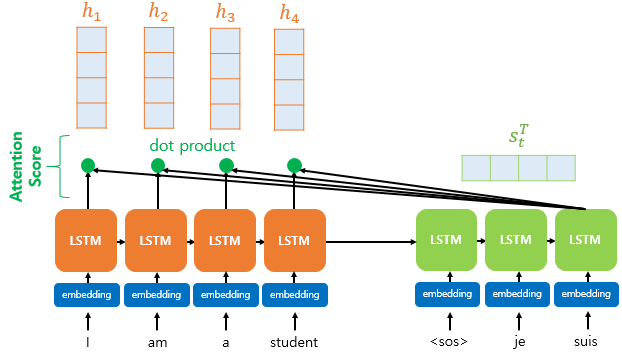
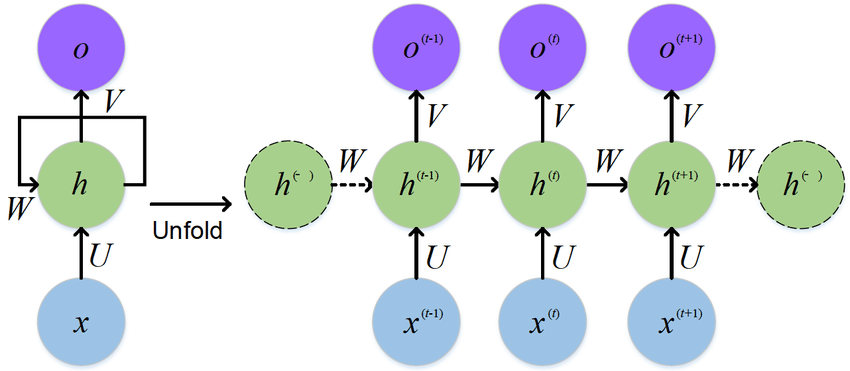
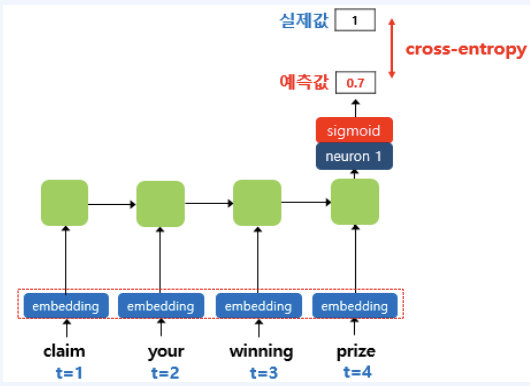
1. PML* PLM(Pre-trained Language Model)은 대량의 텍스트 데이터를 사전 학습하여 자연어 이해와 생성 능력을 갖춘 인공지능 모델입니다. * 대표적으로 BERT, GPT, T5 등이 있으며, 이들은 대규모 데이터에서 단어의 의미와 문맥을 학습한 후, 특정 작업(예: 문장 분류, 번역, 질의응답 등)에 맞게 추가 학습(Fine-tuning)하여 활용됩니다. * PLM은 문맥을 고려한 자연어 처리 능력이 뛰어나며, 다양한 언어 기반 AI 애플리케이션에서 핵심 기술로 사용됩니다. 1-1. BERT(Bidirectional Encoder Representations from Transformers)* BERT(Bidirectional Encoder Representations fro..